今天带大家深入了解一款近期在 GitHub 上爆火的 AI 智能体项目 —— MiroThinker,它凭借独特的设计思路和实用的功能,在开源社区收获了 7.9k star 的关注。

GitHub 地址:https://github.com/MiroMindAI/MiroThinker
MiroThinker 是什么?
在研究完它的 GitHub 项目后,我们发现它并非普通的聊天大模型,而是面向严肃研究、复杂决策的搜索智能体。
MiroThinker 是 MiroMindAI 开源的搜索 + 推理 + 自我修正智能体模型,其核心定位是会研究、会查证、会修正的 “AI 研究员”,而非单纯生成文本的大模型。
我们在日常使用 AI 时,普遍会遇到这些痛点:
- 幻觉严重:一本正经地胡说八道,难以应用于科研、决策、报告等严肃场景。
- 被动依赖记忆:仅依赖内部参数记忆,不会主动查资料、验真伪。
- 长链推理易崩:面对多步骤、长链条的复杂任务时,逻辑容易坍塌,结论越推越偏。
- 成本与能力难平衡:大参数模型成本高昂、部署繁重,而小模型的能力又往往不够用。
MiroThinker 的解决思路更为“直接”:不卷参数、卷交互。它通过构建推理 → 验证 → 修正的闭环,将外部信息作为证据,让小参数模型也能跑出接近万亿级大模型的严谨推理能力。
一句话概括:它是一个能自己找资料、自己验算、自己纠错的 开源 AI 智能体,非常适合严肃研究、深度分析和复杂决策等场景。

功能亮点
- 交互式扩展(核心创新):不依赖参数膨胀,而是强化模型与外部信息的交互能力,用实时检索到的证据对冲幻觉,有效解决长链推理中的逻辑坍塌问题。
- 推理-验证-修正闭环:先生成推理链 → 调用外部信息进行校验 → 自动修正错误结论,从而大幅降低幻觉率。
- 小参数高性能:其 30B 参数的版本,在多个预测和推理基准测试中,表现接近参数规模远大于它的闭源模型,实现成本的大幅降低。
- 本地可部署、可二次开发:项目完全开源,支持私有化部署、本地推理与检索,数据安全可控。
- 面向研究与决策:擅长深度研读、信息整合、趋势推演、多方案对比,是生成报告、进行战略分析的得力助手。
技术架构深度剖析
1. 架构设计总思路
MiroThinker 的架构思路非常清晰:上层做交互与推理,中层做校验与修正,底层做检索与执行,全程围绕“用外部证据保证推理可靠”这一核心理念展开。
2. 完整分层架构

3. 架构思路拆解
- 先推理,再验真:先生成推理路径,再用检索结果对推理链进行“打分”校验,避免盲目输出,防止长任务下的错误累积。
- 证据优先于记忆:将外部可信信息作为第一依据,模型自身的参数知识仅作为辅助,确保结论的客观性。
- 可修正、可回溯:一旦发现错误或矛盾,系统不会“硬撑”,而是自动回滚并重新推理,保证结论最终收敛到可靠区间。
- 轻核心、强扩展:保持核心引擎的稳定性,检索模块、校验模块、工具调用等均可进行插拔式扩展。
下面分享一下项目用到的核心技术栈,方便开发者进行技术参考:
- 后端核心:Python、PyTorch
- 推理框架:Transformers、PEFT、vLLM
- 检索能力:FAISS、RAG 架构、本地/在线检索
- 调度与工具:LangChain/LlamaIndex、FastAPI
- 部署:Docker、Uvicorn
- 数据与日志:SQLite、Elasticsearch(可选)
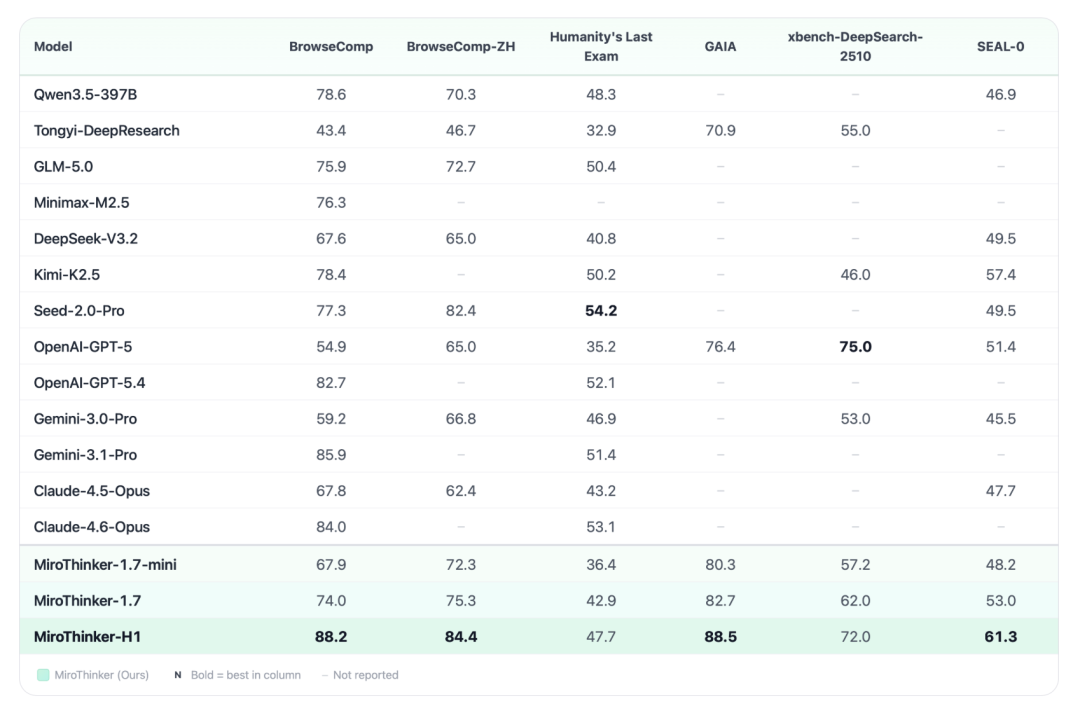
4. 性能表现
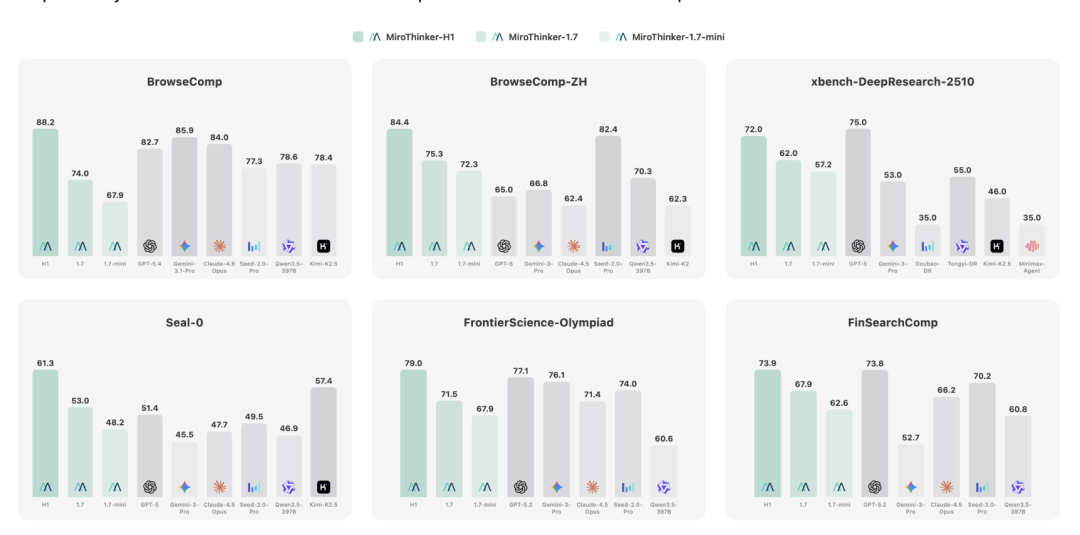
为了更直观地了解其性能,可以参考它在多个权威基准测试中的得分情况。
典型应用场景
- 学术/行业研究:自动研读论文、检索资料、整理综述、交叉验证观点。
- 战略/商业分析:推演市场趋势、对比竞争方案、识别潜在风险、生成分析报告。
- 法律/咨询:事实核查、逻辑校验、长篇法律文书或合同的分析。
- 企业私有化助手:基于内部知识库的精准问答、合规审查、敏感数据的本地化推理。
- 教育/科研:辅助解题与验算、拆解复杂步骤、引导学生进行探究式学习。
客观优缺点分析
优点:
- 幻觉极低:得益于验证修正闭环,输出可靠性高,适合严肃用途。
- 小而强:30B 参数就能匹敌更大模型的表现,部署成本友好。
- 架构先进:其交互式扩展理念,代表了下一代 AI 智能体的重要发展方向。
- 完全开源:支持私有化、二次开发,许可证(AP2.0)对商业应用友好。
- 推理可解释:提供证据链和修正过程,结论生成并非“黑盒”。
缺点:
- 不擅长闲聊:定位是研究型智能体,日常对话、情感互动并非其强项。
- 依赖检索质量:检索到的外部信息若有偏差,会直接影响最终结论。
- 生态仍在建设:插件、详细教程、活跃社区等生态建设,尚不及一些老牌开源项目完善。
- 硬件仍有门槛:30B 模型进行本地推理,仍需要一块性能较好的显卡。
本地部署教程
环境要求
- Python 3.9+
- 显存建议:≥ 10GB(FP16),≥ 6GB(量化版本)
- Git、Docker(可选)
步骤
- 克隆项目
git clone https://github.com/MiroMindAI/MiroThinker.git
cd MiroThinker
- 安装依赖
pip install -r requirements.txt
- 模型下载
按照官方文档说明,下载对应的模型权重文件,放入指定目录,并修改相关配置文件。
- 启动服务
python start.py
# 或使用 Docker 一键启动
docker-compose up -d
启动成功后,在浏览器中打开 http://localhost:8000 即可开始使用。
总结
MiroThinker 是今年开源 AI 领域中非常值得关注的一个项目。它没有盲目跟风堆叠参数,而是直击当前 AI 应用中最令人头疼的幻觉、不可靠、不可信等问题,通过“推理 — 验证 — 修正”的独特路径,探索出了一条小而强、重可靠的新方向。
对我们开发者而言,它不仅是一个实用的工具,更是下一代 AI 智能体架构的典型代表:它会主动查证、懂得自我修正、进行深度思考,而不仅仅是简单地对话。如果你关注可靠 AI、研究型 AI 应用或私有化部署,这个项目值得你深入研究和尝试。在 云栈社区,你也能找到更多类似的优质开源项目和技术讨论。 |  发表于 2026-3-24 01:33:58
|
查看: 187|
回复: 0
发表于 2026-3-24 01:33:58
|
查看: 187|
回复: 0
