本次测试基于 Kilo Code 完成。这是一款免费开源 AI 编程助手,支持 VS Code 与 JetBrains。
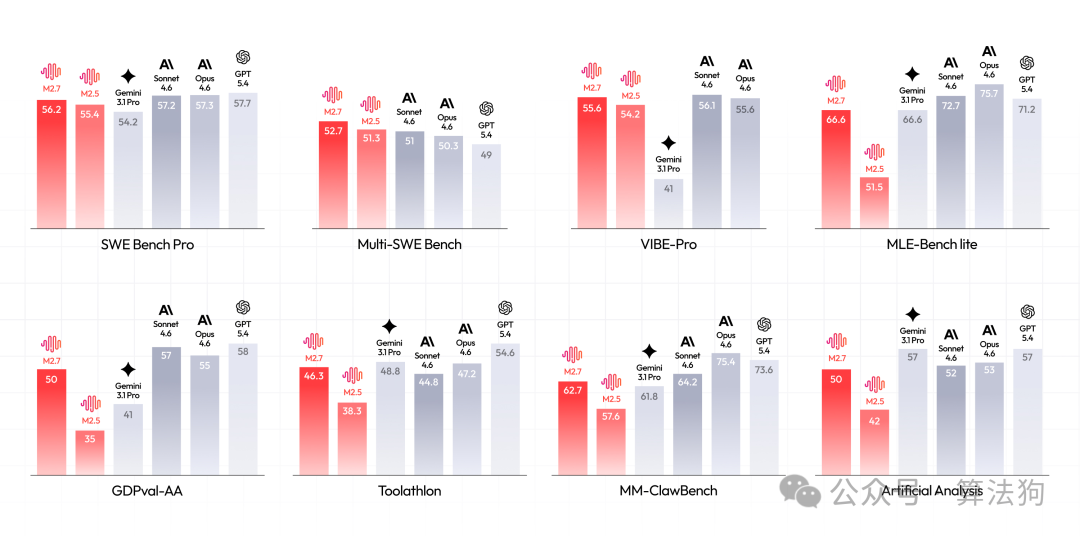
MiniMax M2.7 于 3 月 18 日正式发布,在 SWE-Pro 基准测试中拿下 56.22% 的成绩,与 Claude Opus 4.6 的表现已十分接近。光看跑分不够,我们直接在 Kilo Code 平台上,让两款模型完成三项硬核编程任务,看看基准分数在实际开发场景中到底如何。
先看价格,差距显著:MiniMax M2.7 计费为每百万 tokens 0.30/1.20 美元(输入/输出),而 Claude Opus 4.6 则高达 5/25 美元。输入成本相差约 17 倍,输出成本相差约 21 倍。
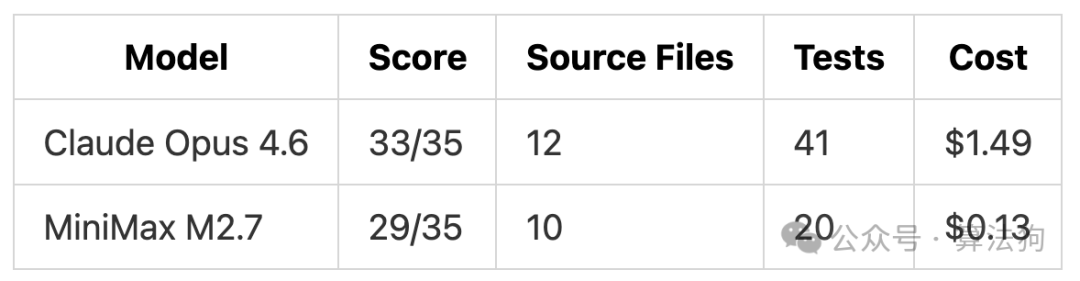
一句话总结实测结果:两款模型在本次测试中均成功定位了全部 6 个 Bug 与全部 10 个安全漏洞。Claude Opus 4.6 的修复方案确实更完善,测试用例数量直接多出一倍。但 MiniMax M2.7 以 7% 的成本实现了 90% 的核心质量(总花费 0.27 美元 vs 3.67 美元),性价比突出。
测试设计:三场硬仗,公平对决
我们创建了三个独立的 TypeScript 代码库,在 VS Code 版 Kilo Code 的代码模式下分别运行两款模型。两者使用完全相同的提示词,无任何额外提示或人工干预。所有测试完成后,依据预设标准对模型输出进行独立打分。
- 测试 1:全栈事件处理系统(35 分) —— 根据详细需求文档从零构建完整系统,要求包含异步流水线、WebSocket 流与限流等复杂功能。
- 测试 2:基于现象的 Bug 排查(30 分) —— 仅提供生产日志输出和现象,要求定位 6 个预埋 Bug 的根因并完成修复。
- 测试 3:安全审计(35 分) —— 在模拟的团队协作 API 中,找出并修复 10 个预埋的安全漏洞。
测试 1:全栈事件处理系统 — 架构与测试的差距
我们向两款模型给出完全相同的提示:
“根据 @SPEC.md 中的规范,使用 TypeScript 构建实时事件处理系统。Web 框架使用 Hono,数据库采用 Prisma + SQLite,输入校验使用 Zod,WebSocket 依赖 ws 库。”
需求文档明确要求实现 7 个核心模块:带 API 密钥鉴权的事件接入 API、带指数退避重试的异步处理流水线、带处理历史的事件存储、带分页与筛选的查询 API、实时流 WebSocket 接口、按密钥限流、健康与指标接口。
两款模型都成功实现了所有 7 个模块,基础功能完备。但得分差异主要来自代码结构与测试覆盖率。
架构设计:模块化 vs 扁平化
Claude Opus 4.6 构建了一套清晰的模块化目录结构,将路由、流水线、中间件、WebSocket 管理分门别类存放。处理逻辑被拆分为独立的队列管理文件(内含重试调度与死信路由)和按类型的事件处理器,并且支持优雅关闭与定时器清理,考虑周全。
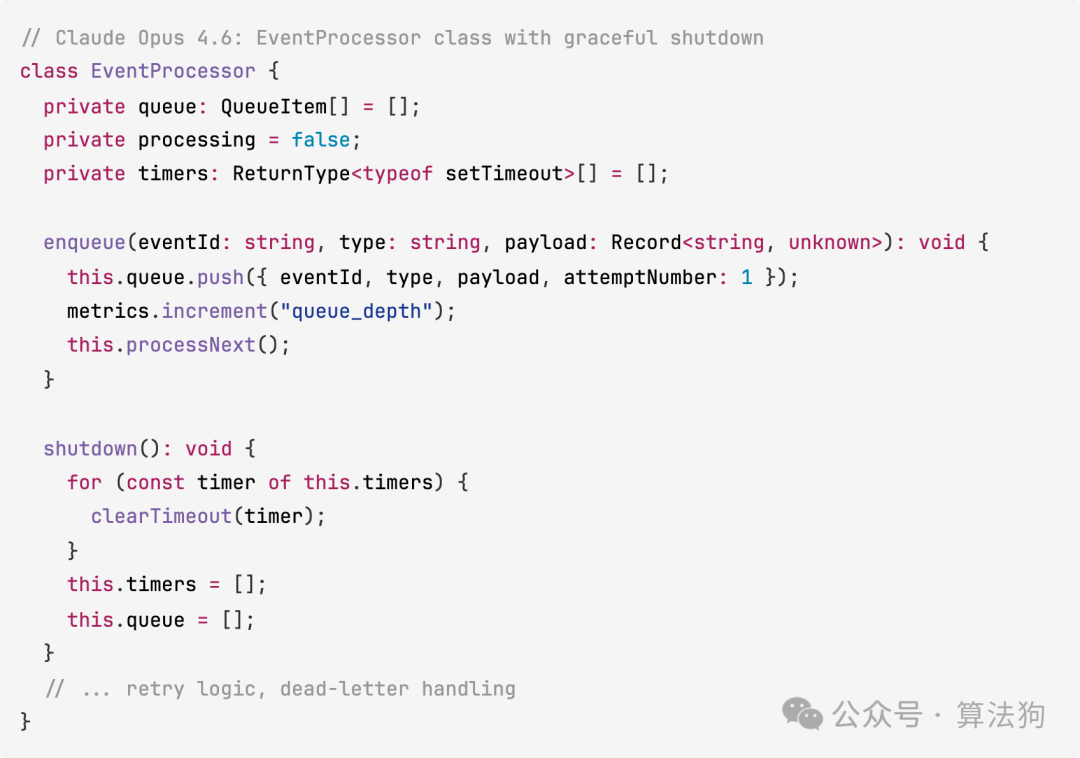
// Claude Opus 4.6: EventProcessor class with graceful shutdown
class EventProcessor {
private queue: QueueItem[] = [];
private processing = false;
private timers: ReturnType<typeof setTimeout>[] = [];
enqueue(eventId: string, type: string, payload: Record<string, unknown>): void {
this.queue.push({ eventId, type, payload, attemptNumber: 1 });
metrics.increment("queue_depth");
this.processNext();
}
shutdown(): void {
for (const timer of this.timers) {
clearTimeout(timer);
}
this.timers = [];
this.queue = [];
}
// ... retry logic, dead-letter handling
}
MiniMax M2.7 则采用了更扁平的结构,文件数量更少。所有路由集中在单个入口文件,处理器逻辑也更直接,没有实现关闭管理和定时器追踪这类进阶功能。
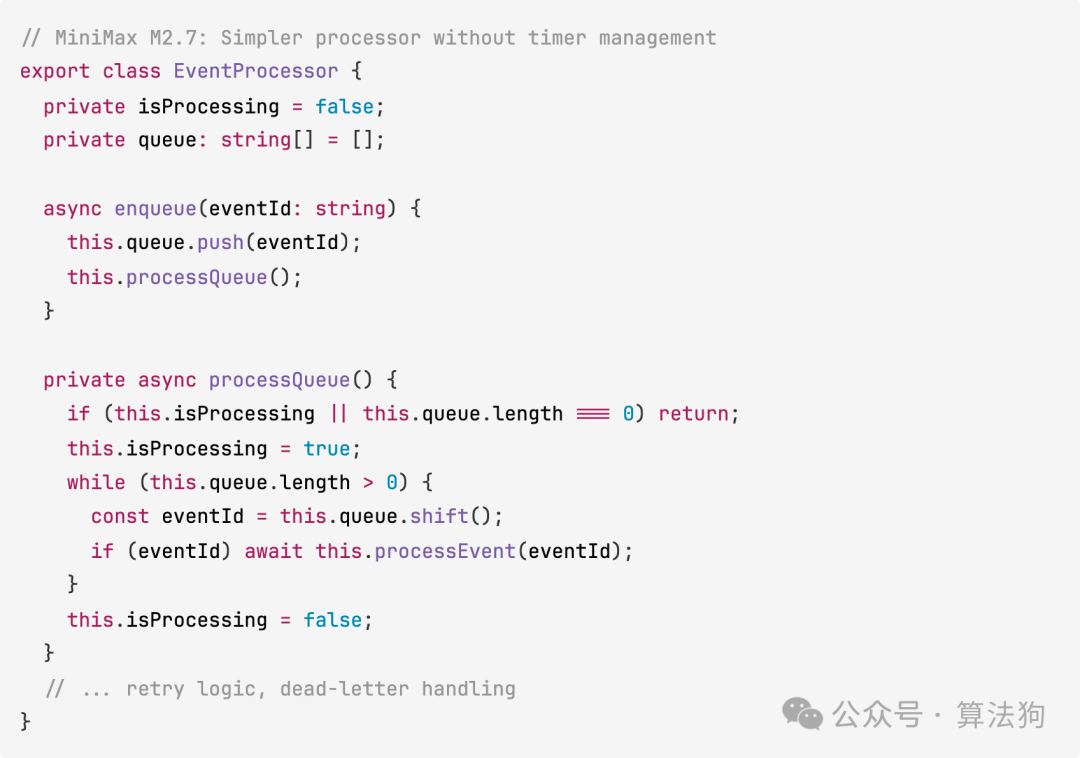
// MiniMax M2.7: Simpler processor without timer management
export class EventProcessor {
private isProcessing = false;
private queue: string[] = [];
async enqueue(eventId: string) {
this.queue.push(eventId);
this.processQueue();
}
private async processQueue() {
if (this.isProcessing || this.queue.length === 0) return;
this.isProcessing = true;
while (this.queue.length > 0) {
const eventId = this.queue.shift();
if (eventId) await this.processEvent(eventId);
}
this.isProcessing = false;
}
// ... retry logic, dead-letter handling
}
测试覆盖率:41个集成测试 vs 20个单元测试
Claude Opus 4.6 直接写了 41 个集成测试,使用独立的测试数据库,并在测试间完成完整的数据清理。测试通过发起真实的 HTTP 请求来调用 API,端到端验证了整个中间件链路。

// Claude Opus 4.6: Integration test hitting the real API
it("should return 429 when rate limit is exceeded", async () => {
for (let i = 0; i < 3; i++) {
await request("POST", "/events", {
headers: { "X-API-Key": "TEST_API_KEY_LIMITED" },
body: validPayload,
});
}
const res = await request("POST", "/events", {
headers: { "X-API-Key": "TEST_API_KEY_LIMITED" },
body: validPayload,
});
expect(res.status).toBe(429);
expect(res.headers.get("Retry-After")).toBeTruthy();
});
MiniMax M2.7 编写了 20 个单元测试,直接校验 Zod schema 和处理函数。虽然覆盖了核心逻辑,但没有通过 HTTP 测试 API 接口和中间件,这意味着路由或中间件层的潜在 Bug 可能无法被发现。
测试 1 得分:细节定胜负
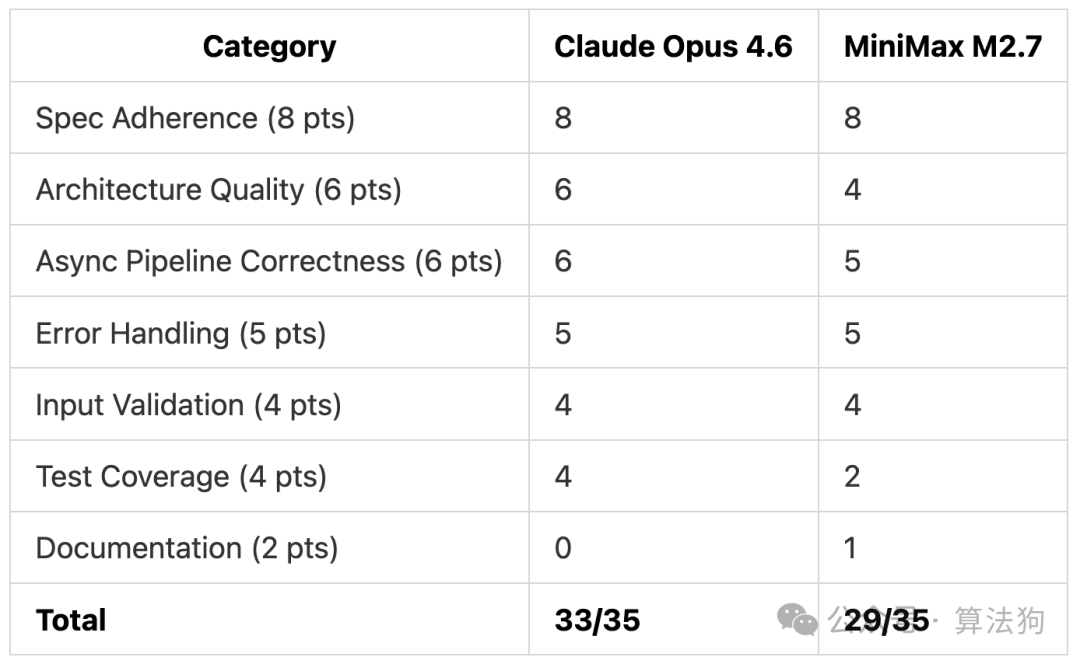
Claude Opus 4.6 因为未生成 README 文件(需求文档明确要求)被扣了 2 分。MiniMax M2.7 生成了 README,但在架构设计与测试覆盖率上失分较多,最终得分落后。
测试 2:基于现象的 Bug 排查 — 诊断能力打了个平手
我们构建了一个包含 4 个关联模块(网关、订单、库存、通知)的订单处理系统,并预埋了 6 个隐蔽的 Bug。只向两款模型提供代码库、展示异常现象的生产日志以及内存增长数据。提示词仅仅列出了 6 种现象,要求它们自行排查根因并修复。
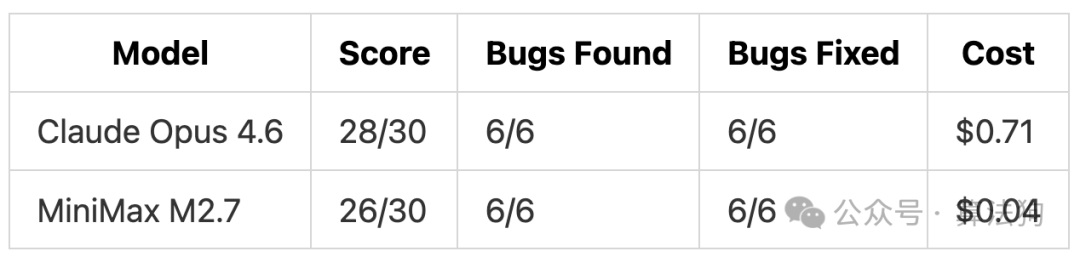
这轮比拼的结果持平。两款模型均成功定位了全部 6 个问题的根因,诊断能力上打了个平手(28分 vs 26分)。
Bug 1:库存竞态条件 — 细节见真章
系统原本先校验库存,再在一个独立的事务中锁定库存。这会导致并发订单可能同时通过校验,引发超卖。两款模型都从日志中识别出了这个问题,并通过原子化锁定完成了修复。
但细节上拉开了差距:
- Claude Opus 4.6 额外增加了回滚逻辑:在多商品订单中,如果某一件商品库存锁定失败,它会释放已锁定的其他商品,并将整个订单标记为失败。
- MiniMax M2.7 实现了原子锁定,但未添加回滚机制,可能导致部分失败时产生无效的库存占用。
Bug 4:浮点数计算误差 — MiniMax 竟有惊喜
订单总价使用标准浮点数运算,导致部分价格与数量组合会出现像 159.92000000000002 这样的精度问题。日志中反复出现“总价校验警告”就是线索。
Claude Opus 4.6 的修复是在计算后对结果进行四舍五入:

function calculateTotal(items: { price: number; quantity: number }[]): number {
const raw = items.reduce((sum, item) => sum + item.price * item.quantity, 0);
return Math.round(raw * 100) / 100;
}
MiniMax M2.7 则转换了思路,直接转为整数运算(以分为单位),从根源上避免了精度问题:

function calculateTotal(items: { price: number; quantity: number }[]): number {
const totalCents = items.reduce((sum, item) => sum + Math.round(item.price * 100) * item.quantity, 0);
return totalCents / 100;
}
从技术角度看,MiniMax M2.7 的方案反而更优。以分为单位计算可以彻底避免大额订单中,即使四舍五入也可能残留的累积误差。
其余 Bug:思路高度一致
两款模型对剩余 4 个 Bug 的修复思路基本一致:
- 通知顺序问题(Bug 2):在发送确认邮件前增加状态校验,跳过已取消的订单。
- 内存泄漏(Bug 3):移除未清理的单订单事件监听器(内存数据显示监听器数量与请求数 1:1 增长)。
- 库存缓存过期(Bug 5):库存更新后主动清理缓存,避免依赖 60 秒 TTL 导致脏数据。
- 令牌吊销绕过(Bug 6):移除所谓的“5 分钟优化”逻辑,不再跳过对新令牌的吊销检查。
测试 2 得分:解释风格有差异

两款模型都用 curl 请求验证了修复效果。Claude Opus 4.6 在解释每个 Bug 时,会明确引用日志中的具体条目;而 MiniMax M2.7 则更直接地切入代码分析,风格更务实。
测试 3:安全审计 — 修复质量是分水岭
我们构建了一个团队协作 API(Hono + Prisma + SQLite),预埋了 10 个典型的安全漏洞。要求两款模型审计代码库,按 OWASP 分类、说明攻击向量、评估严重性并实现修复。
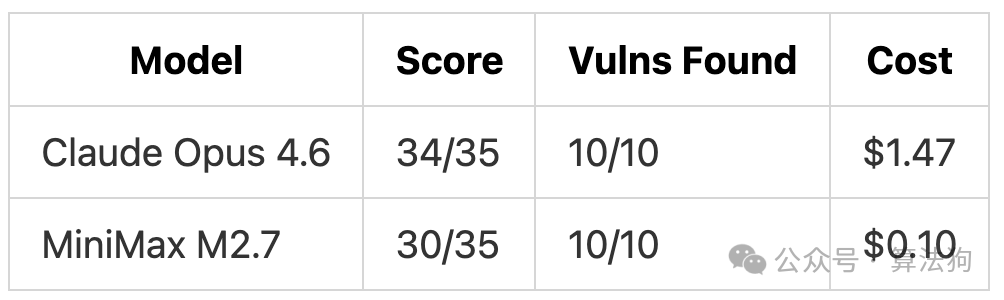
在漏洞发现能力上,两款模型再次打成平手,均找出了全部 10 个漏洞并完成了正确的 OWASP 分类。4 分的差距完全来自于修复方案的完善度。
修复方案差异:生产级 vs 够用级
- 密码哈希:Claude Opus 4.6 使用 scrypt 算法+随机盐+时序安全比对;MiniMax M2.7 使用 SHA-256 并以 JWT 密钥为盐,并且在输出中主动提示“使用 bcrypt 更佳”。
- 不安全反序列化:两者都移除了 webhook 转换中的危险
eval();但 Claude Opus 4.6 替换为更安全、保留功能的 JSON 键映射系统,而 MiniMax M2.7 则直接禁用了转换功能。
- SSRF 防护:Claude Opus 4.6 在创建、更新、发送三个环节都校验 webhook URL,实现深度防御;MiniMax M2.7 仅在发送时进行校验。
- 限流:Claude Opus 4.6 对登录、注册、重置密码等敏感接口分别实施限流;MiniMax M2.7 仅对登录接口进行了限流。
- JWT 修复:两者都将硬编码密钥移至环境变量;Claude Opus 4.6 直接使用
jwt.verify() 的原生过期校验;MiniMax M2.7 则修复了手动过期比对的逻辑,功能可用,但相当于重复实现了库的内置能力。
测试 3 得分

整体结果与成本分析
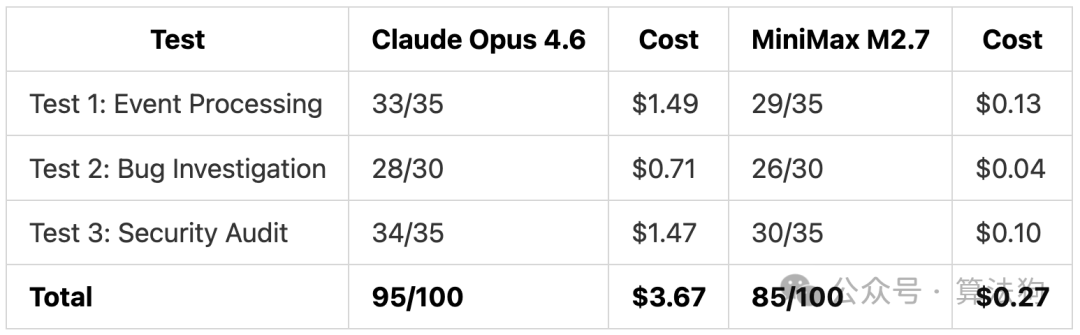
整体评价:MiniMax M2.7,展现出对标潜力的关键版本
这次的 MiniMax M2.7,可以说是首个真正值得拿来对标前沿闭源模型的版本。在本次实测中,它与 Claude Opus 4.6 在问题检出率上完全一致,能定位相同的 Bug 与漏洞。尽管在修复方案的完善度上仍有可见差距,但开源权重模型与前沿闭源模型在诊断能力上的鸿沟,正在以肉眼可见的速度缩小。如果你对这类AI模型对比感兴趣,可以关注云栈社区的人工智能板块,获取更多深度分析。
核心结论与选择建议
- 从零构建项目:追求极致质量?选 Claude Opus 4.6,它提供了 41 个集成测试与清晰的模块化架构,在架构设计上更胜一筹。追求极致性价比?MiniMax M2.7 实现了相同核心功能,用 20 个单元测试+扁平结构,成本仅需 0.13 美元(对比 Opus 的 1.49 美元)。
- Bug 调试:两者均能从日志准确定位全部 6 个根因。有趣的是,MiniMax M2.7 对浮点数 Bug 的修复方案(转整数运算)技术上更优;而 Claude Opus 4.6 在竞态条件修复中补充的回滚逻辑更周全。
- 安全审计:两者都能找出全部 10 个漏洞。Claude Opus 4.6 的修复更贴近生产标准(合理密钥派生、保留必要功能、实施深度防御)。MiniMax M2.7 采用了更简单直接的方案,有时甚至会主动提示自己的处理是简化版。
- 成本对比:这是最硬核的数据——Claude Opus 4.6 完成全部测试总花费 3.67 美元,而 MiniMax M2.7 仅需 0.27 美元。两者在问题检出能力上完全一致,主要差距体现在修复的完善度与工程细节上。
如何选择,最终取决于你的具体场景和预算。是愿意为那10%的完善度支付十几倍的成本,还是用极低的代价获得90%可用的核心解决方案?这笔账,值得每个开发者和技术决策者仔细算算。欢迎在云栈社区分享你的看法和实践经验。
 发表于 2026-3-25 02:46:54
|
查看: 185|
回复: 0
发表于 2026-3-25 02:46:54
|
查看: 185|
回复: 0
