
谁能想到,把旗舰级代码能力塞进10B的小模型里,只要1美刀?
就在昨天,MiniMax M2.5正式开源。在旗舰模型动辄70B+的当下,这个体量显得相当另类。但就是这区区10B激活参数,却在极度考验代码逻辑的SWE-Bench Verified榜单上拿下80.2%的SOTA成绩,在Multi-SWE-Bench上更是以51.3%位居榜首,直接硬刚Opus 4.6和GPT-5.2。
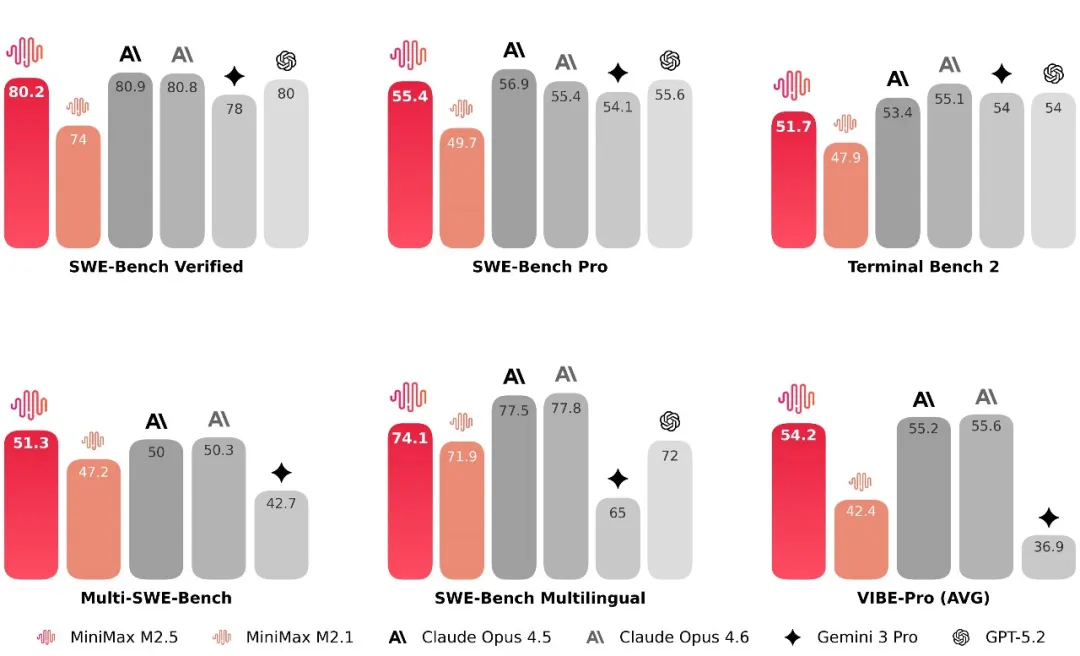
在编程、搜索等多项核心榜单上,M2.5不仅越级反杀,更以绝对优势刷新了SOTA纪录
更让人心动的是它的边际成本。连续高强度工作一小时,仅需1美元。
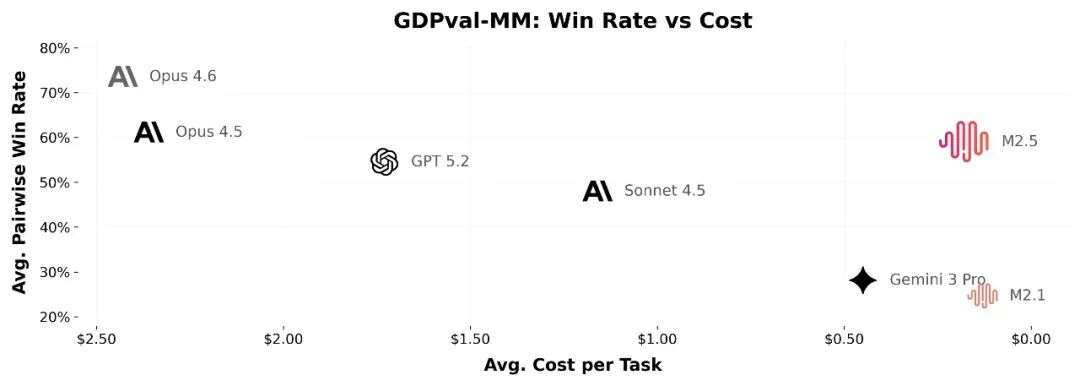
在保持59%高胜率的同时,M2.5的成本仅为竞品的几十分之一
巨大的参数/性能反差,难免让人怀疑数据的含金量。为验证其实力,我们避开常规问答,直接用长文本逻辑构建和数理推演这两个学术深水区进行压测。

Case 1:交互式论文解读站
作为专注AI前沿的学术平台,我们跳过常规测试,第一时间向M2.5投喂了一份135页的综述论文。
Agentic Reasoning for Large Language Models:
https://arxiv.org/pdf/2601.12538
任务指令非常直接,也非常“甲方”:不要摘要,不要大纲。请像一个全栈工程师一样,将这篇PDF重构为一个具备交互式目录的现代化Web看板。
我们刻意模糊了细节,将数据清洗、架构设计到代码落地的全流程,完全交给M2.5自主决策。
令人意外的不仅是准确度,更是恐怖的交付速度。面对135页的超长综述,M2.5没有漫长的推理等待。实测数据显示:仅耗时5.9秒。
在这不到6秒的时间里,它完成了从理解论文、拆解需求、设计UI到编写全套代码的完整闭环。

阅读135页论文并生成全栈代码,端到端仅耗时5.9秒
除了Evolution Roadmap模块因Mermaid版本冲突报错外,HTML骨架、深色模式配色与核心逻辑全部一次成型。
我们将报错信息回传,它迅速定位依赖冲突,给出了替代方案:直接移除Mermaid相关代码,改用标准HTML和CSS展示演进阶段。

分析错误并提出纯HTML替代方案
修复bug只是热身。为了探底逻辑上限,我们追加了两个进阶需求:
- 提取Benchmark数据绘制统计卡片;
- 在右下角集成 AI 问答助手,并要求M2.5将论文核心算法硬编码进JS知识库。
AI问答助手代码细节:逻辑封装极其严密,甚至自动构建了完整的本地知识库结构
最终生成的单文件HTML效果如下:
左侧目录精准复刻了论文层级,底部则自动提取了全文数据,生成了基于ECharts的动态环形图,交互颗粒度极其细腻。
更有意思的是右下角的 AI 问答助手,无论是POMDP的建模意义还是GRPO算法,它都能信手拈来,对答如流,交互体验相当丝滑。
从PDF到交互式网页,M2.5展现了极强的长文本 -> 结构化代码转化能力。

Case 2:数理逻辑可视化
搞定工程代码不算完,我们再给它上一道硬菜:数学可视化。
我们选择了Manim(基于Python的数学动画引擎),并指定基于开源库manim_skill进行开发。
先看向量点积(Dot Product)。M2.5生成的代码精准还原了投影的几何含义。
注意向量 $\vec{a}$ 在 $\vec{b}$ 上的投影变化及数值翻转,模型代码正确,坐标系的动态映射也相当精准。
紧接着,我们测试经典的线性回归(Linear Regression)。
模型构建了一个 $y = mx + c$ 的拟合直线,并用动态红线(Residuals)直观展示了预测值与真实数据间的残差。
随着优化进行,M2.5生成的代码精准控制了直线的逼近过程,将抽象的最小二乘法或误差最小化过程转化为了直观的几何动画。
这证明它不仅理解数学公式,更懂得如何用可视化语言解释拟合的本质。

技术揭秘:为什么M2.5能打?
一个10B模型,逻辑推理和代码生成何以对标旗舰?
根据官方披露的技术细节,核心在于其训练范式变革。
1. 原生Spec行为
在Case 1的网页重构中,M2.5之所以能自主搞定架构,是因为它具备了像架构师一样思考的能力。
不同于普通模型上来就写代码,M2.5在动手前会演化出原生的Spec行为——主动拆解功能、结构和UI设计,这种谋定而后动的特性,让它在复杂任务中表现得极稳。
2. 过程奖励与CISPO算法
针对MoE模型在大规模训练中的稳定性难题,M2.5沿用了CISPO算法。在此基础上,引入了两类关键Reward:
- 过程奖励: 全链路监控思考逻辑,不只奖励结果正确;
- 耗时奖励: 直接将任务完成耗时纳入奖励函数,迫使模型在保持智能的同时,学会以最快路径解决问题。
3. Forge原生Agent RL框架
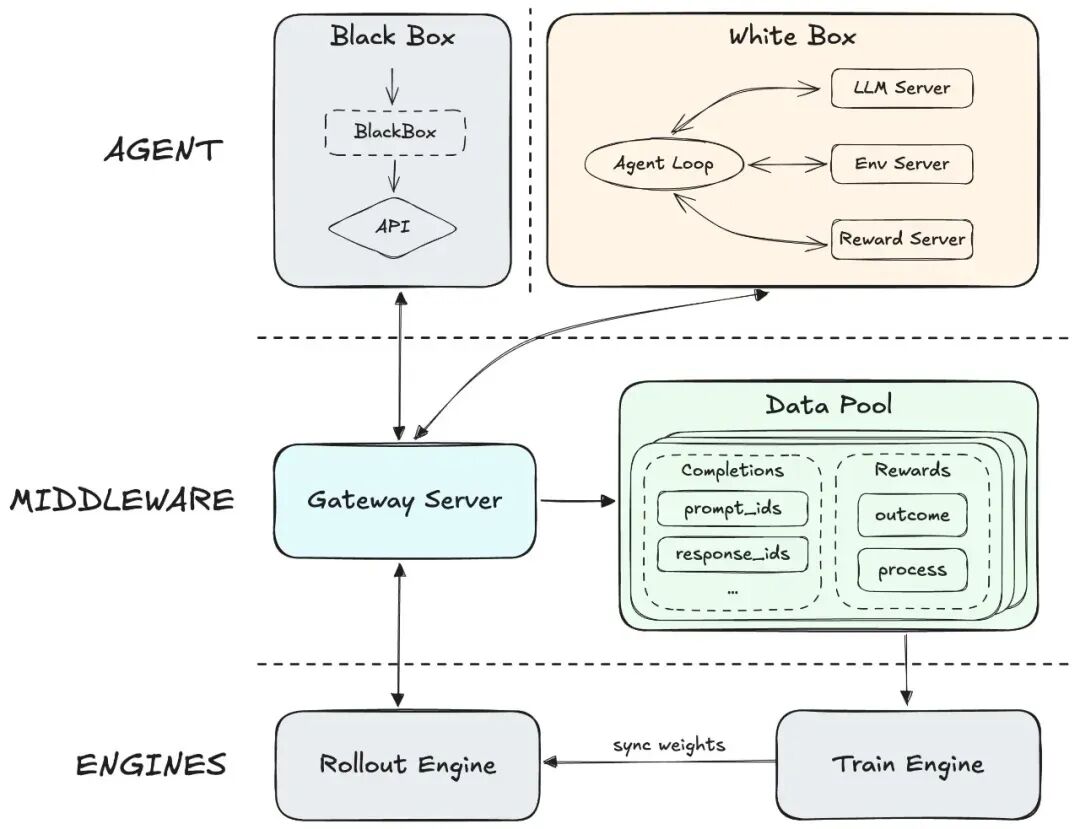
Forge架构:彻底解耦底层引擎与上层交互,实现40倍训练加速
工程级极致优化:为了解决大规模Agent训练的效率瓶颈,M2.5打出了两记组合拳:
- IO层面: 引入Windowed FIFO调度策略,在滑动窗口内异步读取,完美解决了传统RL训练中的队头阻塞(HoL Blocking)问题;
- 计算层面: 针对Agent场景大量重复的前缀(System Prompt),采用树状合并(Tree Attention)策略,实现了约40倍训练加速。

结语:重塑生产力范式
测完这两轮,M2.5给我们的感觉,早已超越了一个便宜好用的工具。
我们习惯用参数量来丈量智能的边界,认为只有千亿模型才配谈逻辑。但M2.5证明了真正的智能,不在于海量的通识记忆,而在于对特定问题的精准狙击。
从硬核的科研代码,到严谨的金融法律文档,再到日常办公琐事,它不再是那个需要你费力调教的实习生,而是一个懂代码、懂业务、且不知疲倦的硅基合伙人。
不再需要昂贵的算力堆砌,也不再有漫长的等待。未来的范式是随时随地、不知疲倦的稳定产出。
你负责定义问题与价值,它负责以极低的边际成本,在后台稳定地调动一切资源——持续、快速、完美地交付。
你对这类高效能、低成本的人工智能模型在实际开发中的应用怎么看?欢迎在云栈社区的人工智能板块或Python技术区分享你的看法和测试经验。

 发表于 2026-3-8 08:45:38
|
查看: 225|
回复: 0
发表于 2026-3-8 08:45:38
|
查看: 225|
回复: 0
