
不同行业产生的图数据往往具有天然的差异化特性,这使得图神经网络模型的学习和应用面临着更为严峻的多域、多任务泛化挑战。
目前在图学习领域,“预训练 + 下游微调”已成为主流范式。研究者通常会先在大规模图数据上进行自监督预训练,得到一个通用基础模型,随后再针对不同的下游任务分别进行微调。这种策略在分子性质预测等图学习任务中已被证明行之有效。
但随之而来的是一个现实且棘手的问题:如果我们需要同时处理多个下游任务,是否就必须为每个任务单独保存和维护一个完整的微调模型?
例如在分子性质预测场景中,Tox21、SIDER、ClinTox、HIV 等众多数据集各自关注不同的分子属性。为每个任务独立微调一个模型固然能获得不错的效果,但在实际部署时,需要维护多个模型副本,会带来高昂的存储成本和计算负担。因此,业界一直希望探索能否构建一个统一的模型,使其能够同时处理多个不同的任务。
“模型融合(Model Merging)”为此提供了一种极具潜力的解决思路。这种方法旨在直接融合多个已微调模型的参数,快速构建出一个统一的多任务模型,而无需从头开始进行复杂的联合训练。在计算机视觉和自然语言处理领域,模型融合已经得到了充分研究,从最初简单的参数平均,到后来调整合并权重、引入额外可训练模块等更先进的方法,都在提升下游任务表现方面取得了显著成果。
然而,图数据与图像、文本数据存在本质不同。图具有天然的结构异质性,即不同数据集的图拓扑结构分布差异可能非常显著。因此,直接将适用于CV/NLP的简单参数平均方法应用于图神经网络,往往会导致模型性能出现断崖式下跌。
那么,图神经网络是否也能实现高质量的模型融合?来自大湾区大学、深圳大学、威斯康星大学麦迪逊分校等机构的研究者们给出了肯定的答案。

论文标题:G-Merging: Graph Model Merging for Parameter-Efficient Multi-Task Knowledge Consolidation
收录会议:ICLR 2026
论文链接:https://openreview.net/forum?id=FoTtvLkkfU
代码链接:https://github.com/cjcj46262/G-Merging

方法框架
针对图数据结构的特殊性,研究团队提出了 G-Merging,这是一个专门为图神经网络设计的多任务模型融合框架。
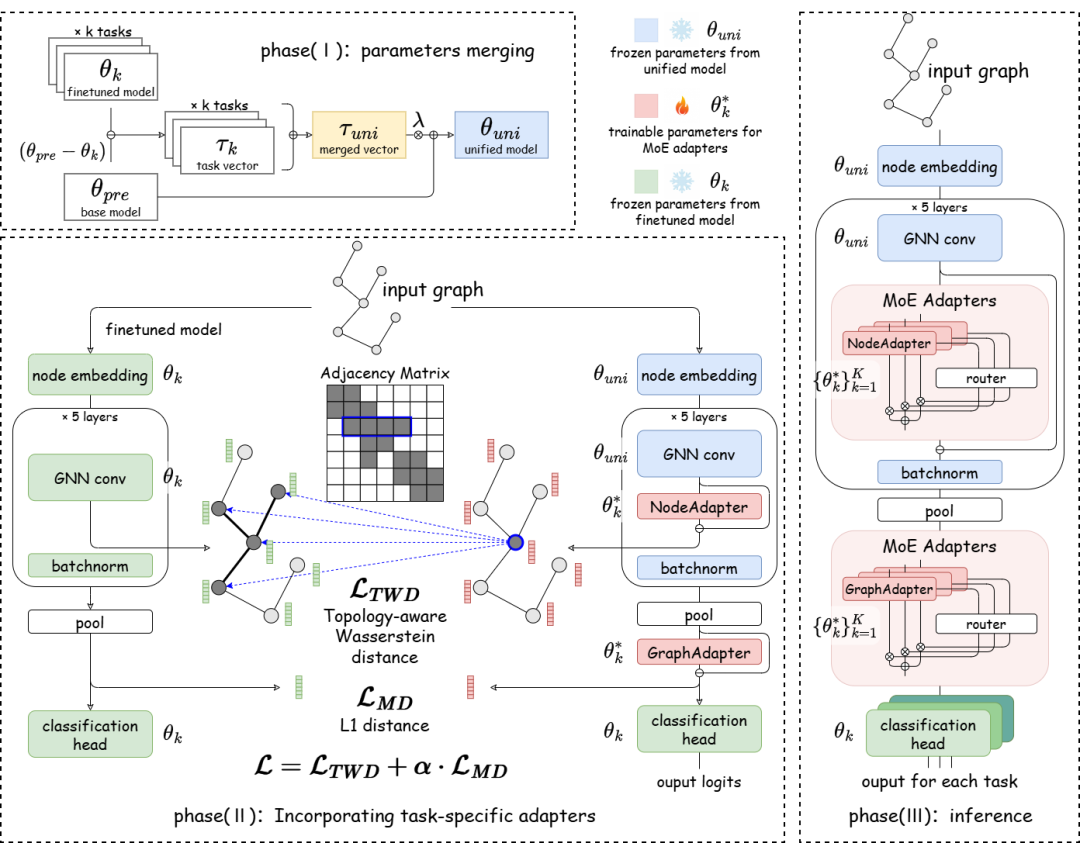
图1. G-Merging 框架图
G-Merging 的整体思路清晰,可分为三个核心阶段:
1. 初步参数融合
此阶段基于“任务算术(Task Arithmetic)”思想。首先,计算每个微调模型相对于预训练基础模型的“任务向量(Task Vector)”,即参数变化量。然后将这些任务向量叠加到预训练模型上,得到一个初步的统一多任务模型。这一步的目的在于快速提取跨任务共享的通用知识,且完全无需训练,能大幅减少直接存储多个模型带来的参数冗余。
2. 拓扑感知对齐
简单的参数叠加不可避免地会引入表示偏移。为了解决这个问题,G-Merging 为每个任务分别训练一个轻量级的适配器(Adapter)模块。其关键创新在于设计了一种 拓扑感知的 Wasserstein 距离(Topology-aware Wasserstein Distance, TWD) 损失函数。
传统的表示对齐方法通常只考虑特征分布,而 TWD 创造性地将图的邻接矩阵结构信息纳入距离约束,使得对齐过程能够显式地“感知”图数据的拓扑连接关系。该损失函数同时在节点级和图级对齐融合模型与原始微调模型的表示分布。
这一阶段,主干模型的参数保持冻结,仅训练占参数量极少的 Adapter,其训练成本仅约为完整微调的 1/8。
3. 无参数的MoE路由推理
在推理阶段,G-Merging 将不同任务对应的 Adapter 视为多个“专家”(Experts),构建了一个无需额外训练参数的混合专家(Mixture-of-Experts, MoE)结构。路由权重并非固定或通过学习得到,而是根据输入图与各任务原型图之间的结构相似度动态计算。这种机制使得拓扑结构相似的任务能够自动共享知识,同时有效缓解了不同任务之间可能存在的冲突。
最终,在部署时,我们仅需保存一个统一的 GNN 主干模型和一组轻量的 Adapter 参数即可。

实验结果
研究者在 8 个经典的分子图分类基准数据集上进行了全面评估,涵盖了不同的 GNN 架构(如 GIN)与预训练策略。
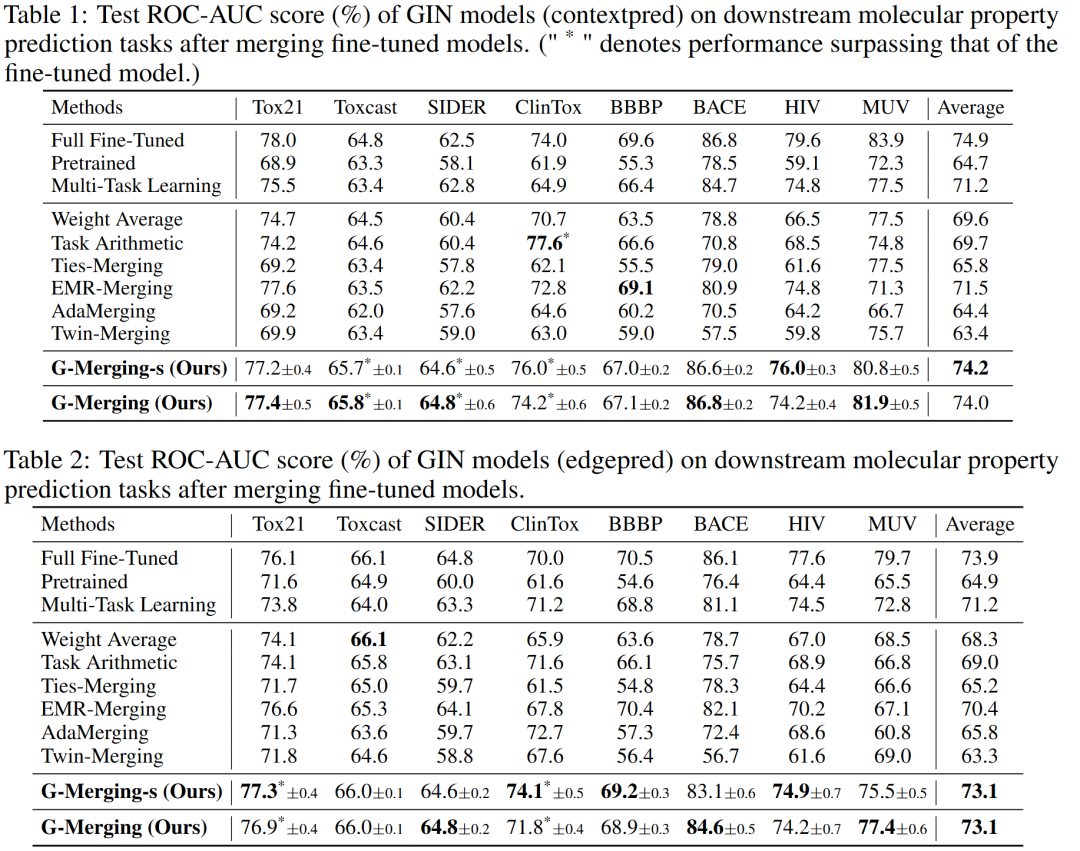
图2. 融合模型在各下游任务上的性能表现(ROC-AUC %)
实验结果令人印象深刻:
- G-Merging 的平均 ROC-AUC 分数显著优于所有基线方法,包括权重平均、Task Arithmetic、TIES-Merging 等。
- 在部分任务(如 ClinTox、Tox21)上,其性能甚至超过了为单一任务专门训练的全量微调模型。
- 在拓扑结构更为复杂的数据集(如 HIV、MUV)上,G-Merging 展现出的优势更为明显,这验证了其拓扑感知设计的重要性。
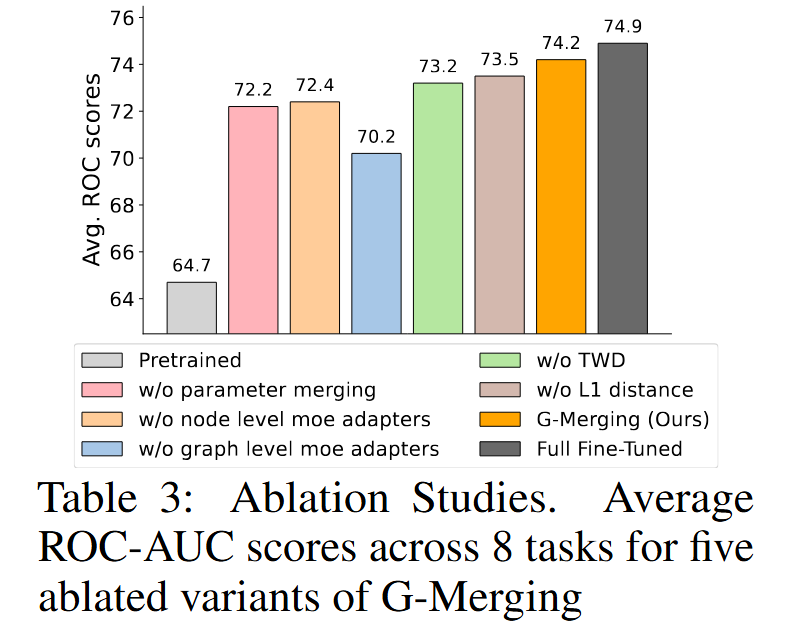
图3. 消融实验:各组件对平均性能的影响
进一步的消融研究深入剖析了各个组件的贡献:
- 无论是去除初步的参数融合,还是去除拓扑感知对齐(TWD),都会导致模型性能出现明显下降。
- MoE 路由机制被证明能够有效促进跨任务间的知识共享与迁移。
- TWD 损失在图结构对齐中起到了不可替代的关键作用。
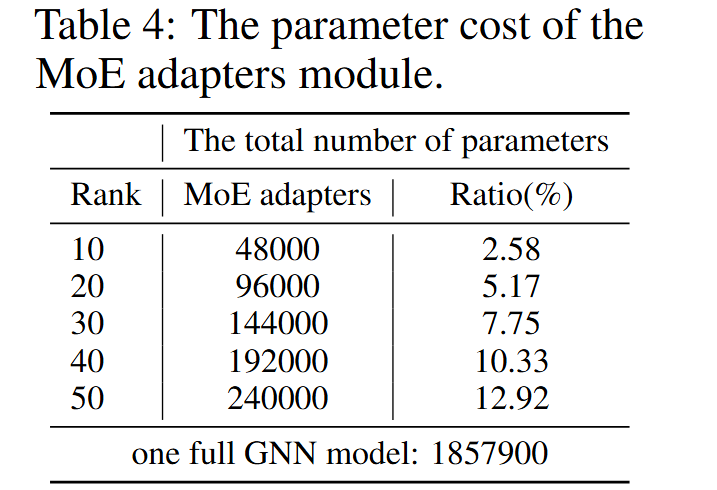
图4. MoE Adapter模块的参数开销占比
在效率方面,数据更有说服力。一个完整的 GNN 模型大约有 185 万个参数,而 G-Merging 所引入的 Adapter 模块参数仅占总参数的 5% 至 13%(取决于秩的大小)。相比维护多个完整的微调模型,这种方案在存储和推理上的成本优势是巨大的。

结语
这项工作首次对图神经网络的模型融合问题进行了系统性探索,并成功验证了图模型同样可以在不进行昂贵联合训练的前提下,通过巧妙利用图数据的结构特性来实现高质量的多任务知识统一。
G-Merging 通过“参数合并 + 拓扑对齐 + 无参数路由”的三段式设计,在确保甚至提升模型性能的同时,显著降低了参数存储与计算训练成本。这为实际应用中多任务图学习的高效部署提供了新的、强有力的解决思路。
继计算机视觉和自然语言处理之后,图模型融合这一方向已经打开,它预示着智能与数据处理的又一个前沿正在被开拓。对于从事相关研究和应用开发的同行而言,这项工作的启发性和实用性都值得深入关注。想了解更多前沿技术解析与实践探讨,欢迎在云栈社区交流分享。
 发表于 2026-3-8 08:42:15
|
查看: 211|
回复: 0
发表于 2026-3-8 08:42:15
|
查看: 211|
回复: 0
