残差连接(Residual Connection)自2015年何恺明在ResNet中提出以来,已经统治深度学习架构十年。它的核心公式 $h_l = h_{l-1} + f(h_{l-1})$ 简洁而优雅——为梯度提供恒等映射的“高速公路”,使数百层网络的训练成为可能。从ResNet到GPT,几乎所有主流架构都在使用这个看似完美的公式。
但“完美”之下隐藏着一个根本性问题:残差连接用固定的单位权重无差别地累加所有层的输出。当网络深度从几十层扩展到上百层时,这种“一视同仁”的累加策略导致早期层的贡献被逐渐稀释,深层必须学习越来越大的输出才能产生影响——这与我们构建深度网络的初衷背道而驰。
2024年底到2026年初,中国团队在这一方向上连下三刀:
- 2024年:字节跳动的 Hyper-Connections(HC)率先打破单流残差,引入多条并行信息流
- 2025年底:DeepSeek 的 mHC(Manifold-Constrained HC)为多流架构装上“限速器”,用流形约束解决训练不稳定问题
- 2026年3月:Kimi 团队(Moonshot AI)的 Attention Residuals(AttnRes) 提出一个更根本的解法——别修路了,换发动机
AttnRes的核心洞察精妙而深刻:残差连接在深度维度压缩信息的方式,本质上等价于RNN在时间维度的循环。既然Transformer已经用Softmax Attention替代了时间维度的循环,为什么不能对深度维度做同样的事?
本文将从动机分析出发,系统剖析Attention Residuals的理论框架、工程实现与实验验证,并以结构化矩阵视角统一对比各类残差变体方法。

动机:PreNorm稀释与深度维度的信息压缩
残差连接的双重角色
在深入问题之前,有必要厘清残差连接在现代Transformer中扮演的双重角色:
- 角色一:梯度通路。残差连接为梯度提供了一条不经过非线性变换的直通路径,这是深度网络可训练的基础。没有残差连接,数百层网络的梯度会在反向传播中指数衰减。
-
角色二:信息聚合。残差连接隐含地定义了一种信息聚合策略。将递推公式展开:
$$h_L = x + \sum_{l=1}^{L} f_l(h_{l-1})$$
第 $L$ 层的隐藏状态 $h_L$ 是初始嵌入 $x$ 与所有前层输出 $f_l(h_{l-1})$ 的等权求和。换言之,标准残差连接隐式地给每一层的贡献分配了相同的权重1。
这种等权累加策略在浅层网络中问题不大,但在数百层的深度Transformer中,它引发了一系列结构性问题。
PreNorm稀释问题
现代大语言模型普遍采用PreNorm(Pre-Layer Normalization)架构。在PreNorm下,标准残差连接的问题可以从三个层面理解:
- 幅度稀释:隐藏状态的幅度以 $O(L)$ 增长($L$为层数)。当网络有128层时,初始嵌入的相对贡献被稀释到 $1/128$。RMSNorm/LayerNorm在每层入口处将这个越来越大的聚合状态归一化到单位幅度,然后子层基于归一化后的状态计算输出。这意味着每一层只能访问所有历史信息的压缩混合体,无法选择性地检索早期层的信息。
- 深层效力递减:要在第100层产生与第1层同等的影响力,其输出的绝对幅度需要远大于第1层——因为它要与前99层的累积和“竞争”。这导致深层网络中相当比例的层实际上可以被剪枝(pruning)而几乎不影响性能,说明这些层未能有效学习。
- 信息检索瓶颈:第 $l$ 层只能通过压缩后的 $h_{l-1}$ 访问所有历史信息,无法回溯到特定的早期层。这与人类认知中“需要第几步的结果就回头查”的策略形成鲜明对比。
时间-深度对偶性
AttnRes论文最精彩的理论贡献之一,是建立了时间维度与深度维度的对偶性:
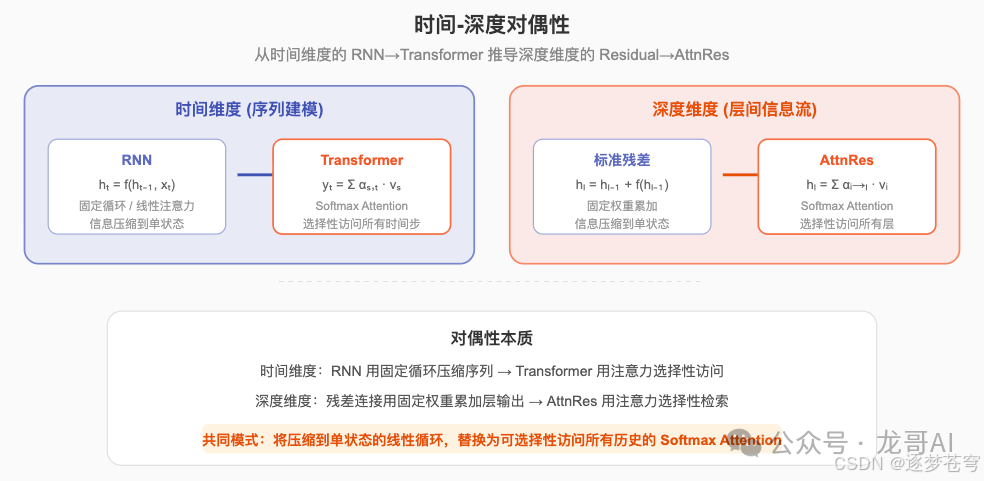
- 在时间(序列)维度上:
- RNN 用固定的循环函数 $h_t = f(h_{t-1}, x_t)$ 压缩序列信息到单个状态向量
- Transformer 用 Softmax Attention $y_t = \sum_{s \le t} \alpha_{s,t} \cdot v_s$ 选择性地访问所有历史时间步
- 在深度维度上:
- 标准残差 用固定权重 $h_l = h_{l-1} + f(h_{l-1})$ 将层输出压缩到单个累积状态
- AttnRes 用 Softmax Attention $h_l = \sum_{i \le l} \alpha_{i \to l} \cdot v_i$ 选择性地检索所有历史层
这个类比揭示了一个深刻的结构性对称:残差连接就是深度维度的RNN。而我们都知道,Transformer在时间维度上用注意力替代RNN带来了多大的革命。AttnRes提出对深度维度做同样的事。
方法:Attention Residuals
Full Attention Residuals
Full AttnRes的公式清晰而优雅:
$$h_l = \sum_{i \le l} \alpha_{i \to l} \cdot v_i$$
其中注意力权重通过核函数计算:
$$\alpha_{i \to l} = \frac{\kappa(q_l, k_i)}{\sum_{j \le l} \kappa(q_l, k_j)}$$
核函数定义为:
$$\kappa(q, k) = \exp(\frac{q^T k}{\sqrt{d}})$$
每层的查询、键、值定义如下:
$$q_l = W_q^{(l)} \in \mathbb{R}^d, \quad k_i = \text{RMSNorm}(h_i) W_k, \quad v_i = h_i W_v$$
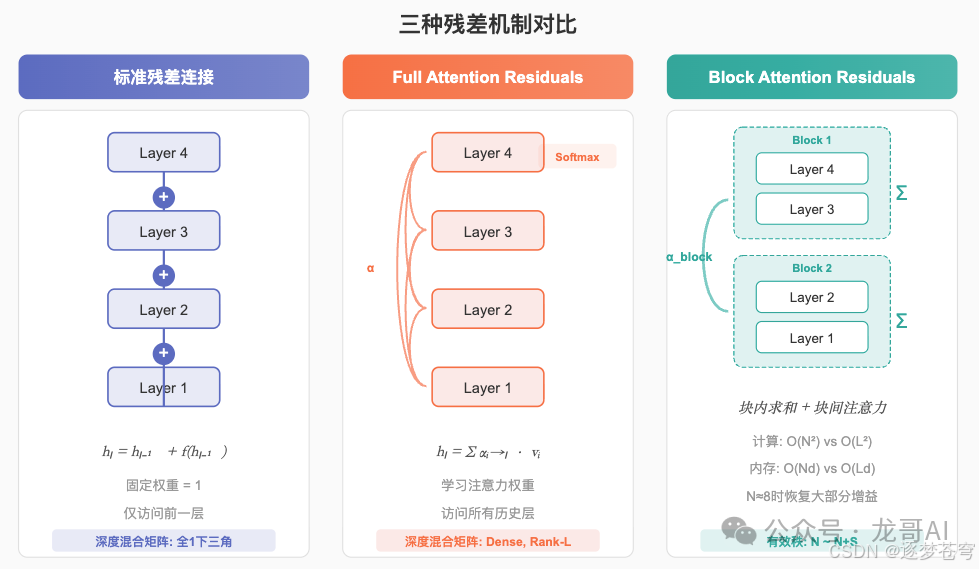
这里有几个精心设计的技术细节值得深入分析:
- 伪查询(Pseudo-query)设计:$W_q^{(l)}$ 是每层独立的可学习参数向量,与前向计算完全解耦。这意味着注意力权重不依赖于当前的输入数据,而是在训练过程中学习到的“最优检索策略”。这个设计看似违反直觉——我们通常期望注意力权重是input-dependent的。但论文的消融实验表明,使用input-dependent查询($q_l = \text{RMSNorm}(h_{l-1})W_q$)虽然能将loss从1.737降到1.731,但引入了一个 $d \times d$ 的投影矩阵,性价比不高。更重要的是,固定查询让训练更稳定。
- RMSNorm的关键作用:对键值 $k_i$ 做RMSNorm归一化,防止大幅度输出主导注意力权重。回忆PreNorm稀释问题——深层的输出幅度远大于浅层。如果不做归一化,注意力权重会天然偏向深层(因为幅度大),这与我们“按内容而非幅度分配权重”的设计目标矛盾。消融实验证实,去掉RMSNorm会使loss从1.737上升到1.743-1.750。
- 零初始化策略:所有伪查询 $W_q^{(l)}$ 必须初始化为零向量。在训练开始时,这使得所有注意力权重均匀分布(因为 $q_l^T k_i$ 对所有 $i$ 相同),等效于标准残差连接(等权求和后归一化)。这保证了训练起步的稳定性,模型从标准残差出发,渐进地学习最优的深度注意力模式。
- Softmax vs Sigmoid:为什么选择softmax而非sigmoid?消融实验显示sigmoid的loss为1.741,高于softmax的1.737。原因在于softmax的竞争归一化特性——当某些层获得更高权重时,其他层的权重自然降低。这种零和竞争隐含了稀疏性,帮助模型聚焦于最相关的层,而sigmoid的各维度独立会导致权重分散。
- 计算复杂度:Full AttnRes的计算复杂度为 $O(L^2)$($L$ 层两两计算注意力),内存为 $O(Ld)$(存储所有层的键值)。对于 $L=128$ 的深层网络,$L^2=16384$,这个开销不可忽视。
Block Attention Residuals
Full AttnRes的 $O(L^2)$ 计算开销促使作者设计了Block AttnRes,这是一个在精度和效率间取得优秀平衡的近似方案。
将 $L$ 层分成 $N$ 个块,每块包含 $S$ 层:$L = N \times S$。
这个两级结构带来了显著的效率提升:
- 内存从 $O(Ld)$ 降到 $O(Nd)$
- 计算从 $O(L^2)$ 降到 $O(N^2)$
- 当 $N=8$ 时,就能恢复Full AttnRes的大部分增益
Block AttnRes有两个优雅的退化极限:
- $S=1$(每块1层):退化为Full AttnRes
- $N=1$(所有层1块):退化为标准残差连接
这意味着Block AttnRes通过 $S$ 这个超参数,在标准残差和Full AttnRes之间形成了一个连续的设计空间。
结构化矩阵视角
论文最具理论深度的贡献之一,是用深度混合矩阵 $M$ 统一分析所有残差变体。$M_{i,l}$ 表示层 $i$ 对层 $l$ 输出的权重。

| 方法 |
矩阵 $M$ 的结构 |
矩阵类别 |
| 标准残差 |
全1下三角矩阵 |
1-semiseparable |
| Highway Network |
$M_{i,l} = \prod_{j=i+1}^{l} (1-g_j) g_i$(stick-breaking) |
1-semiseparable |
| (m)HC |
|
m-semiseparable |
| DenseFormer |
固定标量系数的下三角 |
静态跨层 |
| Full AttnRes |
Dense, Rank-$L$ |
动态跨层 |
| Block AttnRes |
有效秩在 $N$ 和 $N+S$ 之间 |
动态跨层 |
Semiseparable矩阵是Mamba-2论文中用来统一SSM和线性注意力的关键抽象。一个 $m$-semiseparable矩阵的任何子矩阵的秩不超过 $m$,这对应于 $m$ 个并行信息流。在序列建模中,1-semiseparable对应RNN/线性注意力的单状态循环,$m$-semiseparable对应多状态循环(如HC的多流)。
核心洞察:先前的残差变体——无论是标准残差、Highway、还是(m)HC——都是深度维度的线性注意力(因其混合矩阵是semiseparable的,可以用循环形式高效计算)。AttnRes是第一个在深度维度使用Softmax注意力的方法,其混合矩阵是dense的,具有完整的Rank-$L$表达能力。
这个视角完美呼应了时间-深度对偶性:在时间维度上,线性注意力(RNN)→ Softmax注意力(Transformer)带来了质的飞跃。AttnRes在深度维度上重现了同样的演进。
基础设施设计
一个方法论文如果只有理论和小规模实验,往往让人半信半疑。AttnRes论文最令人信服的部分之一,是详细阐述了如何在48B规模的真实训练中落地,将理论开销控制在极低水平。
训练:Cross-stage Caching
大模型训练普遍使用流水线并行(Pipeline Parallelism),将模型的层分布到不同的GPU上。AttnRes需要每层访问所有历史层的块表示,这在流水线并行下意味着跨设备通信。
- 朴素实现的问题:每次流水线阶段转换时,需要传输所有已累积的块表示。设有 $B$ 个micro-batch、$N$ 个块、$P$ 个流水线阶段,朴素通信量为 $O(B^2 N d)$,其中 $d$ 是序列长度——这与micro-batch数量的平方成正比。
- Cross-stage Caching优化:核心思想很简单——本地缓存已接收的块表示,后续只传输增量。每个流水线阶段维护一个缓存,记录已收到的块。当新的micro-batch到来时,只需传输当前阶段新产生的块,而非所有历史块。
- 这个优化将峰值通信从 $O(B^2 N d)$ 降到 $O(B N d)$,改善了 $B/P$ 倍($P$是流水线的虚拟阶段数)。在典型配置下,$B/P \approx 8$,这意味着通信量减少了一个数量级。
- 端到端训练开销:< 4%。考虑到AttnRes带来的收敛速度提升(1.25x计算优势),这个开销完全可以接受。
推理:Two-phase Computation
推理阶段面临不同的挑战——解码是逐token进行的,每个token需要经过所有层,无法利用训练时的批量并行。
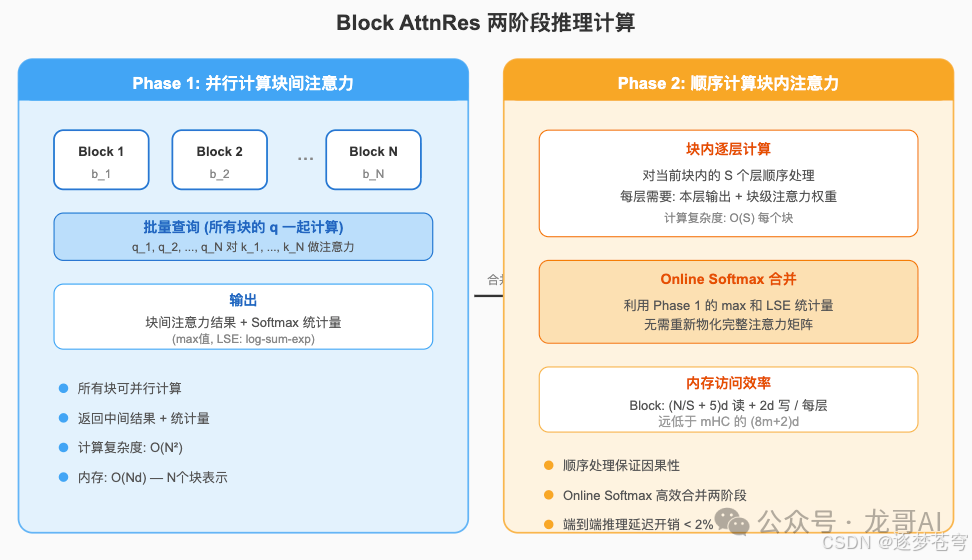
AttnRes的两阶段推理策略:
- Phase 1(并行):批量计算块间注意力。将所有块的伪查询 $q_m$ 打包,一次性对所有块表示做注意力计算。返回加权输出和Softmax统计量(max值和log-sum-exp)。
- Phase 2(顺序):逐层计算块内注意力,利用Online Softmax技术将Phase 1的结果与块内计算合并。Online Softmax的核心思想来自FlashAttention:通过维护running max和log-sum-exp统计量,可以将两部分的softmax结果在数值稳定的前提下合并,无需重新物化完整的注意力矩阵。
每层的内存访问量:$(N/S + 5)d$ 读 + $2d$ 写(Block AttnRes),远低于mHC的 $(6m+2)d$。
端到端推理延迟开销:< 2%。
Memory-efficient Prefilling
长上下文场景下(如128K tokens),块表示的内存占用也不容忽视。AttnRes采用了序列维度分片策略:
- 块表示沿序列维度分片到 $T$ 个Tensor Parallelism设备
- 128K上下文的块表示内存从15GB降到约1.9GB/设备
- 配合Chunked Prefill进一步降到 <0.3GB/设备
这些工程优化保证了AttnRes不仅是理论上优美的方法,更是生产可用的技术。
实验分析
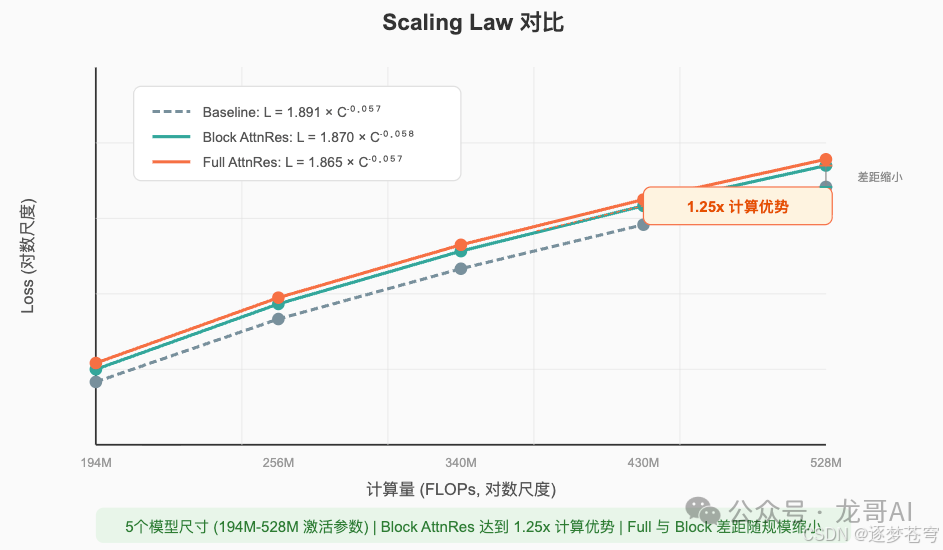
Scaling Laws
论文在5个模型尺寸(194M到528M激活参数)上拟合了Scaling Law曲线:
| 方法 |
Scaling Law |
拟合公式 |
| Baseline |
$L = 1.891 \times C^{-0.057}$ |
标准幂律 |
| Block AttnRes |
$L = 1.870 \times C^{-0.058}$ |
更低截距+更陡斜率 |
| Full AttnRes |
$L = 1.865 \times C^{-0.057}$ |
最低截距 |
关键发现:
- Block AttnRes达到了1.25x计算优势——即相同性能下节省20%的计算量
- Full与Block的差距随规模增大而缩小,说明在大规模下Block AttnRes是性价比最优的选择
- Scaling Law的斜率(指数项)略有改善(-0.058 vs -0.057),暗示AttnRes不仅减小了常数项,还可能改善了scaling的效率
48B模型主结果
在Kimi的48B总参/3B激活的Linear MoE架构上,使用1.4T tokens训练:
| Benchmark |
Baseline |
AttnRes |
提升 |
| GPQA-Diamond |
36.9 |
44.4 |
+7.5 |
| Math |
53.5 |
57.1 |
+3.6 |
| HumanEval |
59.1 |
62.2 |
+3.1 |
| C-Eval |
79.6 |
82.5 |
+2.9 |
| MMLU |
73.5 |
74.6 |
+1.1 |
几个值得注意的观察:
- GPQA-Diamond的巨大提升(+7.5):GPQA是需要深度推理的研究生级别科学问答。7.5个百分点的提升表明,AttnRes显著增强了模型的深度推理能力。这与我们的直觉一致——选择性的层间信息检索让模型能更好地利用中间层的计算结果。
- 全面提升:所有benchmark都有正向提升,没有任何任务出现退化。这说明AttnRes不是特定任务的trick,而是通用的架构改进。
消融实验
16层模型上的消融实验揭示了大量设计细节:
| 配置 |
Validation Loss |
| Baseline(标准残差) |
1.767 |
| DenseFormer(固定标量系数) |
1.767(无增益) |
| mHC(m并行流+混合矩阵) |
1.747 |
| Full AttnRes |
1.737 |
| Full AttnRes + input-dependent query |
1.731 |
| AttnRes + sigmoid替代softmax |
1.741 |
| AttnRes + 多头注意力(H=16) |
1.752 |
| AttnRes 去掉RMSNorm |
1.743/1.750 |
| AttnRes + 滑动窗口SWA(W=1+8) |
1.764 |
深度值得玩味的消融结论:
- DenseFormer完全无效(1.767 = Baseline):DenseFormer使用固定的标量权重做层间加权平均(Depth-Weighted Average)。它在NeurIPS 2024上发表,声称无需增加模型大小即可提升性能。但在这个对比中完全失效。原因在于它的权重是静态的——训练后固定,无法动态适应。这与AttnRes的动态注意力权重形成鲜明对比。
- 多头注意力反而更差(1.752 vs 1.737):这个结果非常反直觉。在标准注意力中,多头机制是关键。但在深度注意力中,最优的深度混合模式是跨通道一致的——所有hidden dimension应该使用相同的深度注意力权重。这说明深度维度的混合不同于序列维度:每个位置可以关注不同的上下文(多头有意义),但在深度维度上,哪些层重要这个决策应该是全局统一的。
- 滑动窗口远不如全注意力(1.764 vs 1.737):限制每层只能访问附近的8层(SWA, W=1+8)导致大幅性能下降。这直接证明了远距离层访问的重要性——模型需要跨越多个块回溯到早期层。这与序列注意力中长距离依赖的重要性完全类比。
最优架构分析
一个特别有价值的实验是AttnRes对最优架构配置的影响。论文在25种 $d/L$(宽度/深度)配置上做了系统搜索。
关键发现:
- AttnRes将最优 $d/L$ 比值从60移到45——即最优架构变得更深更窄
- 在所有25个配置上,AttnRes都优于baseline
这是一个重要的架构指导信号。标准残差由于PreNorm稀释,深层效率低下,所以最优配置偏向“宽而浅”。AttnRes解决了深层效力递减的问题,使得“窄而深”的配置变得更有效率。更深的网络意味着更多的计算步骤,在参数量相同的情况下,可以实现更复杂的计算。
训练动态分析
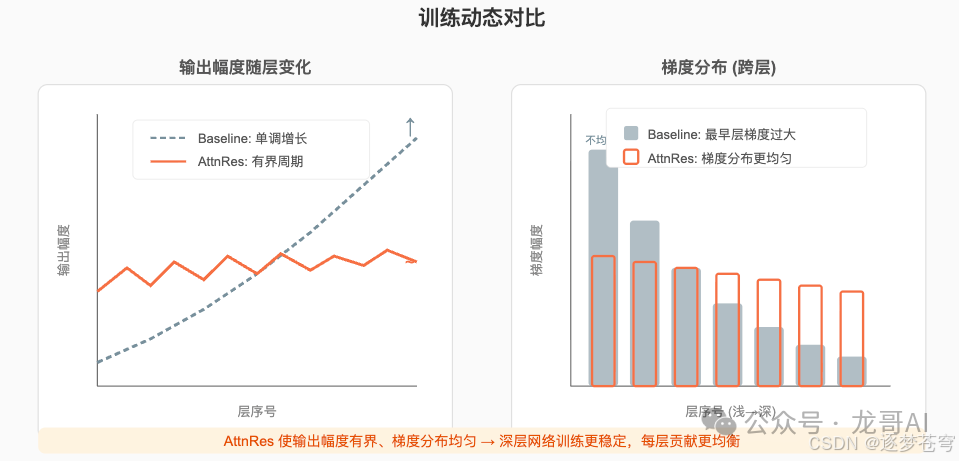
训练动态的观察为AttnRes的机制提供了直观的解释:
- 输出幅度:Baseline的层输出幅度随深度单调增长——深层必须产生越来越大的输出才能在越来越大的累积和中“被看见”。AttnRes的输出幅度呈现有界周期模式——因为注意力权重的softmax归一化天然控制了幅度增长。这不仅改善了数值稳定性,也说明每层都能平等地贡献信息。
- 梯度分布:Baseline的最早层梯度不成比例地大——这是因为反向传播时,浅层参数同时影响所有深层的输入(通过残差连接的恒等映射)。AttnRes的梯度分布更加均匀,每层获得的学习信号更加平衡。
与相关工作的统一对比
AttnRes论文的一个突出贡献是提供了一个统一视角来理解所有残差变体。我们可以从方法论的演进脉络来组织这些工作。
单状态循环方法
这类方法保持单个残差流,对应1-semiseparable混合矩阵:
- 标准残差(He et al., 2016):$h_l = h_{l-1} + f(h_{l-1})$。固定权重,无选择性,深度维度的“最简RNN”。
- Highway Network(Srivastava et al., 2015):引入门控机制 $g_t$。在深度维度上实现了“stick-breaking attention”——一种线性注意力的特殊形式。但门控只在相邻层之间操作,无法跨层访问。
- DeepNorm(Wang et al., 2022):$h_l = \alpha h_{l-1} + f(h_{l-1})$,通过调整残差权重 $\alpha$ 改善深层网络的训练稳定性。本质上仍是固定权重。
这些方法的根本局限在于:它们的混合矩阵是1-semiseparable的,表达能力受限于单状态循环,无法实现选择性的远距离层访问。
多状态循环方法
这类方法将单个残差流扩展为多个并行流,对应m-semiseparable混合矩阵:
- Hyper-Connections (HC)(字节跳动, 2024, ICLR 2025):将维度 $d$ 的残差流扩展为 $m$ 的多流,通过学习的混合矩阵在层间传递信息。HC的核心思想是让信息在多条“车道”上流动,每条车道可以承载不同粒度的信息。
- mHC(DeepSeek, 2025):HC的训练不稳定问题源于无约束的混合矩阵会在层间累积,导致信号幅度指数增长或衰减——看似无害的每层5%放大,经过60层后变成18倍。mHC的核心创新是用流形约束解决这个问题:通过Sinkhorn-Knopp算法将混合矩阵投影到双随机矩阵流形上,保证信号增益在任意深度都接近理论理想值1.0x。代价是4倍宽残差流增加约6.7%的训练时间。
多状态方法的局限在于:尽管增加了信息流的带宽(从1流到m流),但每条流仍是顺序传播的(semiseparable结构),无法实现像Full AttnRes那样的“随机访问”。并且,多流设计引入了显著的内存和计算开销。
跨层访问方法
这类方法允许直接访问任意历史层,是AttnRes的直接前辈:
- DenseFormer(EPFL, NeurIPS 2024):在每个Transformer Block后添加Depth-Weighted Average(DWA)操作,计算当前和所有历史表示的加权平均。权重是训练后固定的标量系数。DenseFormer的理念正确——需要跨层信息访问——但使用静态权重是其致命弱点。在AttnRes的消融中,DenseFormer式的固定系数完全没有增益(loss与baseline持平)。
- MRLA(Multi-Resolution Layer Aggregation):使用动态权重的跨层访问。与AttnRes最相似,但具体的注意力机制设计不同。
- AttnRes:第一个在深度维度使用完整Softmax Attention的方法。与前辈方法相比,AttnRes的优势在于:
- Softmax的竞争归一化产生隐含稀疏性,自动聚焦关键层
- RMSNorm防止幅度偏差
- Block设计兼顾效率与精度
- 完整的工程落地方案确保生产可用
| 方法 |
权重类型 |
信息源 |
矩阵结构 |
类别 |
| Residual |
固定 |
$h_{l-1}$ |
1-semisep |
单状态循环 |
| Highway |
动态 |
$h_{l-1}$ |
1-semisep |
单状态循环 |
| DeepNorm |
固定 |
$h_{l-1}$ |
1-semisep |
单状态循环 |
| HC/mHC |
动态 |
m streams |
m-semisep |
多状态循环 |
| DenseFormer |
静态 |
所有层 |
静态跨层 |
跨层访问 |
| AttnRes |
动态 |
所有层 |
Dense |
跨层注意力 |
讨论与展望
局限性分析
AttnRes并非没有局限:
- 计算开销的权衡:尽管Block AttnRes的额外计算开销很低(<4%训练,<2%推理),但Full AttnRes的 $O(L^2)$ 复杂度在超深网络(如1000层)中可能成为瓶颈。Block设计是一个好的折中,但最优的块大小 $S$ 的选择仍需经验调优。
- 固定查询的表达能力:伪查询 $W_q^{(l)}$ 是不依赖输入的可学习参数。虽然论文证明这在大多数场景下足够好,但某些需要根据输入内容动态调整层间信息检索策略的任务,可能会从input-dependent查询中获益更多。消融显示差距为0.006 loss,在更大模型或更复杂任务上这个差距是否会扩大值得关注。
- 与其他架构创新的兼容性:AttnRes主要在标准Transformer和MoE架构上验证。它与其他架构创新(如线性注意力变体、状态空间模型等)的兼容性尚待验证。
研究方向展望
- 更高效的深度注意力机制:能否设计线性复杂度的深度注意力?例如使用线性注意力核(类似序列维度上的线性Transformer)或稀疏注意力模式。滑动窗口的失败表明,这需要比简单的局部注意力更巧妙的稀疏模式。
- 深度-宽度-注意力联合搜索:AttnRes改变了最优的深度/宽度比。一个自然的问题是:在给定计算预算下,深度、宽度、注意力头数和深度注意力粒度($S$)的最优联合配置是什么?这需要更大规模的架构搜索。
- 与训练范式的协同:AttnRes对长序列推理(Chain-of-Thought)、强化学习微调(RLHF)等下游训练范式有何影响?更好的层间信息流是否能增强模型的推理链路?GPQA-Diamond上+7.5的提升给出了令人鼓舞的初步信号。
技术演进的启示
从更宏观的视角看,残差连接的演进路径揭示了深度学习架构设计的一个普遍范式:
- 先有简单有效的基础组件(残差连接, 2015)
- 发现其在规模化时的瓶颈(PreNorm稀释, 深层效力递减)
- 从其他维度的成功方案中类比解法(时间维度: RNN→Attention)
- 在目标维度应用同样的范式升级(深度维度: Residual→AttnRes)
这个范式提醒我们:当前架构中还有多少组件停留在“基础版”?每个维度上的信息聚合策略,都值得用同样的思路重新审视。
总结
Attention Residuals是一个理论优雅、工程扎实、实验充分的工作。它的核心贡献可以概括为三个层面:
- 理论层面:建立了时间-深度对偶性,揭示了标准残差连接是深度维度的RNN,并自然推导出用Softmax Attention替代的方案。结构化矩阵视角统一了所有残差变体方法。
- 方法层面:提出Full AttnRes和Block AttnRes两种实现,通过精心设计的伪查询、RMSNorm、零初始化等技术保证了训练稳定性和有效性。Block AttnRes在精度和效率间取得了极佳的平衡。
- 工程层面:Cross-stage Caching、Two-phase Computation、Memory-efficient Prefilling三大优化使得AttnRes在48B规模模型上仅增加<4%训练和<2%推理开销,完全达到了生产部署标准。
在48B MoE模型上,AttnRes在GPQA-Diamond上取得了+7.5的提升,在所有benchmark上全面正向。Scaling Law显示1.25x的计算优势。这些结果有力地证明:十年未变的残差连接,确实到了该升级的时候。对于希望深入探讨这类架构创新落地与未来趋势的开发者,欢迎前往云栈社区的人工智能板块,与其他同行交流实践心得。
 发表于 2026-3-24 08:43:20
|
查看: 122|
回复: 0
发表于 2026-3-24 08:43:20
|
查看: 122|
回复: 0
