1.2.1 BERT:双向编码器表示的突破
预训练与微调范式的兴起:2018年,谷歌推出的BERT(Bidirectional Encoder Representations from Transformers)模型开启了预训练与微调的新时代。BERT基于Transformer的编码器架构,通过在大规模无监督文本语料库上进行预训练,学习到通用的语言表示,然后在特定的下游任务(如文本分类、情感分析、问答系统等)上进行微调。这种范式极大地降低了对大量标注数据的依赖,并迅速成为NLP领域的主流方法。
掩码语言建模(Masked Language Modeling):BERT的预训练任务之一是掩码语言建模。它随机地将输入文本中的一些单词替换为特殊的掩码标记([MASK]),然后让模型根据上下文预测被掩码的单词。这种方式迫使模型学习单词在不同上下文中的语义表示。例如,对于句子“苹果是一种[MASK]”,模型需要根据“苹果”以及整个句子的语境来预测出“水果”。
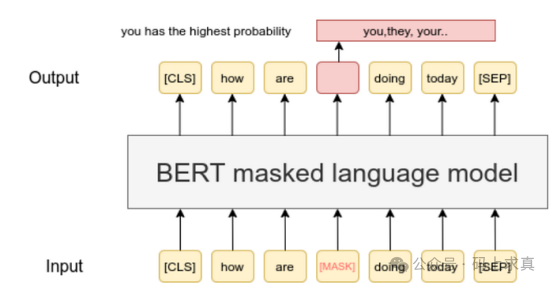
下一句预测(Next Sentence Prediction):另一个预训练任务是下一句预测。BERT接收一对句子,判断第二个句子是否是第一个句子在原文中的下一句。通过这个任务,模型能够学习句子之间的逻辑关系,这对于问答和文本推理等任务非常重要。
对NLP任务的广泛影响:BERT的出现使得NLP领域的各种任务性能都得到了显著提升。它证明了Transformer架构在捕捉语言上下文信息方面的强大能力,也为后续更多基于Transformer的预训练模型的发展提供了借鉴。
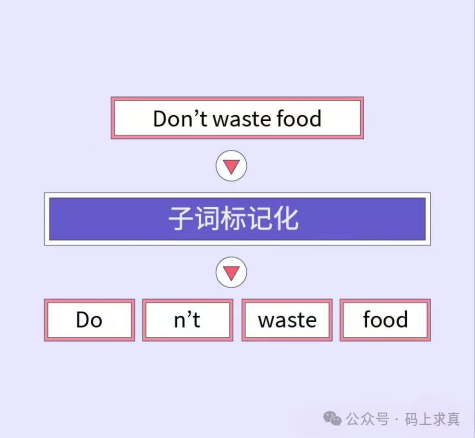
子词标记化(Subword Tokenization):BERT将单词划分为子词单元,以平衡词汇表的大小和处理未知词汇的能力。这种方法使BERT能够更有效地处理多种语言,尤其是形态丰富的语言。
1.2.2 GPT系列:生成式预训练的探索
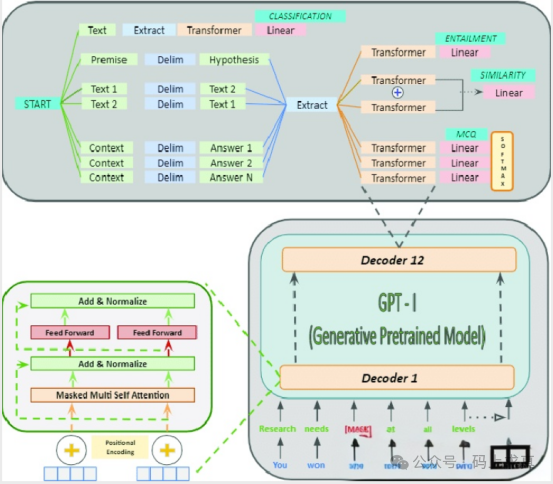
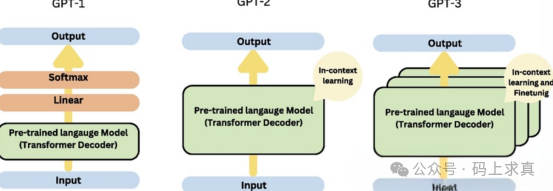
GPT-1:生成式预训练的开端:OpenAI在2018年推出的GPT-1是生成式预训练Transformer(Generative Pretrained Transformer)系列的首个模型。它基于Transformer的解码器架构,通过在大规模文本语料库上进行无监督预训练,学习语言的统计规律和语义信息。与BERT不同,GPT-1更侧重于文本生成任务,它通过给定前文预测下一个单词的方式进行训练。
GPT-2:规模与能力的提升:2019年发布的GPT-2进一步扩大了模型规模,增加了参数数量和训练数据量。它在零样本学习(Zero-Shot Learning)方面表现出了令人惊讶的能力,即仅根据任务描述就能完成特定任务。GPT-2能够生成更加自然流畅、逻辑连贯的文本,展示了生成式预训练模型在文本生成领域的巨大潜力。

GPT-3:少样本学习的突破:2020年,GPT-3的发布引起了广泛关注。它拥有多达1750亿个参数,在少样本学习(Few-Shot Learning)和零样本学习方面取得了重大突破。GPT-3只需少量的示例或提示,就能在各种任务中表现出较高的性能,如文本分类、翻译、代码生成等。它的强大能力使其成为当时最先进的语言模型之一。
1.2.3 其他早期改进模型
T5:文本到文本迁移转换器:谷歌的T5(Text-to-Text Transfer Transformer)模型将所有NLP任务统一转化为文本到文本的问题。这种统一的框架使得模型能够在不同任务之间进行更好的迁移学习,展示了Transformer架构在多任务处理方面的灵活性。
BART:双向和自回归Transformer:BART结合了双向编码和自回归解码的特点。它在预训练阶段通过对文本进行破坏和重建的方式学习语言表示,在生成任务中能够生成高质量的文本,在文本摘要等任务上表现出色。
MASS:掩码序列到序列预训练:MASS为序列到序列学习引入了新的预训练目标,通过掩码输入序列中的部分内容,让模型预测被掩码的部分,从而提高模型在机器翻译、文本摘要等序列到序列任务中的性能。
这些早期的改进模型从不同角度对Transformer架构进行了优化和拓展,进一步验证了其灵活性和强大潜力,为后续更复杂、更强大的模型发展奠定了坚实的基础。想了解更多关于人工智能模型的技术演进与实践,欢迎访问云栈社区进行交流探讨。
|  发表于 2026-1-25 22:54:13
|
查看: 233|
回复: 0
发表于 2026-1-25 22:54:13
|
查看: 233|
回复: 0
