上一篇文章 PostgreSQL 当索引顺序扫描遇到索引分裂,如何保证数据一致性 我们讨论了顺序扫描遇到分裂时的处理逻辑。那么,当倒序扫描遇上页面分裂,又该如何处理呢?是否也能简单地“跳页”?
2. 倒序扫描与顺序扫描的核心差异
顺序扫描在并发分裂时可以采用“跳页”策略,其根本原因在于这一行为巧妙地符合 MVCC(多版本并发控制)的规则:分裂产生的新页面上的数据,是在扫描开始后才插入的,对于当前扫描事务而言,这些数据本就是不可见的。因此,跳过它们不会影响数据一致性。
但对于倒序扫描来说,情况就大不相同了。假设初始的索引叶子节点链表如下图所示,我们正在执行一次倒序扫描。

假设在某一时刻(T时刻),倒序扫描刚刚完成对页面2的扫描,此时叶子链表的状态如下:
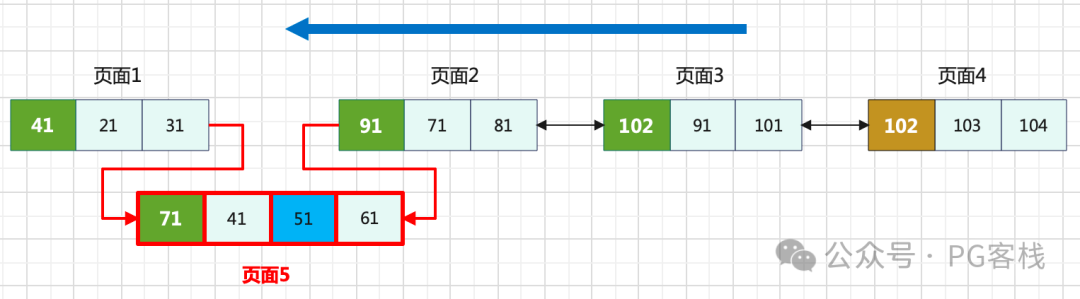
关键在于,在扫描页面2期间,由于有新数据“51”的插入,导致其前驱页面1发生了分裂,新生成了页面5。原本位于页面1上的记录“41”和“61”被迁移到了这个新分裂出来的页面5上。那么,接下来倒序扫描应该选择哪个页面继续扫描呢?
如果生搬硬套顺序扫描的逻辑,可能会选择跳过页面5。但显而易见,这将直接导致“41”和“61”两条记录丢失,引发严重的数据一致性问题。因此,对于倒序扫描而言,“跳页”是绝对行不通的。
既然不能跳页,那么扫描完页面2后,直接根据其 prev(前向)指针指向的页面进行扫描不就可以了吗?遗憾的是,这仍然不可行!
这涉及到在数据库/中间件/技术栈这类系统中经常讨论的并发控制核心问题。PostgreSQL 的索引加锁有一个基本原则:只能从左向右依次加锁(即沿着 next 指针方向)。在上述场景中,这意味着必须先释放页面2的锁,才能尝试对其 prev 指针指向的页面加锁。这个“释放锁”到“获取新锁”的短暂间隙,就为页面再次分裂提供了可乘之机。
假设页面1在我们释放页面2的锁后,又连续发生了多次分裂,状态可能演变成下图所示的样子:
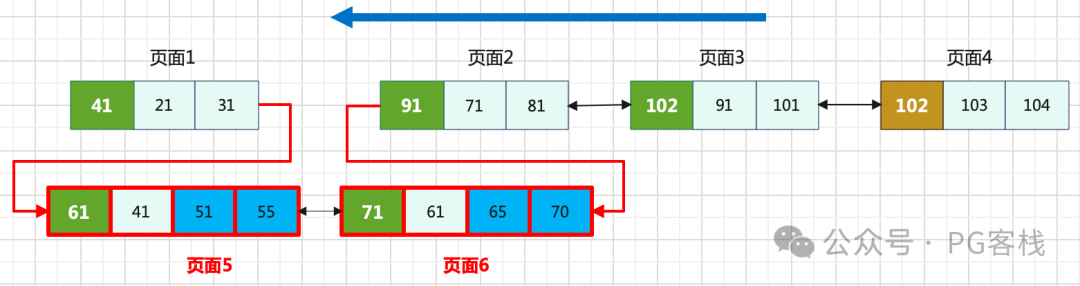
如图所示,此时页面2的 prev 指针可能指向1,也可能指向5或6,存在很大的不确定性。如何在这种动态变化中,准确地找到真正的前驱页面,避免数据遗漏呢?
3. 倒序扫描如何应对并发分裂
为了解决上述因连续分裂导致的 prev 指针不确定性,PostgreSQL 设计了一套更为复杂的逆序扫描流程:
- 对当前页面
blkno 加读锁,将其所有元组(记录)缓存到内存,然后释放页面锁,但仍保持 PIN(一种轻量级的内存驻留标记)。
- 当缓存的元组全部返回给查询后,重新对页面
blkno 加锁,获取其 prev 页号,然后再次释放锁。
- 根据获取的
prev 页号,读取该页面 P。
- 判断页面 P 的
next 指针是否等于步骤1中的 blkno。如果相等,则证明 P 就是我们要找的正确前驱页面,缓存 P 的元组用于后续扫描。
- 如果页面 P 的
next 指针不等于 blkno,说明在我们释放锁的间隙,页面 P 发生了分裂或其它结构调整。此时,我们需要沿着 P 的 next 指针继续向后查找,直到找到一个 next 指针恰好等于 blkno 的页面为止。
通过这套“验证-追赶”机制,倒序扫描就能在并发分裂的环境下,稳定地定位到真正的上一个页面,从而确保不会遗漏任何本应可见的数据。
4. 倒序扫描与并发摘叶
讨论完分裂,另一个棘手的并发场景是页面被“摘除”(删除)。假设在 T 时刻,倒序扫描完页面2后,索引结构变成了下面这样:
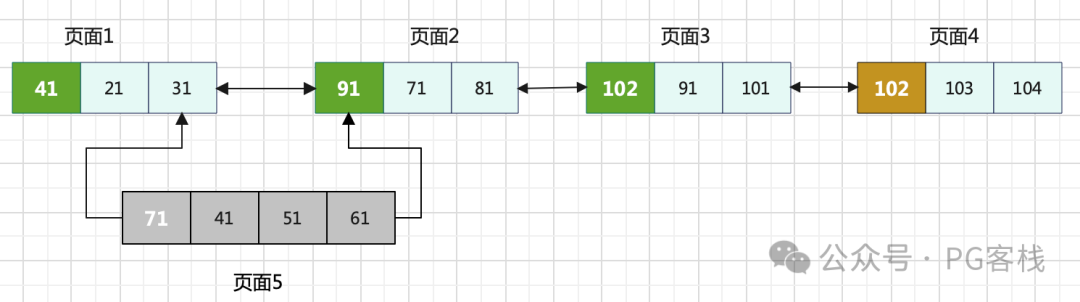
此时,页面5已经被从B-Tree中摘除。如果按照上述步骤,我们获取到页面2的 prev 是5,然后去读取页面5,会发现它已经被标记为删除。按照逻辑,我们需要继续向右(next方向)寻找,直到找到一个未被删除且 next 指针指向2的正常页面。
但这里有一个极端情况:页面5在被删除后,其物理空间可能很快被复用于存储其他数据。这可能导致我们沿着一个“错误”的链表一直向右找,可能遍历大量无关页面,甚至永远找不到 next 指向2的页面,从而陷入死循环。
为了避免这种情况,PostgreSQL 设定了一个安全阈值:默认最多向后连续查找4次。如果4次之后仍未找到目标,就放弃当前路径,重新获取页面2的 prev 页面信息,再尝试新的路径。这个逻辑体现在 _bt_walk_left 函数的关键代码中:
for (;;)
{
if (!P_ISDELETED(opaque) && opaque->btpo_next == obknum)
{
/* Found desired page, return it */
return buf;
}
if (P_RIGHTMOST(opaque) || ++tries > 4)
break;
blkno = opaque->btpo_next;
buf = _bt_relandgetbuf(rel, buf, blkno, BT_READ);
page = BufferGetPage(buf);
TestForOldSnapshot(snapshot, rel, page);
opaque = BTPageGetOpaque(page);
}
如果尝试4次后跳出循环,发现目标页面(比如最初获取的 prev=5)依然处于删除状态,那说明并发删除操作非常频繁,连续摘除了多个页面。此时,策略变为:一直向右找到第一个未被删除的页面,从这个页面开始向左定位。
/* It was deleted. Move right to first non-deleted page (there must be one);
that is the page that has acquired the deleted one's keyspace, so stepping
left from it will take us where we want to be. */
for (;;)
{
if (P_RIGHTMOST(opaque))
elog(ERROR, "fell off the end of index \"%s\"",
RelationGetRelationName(rel));
blkno = opaque->btpo_next;
buf = _bt_relandgetbuf(rel, buf, blkno, BT_READ);
page = BufferGetPage(buf);
TestForOldSnapshot(snapshot, rel, page);
opaque = BTPageGetOpaque(page);
if (!P_ISDELETED(opaque))
break;
}
5. 总结
PostgreSQL 中倒序扫描定位下一个页面的核心逻辑,是通过 _bt_walk_left 函数实现的。理解了其背后需要应对的并发分裂与并发摘叶两大挑战,再看源码就会清晰许多。
我们可以清晰地看到,相比于顺序扫描,倒序扫描的实现复杂度要高出一个量级。它不仅要巧妙地处理并发分裂导致的指针“漂移”问题,还要谨慎应对并发摘叶可能带来的“死胡同”困境。这一切复杂性的根源,都来自于为了最大化并发性能而引入的精细加锁规则——为了不阻塞写入,扫描不得不频繁地释放和重锁,从而置身于一个持续变动的结构中。
这种在极致性能与绝对正确性之间的精巧平衡,正是深入理解像 PostgreSQL 这样的数据库系统内核的魅力所在。如果你对这类底层机制感兴趣,欢迎在云栈社区交流探讨。
 发表于 2026-3-24 01:36:31
|
查看: 84|
回复: 0
发表于 2026-3-24 01:36:31
|
查看: 84|
回复: 0
