近年来,预训练语言模型(PLMs)的兴起,让基于文本的知识图谱补全(KGC)方法(如 SimKGC)取得了不小的成功。相比传统的基于嵌入的方法(如 TransE、RotatE),这些方法利用实体和关系的文本描述,将结构化预测转化为了语义匹配问题,展现出更强的泛化能力,尤其擅长处理未见过实体的归纳式场景。现有的文本KGC范式通常是分别编码查询(头实体+关系)和候选尾实体,然后通过最大化它们在特征空间中的相似度来进行预测。
但现有的方法是否忽略了什么?没错,它们确实漏掉了一个极其重要且天然存在的信息源——关系感知邻居。简单来说,对于一个给定的查询 (h, r, ?),图中已知的其他满足 (h, r, t‘) 的尾实体 t‘ 实际上是预测目标的最佳“参考案例”。这些实体就是所谓的“锚点”。
这篇发表在 AAAI 2025 上的论文《Knowledge Graph Completion with Relation-Aware Anchor Enhancement》就敏锐地抓住了这一点,并提出了一个通用且有效的增强框架。对于希望深入了解KGC前沿技术的开发者,云栈社区 的技术文档板块汇集了大量相关的知识图谱教程与源码解析,值得参考。
核心创新与贡献
- 揭示了关系感知锚点的价值:这是首次系统性地探讨并证实,查询中头实体的“关系感知邻居”(即通过相同关系连接的其他尾实体)能够作为极其有效的上下文锚点。它们为目标预测提供了具体的参考原型,能帮助模型在语义空间中更精准地定位目标。
- 提出了RAA-KGC通用框架:作者设计了一种名为“关系感知锚点增强”的新方法。它不改变原有模型的主体结构,而是通过引入锚点生成模块和锚点增强的查询表示,拉近查询向量与锚点邻域的距离,使生成的嵌入更具辨别力。
- 设计了联合优化目标:在传统的对比学习损失基础上,增加了一项锚点增强损失。该目标结合了“查询-目标实体”的匹配和“锚点增强查询-目标实体”的辅助匹配,通过多视角训练强化语义匹配,并引入了结构化的归纳偏置。
- 取得了SOTA性能:在
WN18RR、FB15k-237 和 Wikidata5M-Trans 三个标准数据集上的实验表明,RAA-KGC 全面超越了现有最优方法,并且展现出极强的兼容性,可作为通用插件显著提升包括 TransE、SimKGC 在内的多种基线模型的性能。
RAA-KGC方法详解
RAA-KGC 的核心思想很直观:利用同一关系下已知的“兄弟”实体(锚点),帮助模型去“想象”目标实体应该长什么样。整个框架如下图所示,主要包含三个模块:关系感知锚点生成、锚点增强嵌入生成以及联合训练与推理。
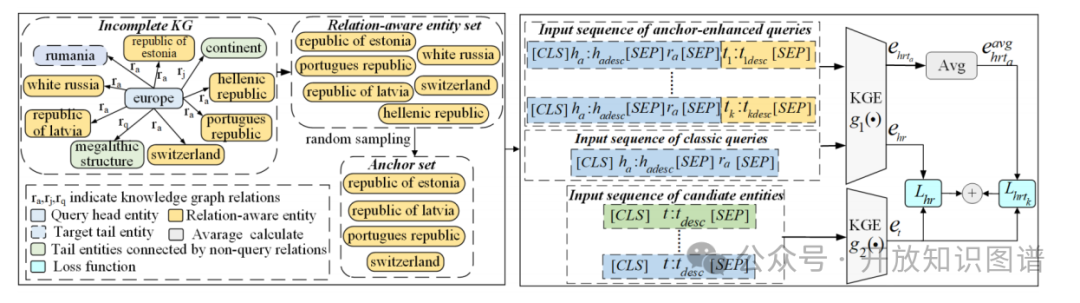
图1:RAA-KGC模型框架图
1. 关系感知锚点生成
给定知识图谱 G 和一个输入查询 (h, r, ?):
- 定义锚点候选集:首先,检索出图谱中所有与头实体
h 通过关系 r 相连的、已知的其他尾实体,这些就是潜在的“关系感知锚点”。
- 锚点采样:为了控制计算成本并引入随机性以增强鲁棒性,在训练时,对于每个查询,系统会从这个候选集中随机采样
K 个实体作为当前步的锚点集。如果集合为空(即该查询是该关系下的唯一实例),则使用特殊的 [MASK] 标记占位。
2. 锚点增强嵌入生成
模型采用基于 BERT 的双编码器架构,包含两个共享权重的 Transformer 编码器。
- 经典查询编码:输入为标准序列
[CLS] head_desc [SEP] relation_desc [SEP],编码后得到查询向量。
- 锚点增强查询编码:这是关键创新。构造新的输入序列,将锚点实体的文本描述拼接进去:
[CLS] head_desc [SEP] relation_desc [SEP] anchor_1_desc [SEP] ... [SEP] anchor_K_desc [SEP]。为了综合多个锚点信息并减少噪声,作者对 K 个锚点分别构造增强序列并编码,最后对得到的 K 个向量取平均值,得到最终的锚点增强查询向量。
- 候选实体编码:输入候选尾实体的文本描述
[CLS] tail_desc [SEP],得到实体向量。
3. 联合训练与推理
为了充分利用锚点信息,作者设计了一个包含两部分的联合损失函数:
- 基础对比损失:标准的
InfoNCE 损失,旨在最大化经典查询向量与正确尾实体向量之间的相似度。
- 锚点增强损失:同样采用
InfoNCE 形式,但旨在最大化锚点增强查询向量与正确尾实体之间的相似度。这一项迫使模型学习到的目标实体表示不仅要匹配查询,还要靠近其“兄弟实体”所在的语义空间。
在推理阶段,最终的预测得分是经典查询得分与锚点增强查询得分的加权和,模型根据该得分对所有候选实体进行排序。
实验结果与分析
实验设置
- 数据集:
WN18RR(稀疏图,侧重逻辑关系)、FB15k-237(稠密图,侧重百科知识)、Wikidata5M-Trans(大规模图,用于测试归纳式场景)。
- 基线模型:包括基于结构的
TransE、RotatE,以及基于文本的 KG-BERT、StAR、SimKGC 等。
- 评价指标:
MRR、Hits@1、Hits@3、Hits@10。
主实验结果
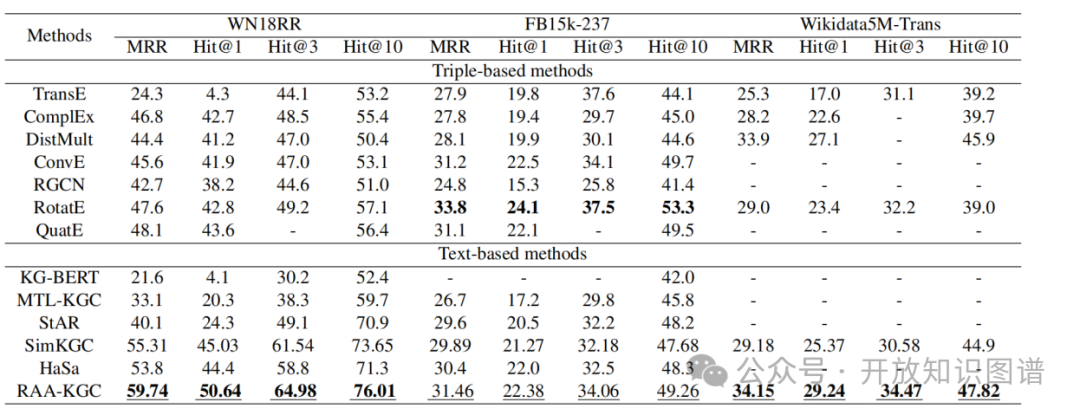
表1:总体实验结果
- SOTA性能:在
WN18RR 和 Wikidata5M 数据集上,RAA-KGC 全面超越了之前的最强基线 SimKGC。例如在 WN18RR 上,MRR 提升了约 4.4%,Hits@1 提升了 5.6%。这证明了锚点增强策略对于稀疏图和长尾关系的补全特别有效。
- FB15k-237表现:在该稠密数据集上,
RAA-KGC 与 SimKGC 性能持平或略优。分析认为,FB15k-237 本身结构信息已很丰富,且存在大量复杂的“多对多”关系,导致锚点选择的噪声增大,从而限制了文本锚点的增益上限。
消融实验与深入分析
- 锚点的必要性:移除锚点增强模块(即退化为
SimKGC)后,模型性能显著下降,直接证明了关系感知锚点提供了额外的有效监督信号。
- 锚点数量的影响:实验表明,锚点数量
K 从 1 增加到 4 时,性能稳步提升。但当 K 过大(如 >5)时,性能趋于饱和甚至略有下降,可能是因为引入了与目标实体语义差异较大的边缘锚点(噪声)。
- 通用性验证:作者将
RAA 策略应用到非文本模型(如 TransE)上,通过聚合锚点的结构嵌入来增强查询。结果显示,TransE+RAA 相比原始 TransE 也有显著提升,证明了“关系感知锚点”这一思想具有跨模型的通用价值。
- 强大的归纳能力:在
Wikidata5M 的归纳式设置下(测试集包含训练集中未见过的实体),RAA-KGC 展现出了极强的泛化能力,大幅领先于对比方法。这表明通过锚点引入的类比推理能力,能有效帮助预训练语言模型处理新出现的实体。
总结
本文提出的 RAA-KGC 框架,其核心创新在于将传统的“查询-目标”二元建模,扩展为“查询-锚点-目标”的类比推理结构。通过在查询编码时引入随机采样的锚点描述并设计联合对比学习目标,该方法使目标实体特征更紧凑、语义更一致,有效缓解了传统负采样缺乏正向参考的问题。实验表明,该方法在多个数据集上均超越现有最优方法,且具备良好的即插即用性,为知识图谱推理提供了新的、有效的自监督增强思路。想持续跟进人工智能与图学习领域的最新动态与深度解析,欢迎关注 云栈社区 的更新。 |  发表于 2026-4-2 02:34:07
|
查看: 183|
回复: 0
发表于 2026-4-2 02:34:07
|
查看: 183|
回复: 0
