你可能每天都在使用各种大模型,但如果被问到下面这几个问题,你能立刻给出清晰的答案吗?
- 一个标榜拥有 40 万上下文窗口(Context Window) 的模型,到底能输入多少内容?
- 我们常说的 Token,和“字数”、“单词数”之间,到底是什么换算关系?
- 为什么同一句话,有时显得“很费Token”?
很多人对这些概念只有一个模糊的印象。但实际上,理解 Token 是理解大模型能力边界和成本计算的第一把钥匙。它远不止是一个技术术语,更是智能时代信息计量、定价和交易的基础单元。
更重要的是,这个概念已经从“技术黑话”正式进入了国家级标准体系。就在前不久,国家数据局在官方发布中首次明确了 Token 的标准中文译名——“词元(Ciyuan)”。
这意味着,无论你是开发者、研究者还是普通用户,现在都需要对“词元”有一个准确的认识。
一、Token(词元)到底是什么?
简单来说,Token(词元)是大模型处理信息的最小信息单元。它就像人类语言中的“词”或“字”,但对于模型而言,它是可计量、可操作的数字基础。
国家数据局的统计数据显示,这个词元的使用量正在呈爆炸式增长:从2024年初的日均1000亿调用量,跃升至2025年底的100万亿,并在今年3月突破了140万亿,短短两年增长超千倍。
但这里有一个必须纠正的核心误区:Token 不等于“字”,也不等于“词”,更不等于简单的“字符数”。很多人会下意识地认为 1个Token就是1个汉字,实际情况要复杂得多。
Token 的产生依赖于一个关键组件:Tokenizer。
它的核心作用有两步:
- 把一段连续的文本切分成一个个独立的 Token。
- 将这些 Token 映射为模型能够理解的数字。
举个例子,我们输入一句话:“马克喜欢人工智能吗”。通过 OpenAI 官方的 Tokenizer 工具 可以看到,这句话被处理后的结果:
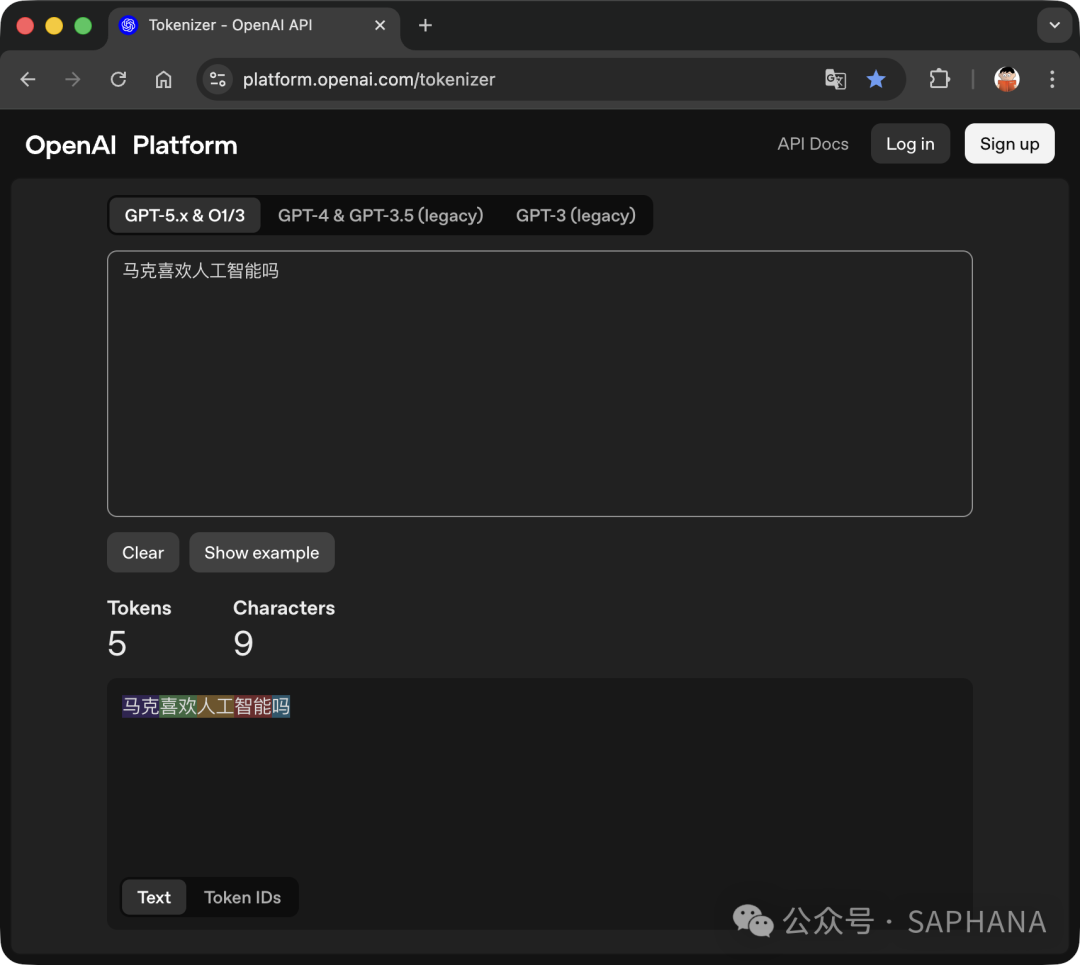
处理过程可以理解为将句子切分为:
马克喜欢人工智能吗
👉 最终,这个9个字的句子被转换成了 4 个 Token(词元)。
二、大模型的基本工作原理:从文字到数字
要真正理解 Token,我们必须先理解大模型是如何工作的。本质上,当前的大语言模型是一个极其复杂的数学函数,其内部充斥着矩阵运算和向量计算。它的一个根本特性是:
👉 关键在于,模型本身并不“理解”人类文字语言,它只处理数字。
那么,我们的人类语言是如何被模型处理的呢?桥梁就是 Tokenizer。它在模型与人类之间扮演着“翻译官”的角色,具备两个核心功能:
| 功能 |
作用 |
| 1️⃣ 编码(Encoding) |
把人类可读的文字转换为模型可处理的数字 |
| 2️⃣ 解码(Decoding) |
把模型输出的数字转换回人类可读的文字 |
这个过程是一个完整的 pipeline,如下图所示:
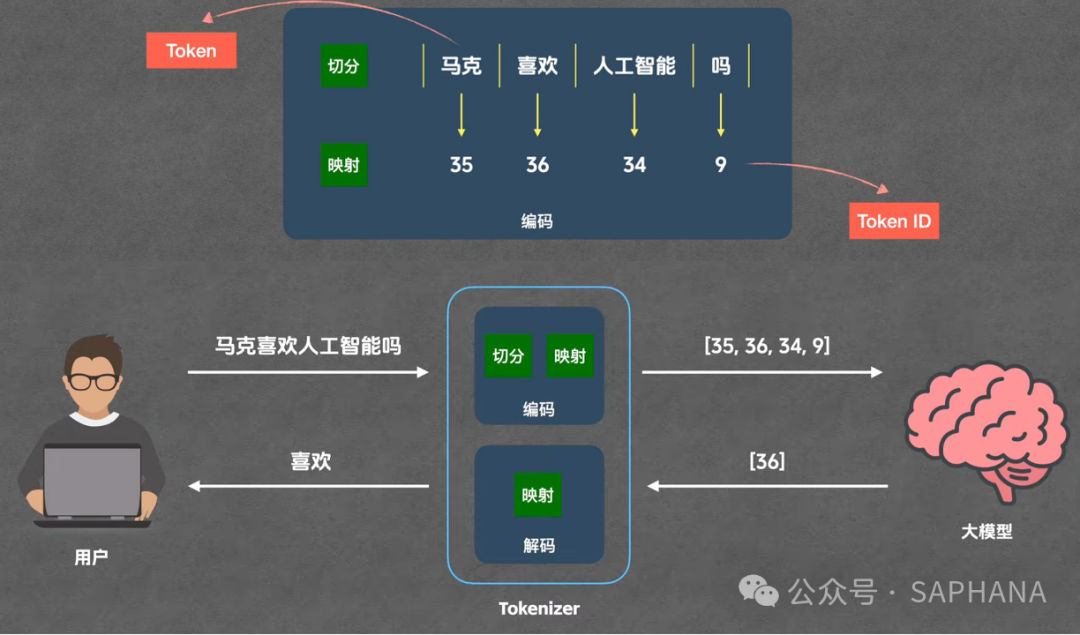
我们以问题 “马克喜欢人工智能吗” 为例,分解一下完整流程:
第一步:编码(Encoding)
编码过程包含两个子步骤:
(1)切分
将输入的句子拆分成独立的 Token 单元。对于我们的例子,可能被拆分为:
马克喜欢人工智能吗
(2)映射
将每个 Token 映射为一个唯一的数字编号,即 Token ID。
马克 → 35喜欢 → 36人工智能 → 34吗 → 9
👉 注意:Token 是“文字片段”,Token ID 是与之对应的“数字编号”,两者一一对应。Token ID 本身没有语义,它只是一个索引。
第二步:模型计算
Tokenizer 将得到的 Token ID 列表 [35, 36, 34, 9] 传给大模型。模型内部进行海量的矩阵运算后,会输出下一个最可能的 Token ID,例如 [36]。
第三步:解码(Decoding)
Tokenizer 收到模型输出的 Token ID (如 36),通过查表反向映射,得到对应的 Token 文字 喜欢,并呈现给用户。
关于输出方式:你平时使用AI时可能已经注意到,模型通常不是一个字一个字或一个词一个词地蹦出来。实际上,模型是一次生成一个Token。由于现在生成速度很快,这个逐Token生成的过程有时不易被察觉。理解 Transformer 架构的运作机制,能帮助你更深入地理解这种自回归生成过程。
三、Tokenizer 是如何被训练出来的?
很多人觉得 Tokenizer 很神秘,其实它的训练原理远比大模型本身简单。常见的训练算法有 Unigram 和 BPE(Byte Pair Encoding,字节对编码)。通常,Google 系模型常用 Unigram,而 OpenAI、Anthropic 等则常用 BPE。
BPE 算法的核心思想非常直观:找出训练语料中经常一起出现的字或子词,然后把它们合并成一个新的、更大的 Token。
BPE 训练步骤详解
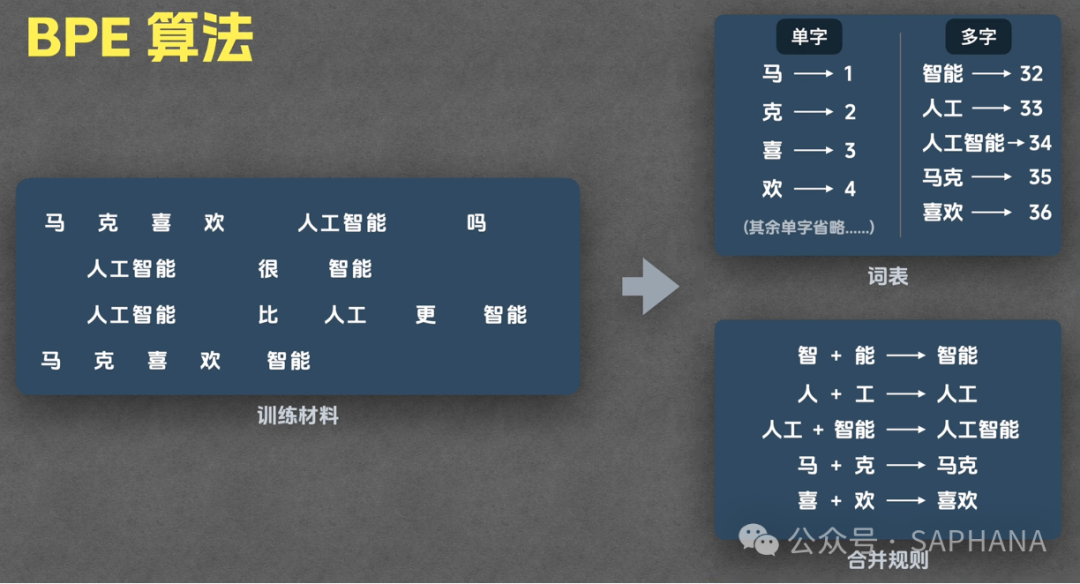
Step 1:准备训练语料
收集海量的文本数据作为训练材料。
Step 2:初始化词表
将所有出现的单字(对于中文)或字符(对于英文)作为初始 Token 加入词表。
例如,语料中出现的字:马、克、喜、欢、人、工、智、能、吗。
每个字都会被赋予一个唯一的 Token ID。
Step 3:统计共现频率
算法扫描整个训练语料,统计哪些字或子词组合(相邻对)出现的频率最高。
Step 4:执行合并
将出现频率最高的组合合并为一个新的 Token,并加入词表。这个过程迭代进行。
| 合并步骤 |
发现的高频组合 |
操作 |
| 第一轮 |
智 + 能 出现次数最多 |
合并为 智能,加入词表,记录规则:智 + 能 = 智能 |
| 第二轮 |
人 + 工 出现次数多 |
合并为 人工,加入词表,记录规则:人 + 工 = 人工 |
| 第三轮 |
人工 + 智能 出现次数多 |
合并为 人工智能,加入词表,规则:人工 + 智能 = 人工智能 |
| 后续轮次 |
马 + 克 → 马克
喜 + 欢 → 喜欢 |
分别合并,加入词表,记录对应规则 |
关键特点:合并后产生的新 Token(如 智能)还可以继续参与后续的合并(如与 人工 合并成 人工智能)。
最终训练得到的 Tokenizer 包含两部分:
- 词表(Vocabulary):一个从 Token 到 Token ID 的映射字典。
- 合并规则(Merge Rules):记录所有从子词合并成词的多步操作规则。
四、训练好的 Tokenizer 是如何使用的?
在推理(即使用)阶段,Tokenizer 会应用训练好的词表和规则来处理新文本。
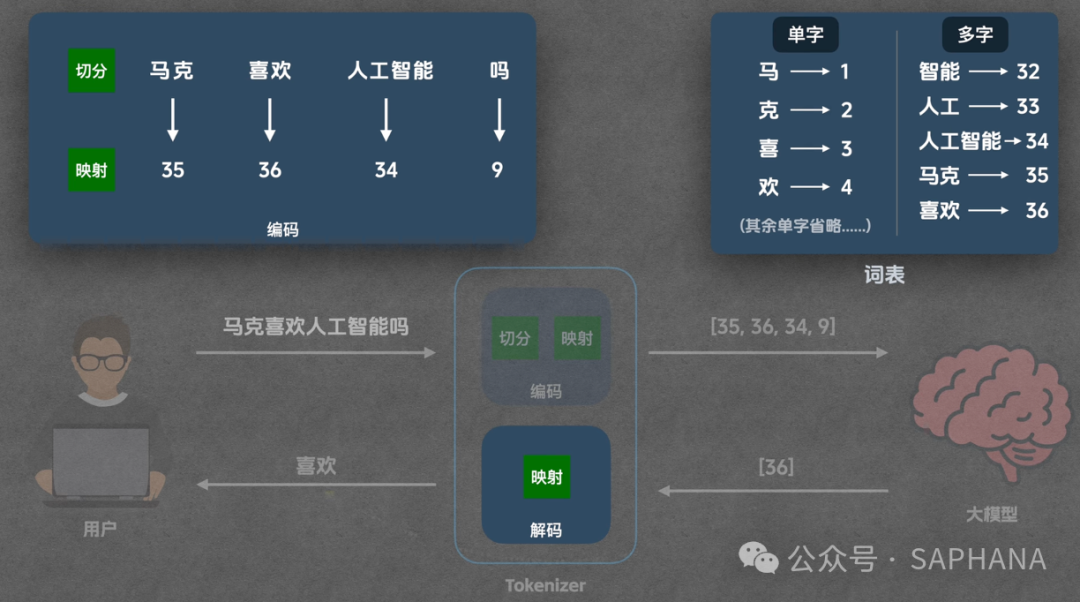
编码阶段
Step 1:初始切分
将输入句子按最小单元(如单字)切分。
句子:“马克喜欢人工智能吗?”
初始切分:马 / 克 / 喜 / 欢 / 人 / 工 / 智 / 能 / 吗
Step 2:应用合并规则
按照训练时学到的规则,从初始切分开始,尽可能多地合并。
智 + 能 → 智能人 + 工 → 人工人工 + 智能 → 人工智能喜 + 欢 → 喜欢马 + 克 → 马克
👉 最终得到 Token 序列:马克、喜欢、人工智能、吗
Step 3:映射为 Token ID
查询词表,将每个 Token 转换为对应的 Token ID,例如 马克→35,喜欢→36,以此类推。
解码阶段
这个过程简单得多。模型输出一个 Token ID(例如 36),Tokenizer 查询词表,直接映射回对应的 Token 文字 喜欢。
关键补充:
- 编码:需要
切分 + 映射 两步。
- 解码:只需要
映射 一步,因为模型每次只输出一个确定的 Token ID。
五、Token 与字数/单词数的换算关系
现在我们可以回答最初的那个问题了:为什么 Token ≠ 字数?
核心原因在于:Tokenizer 不仅是一个翻译器,它还是一个压缩器。 它通过合并常见组合,用更少的Token来表示更多的原始字符,从而提高了模型处理信息的效率。
以我们的例子为例:“马克喜欢人工智能吗” 包含 9 个汉字,但经过 Tokenizer 处理后,只用了 4 个 Token 来表示。
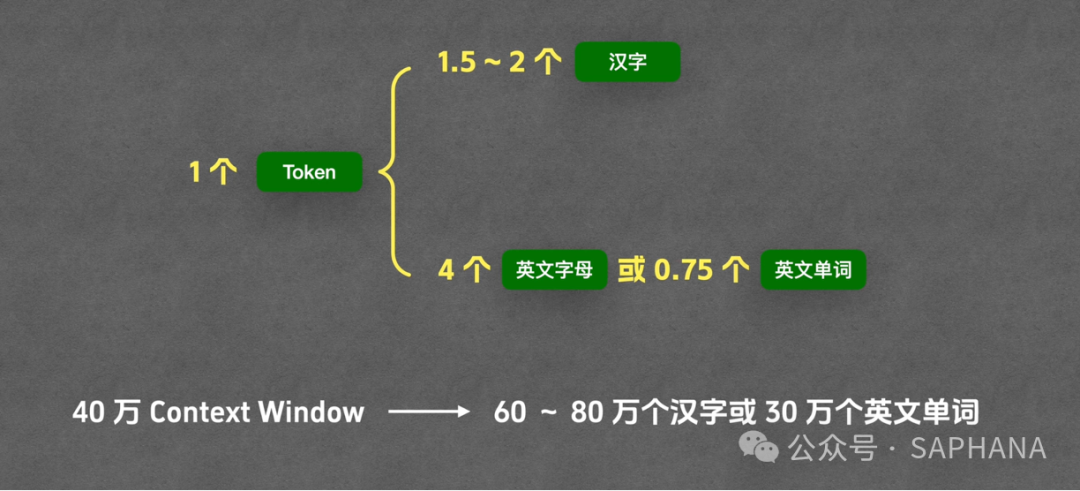
根据经验,大致的换算关系如下:
| 语言类型 |
大致换算关系 |
| 中文 |
1个 Token ≈ 1.5 ~ 2 个汉字 |
| 英文 |
1个 Token ≈ 4 个英文字母 或 0.75 个英文单词 |
这解释了 Context Window(上下文窗口) 的真实含义。例如,一个模型声称拥有 40 万 Token 的上下文窗口,这意味着:
- 处理中文时,大约能容纳 60 万 ~ 80 万汉字的内容。
- 处理英文时,大约能容纳 30 万个英文单词。
六、总结
让我们用一句话来总结全文的核心:
Token(词元)是大模型处理信息的最小单位,由 Tokenizer 通过统计学习得到的“切分与映射”规则生成,其本质是对自然语言的一种高效、结构化的压缩表示。
最后,记住下面这张图中的5个关键点,你就彻底掌握了 Token 的精髓:

- Token ≠ 字数:它是“词元”,不是字符。
- 大模型不理解语言:它只处理和生成数字序列。
- Tokenizer 是桥梁:负责在文字与数字之间进行编码和解码,是任何大模型不可或缺的前置组件。深入了解这些组件的细节,可以参考专业的 技术文档 和源码解析。
- Tokenizer 的本质是“统计+合并”:它通过分析海量文本的频率,学习语言的常见组合结构。
- Context Window = Token 容量:它直接决定了模型单次处理信息量的上限,是评估模型能力的关键指标之一。
希望这篇详解能帮助你拨开迷雾,真正理解这个驱动当今人工智能浪潮的底层基础概念。如果你对这类深度学习和AIGC的底层原理感兴趣,欢迎在 云栈社区 与其他开发者继续深入探讨。
 发表于 2026-3-26 03:25:00
|
查看: 163|
回复: 0
发表于 2026-3-26 03:25:00
|
查看: 163|
回复: 0
