
上周末有条挺有意思的 AI 新闻。AI 编程工具 Cursor 在 3 月 19 日发布了新模型 Composer 2,官网上强调这是他们的“自有模型”。
Cursor 是目前全球最火的 AI 编程工具,本质上是一个深度集成了 AI 能力的 VS Code 修改版。从 2024 年 10 月 Composer 1 发布以来,外界就一直怀疑它的模型是套壳的,但始终没有实锤。
这次证据来了。发布不到 24 小时,一位叫 @fynnso 的开发者想了个巧妙的测试办法:自己架设一台服务器充当模型接口,然后在本地 Cursor 设置里把模型地址指向自己的服务器。这样一来,Cursor 发出的所有请求就被成功拦截,暴露了其真实模型 ID:kimi-k2p5-rl-0317-s515-fast。
结论很明确:Composer 2 的底座,就是月之暗面的 Kimi K2.5。
消息和截图传开后,Cursor 第一时间堵了这个漏洞,但为时已晚。连马斯克也转发了相关消息并予以确认。
随后,Cursor 的一位负责人出面回应,承认确实使用了 K2.5,但强调是通过合作伙伴 Fireworks AI 获得的合法授权。Kimi 官方也确认了这条授权链。从法律层面看,Cursor 的行为确实不算侵权。
关于这件事的讨论已经很多了,但今天我想聊的是另一个更值得深思的视角。
从“拿来主义”到“反向输出”
过去两年,AI 领域其实有一条不太被主流关注的暗线。
时间倒回 2023 年,当时国内 AI 创业的主流姿态是拿 Meta 的 Llama 模型做微调。行业的普遍共识是“我们落后硅谷至少两个世代”。
转折点出现在 2024 年 5 月,DeepSeek 发布了 V2 模型。这家从量化基金幻方孵化出来的公司,凭借 MoE(混合专家模型)和 MLA(多模态学习架构)两项关键技术,把大模型的调用成本大幅压低。MoE 的逻辑简单来说,就是不让一个庞大的模型当“全才”,而是训练一个“专家团”,根据任务需求动态调用最合适的专家。MLA 则显著降低了模型运行时的内存占用。
当时大家对 DeepSeek 的印象主要还是“便宜”。等到 2024 年 12 月 V3 发布,叠加了 FP8 低精度训练等新技术后,官方披露的完整训练成本仅为 557.6 万美元,大约是 Meta Llama 3.1 训练成本的十分之一,但性能却能与 GPT-4 基本持平。
真正的“范式”级突破发生在 2025 年 1 月,即 R1 模型的发布。R1 的核心在于,它使用纯强化学习达到了与 OpenAI o1 相当的推理水平。这意味着它不需要庞大的人工标注题库,也不依赖有监督微调,而是让模型通过自我博弈来学习和评估。这不再是“用更少的钱复现你的成果”,而是“我开辟了一条你没走过的路”。
R1 之后,OpenAI 的奥特曼从最初暗讽 DeepSeek “只是复制已知工作”,转变为承认“DeepSeek 的出现改变了 OpenAI 过去几年遥遥领先的局面”。据报道,Meta 也成立了多个专项小组来拆解 DeepSeek 的方法论。
这可以看作是第一波冲击。
第二波冲击则来自 Kimi。2026 年 1 月底,Kimi 发布了万亿参数的 MoE 模型 K2.5,原生支持多模态,在代码生成、视觉理解和 Agent 工具调用上表现都相当出色。关键是,它选择了开源,采用 Modified MIT 协议。
发布后不久,K2.5 在全球开发者模型聚合平台 OpenRouter 上的调用量冲到了第一名,甚至排在了 Gemini 3 Flash 和 Claude Sonnet 4.5 的前面。当然,当时 K2.5 在 OpenClaw 生态中可以免费调用,这对拉动初期调用量功不可没。
仅仅三年前,国内公司还在拿着 Llama 做微调。而现在,硅谷的头部工具已经开始拿着中国的 K2.5 做微调和深度开发了。这个角色转换的速度,超出了大多数人的预期。
开源模型的“供应链”到底是什么?
谈到这,就引出一个更基础的问题:开源模型的“供应链”究竟是如何运作的?
大多数人对“开源”的理解可能还停留在“免费下载,自己用”的层面,认为 DeepSeek 和 Kimi 的价值就是“帮大家把价格打下来了”。
这当然没错,价格是核心驱动力之一。但在真实的商业世界里,开源模型的流转路径要复杂得多。
以 Cursor 这个案例为例,完整的商业链条是这样的:
Kimi 开源 K2.5 → 硅谷的推理服务商 Fireworks AI 获得授权,提供托管、微调和强化学习训练服务 → Fireworks AI 将优化后的模型转授权给 Cursor → Cursor 将其包装成自有品牌模型 Composer 2,提供给全球开发者。
中间每一层都涉及技术服务、授权协议和商业利益分配。这依然是标准的商业行为,而非公益行为。
作为一种商业行为,开源模型的供应链正在像过去实体制造领域的“中国供应链”一样,在全球范围内产生深远影响。一件优衣库的衣服,从纱线、面料到成衣,供应链可能都在中国。新能源汽车的电池、光伏组件也是如此。
这种依赖关系的形成,依靠的是几十年积累下来的成本优势、工程化能力和规模效应。全球品牌选择中国供应链,核心还是一笔经济账:同样的品质,成本更低;同样的成本,交付更快。
AI 领域正在出现一个结构上类似的现象,只是“原材料”从钢铁、棉花变成了模型权重和推理算力。全球的 AI 应用层公司开始选择中国的开源模型做底座,最朴素的驱动力就是:好用,且便宜。
科技史上有个著名的先例:Android。Google 开源 AOSP(Android 开放源代码项目),高通做芯片适配,三星、华为做设备定制,运营商铺开渠道。用户最终拿到手的是一台三星手机,但操作系统的底层逻辑、API 规范和整个应用生态的标准,是由 Google 定义的。供应链上每一层都在赚钱,而定义底座的那一层,拥有相当大的话语权。
当然,这目前还只是一个可能的方向,远非既成事实。
从 B 端到 C 端:Token 成为新时代的“水电煤”
说到 AI 供应链,就不得不提 2026 年开年第一个大火的概念:AI Agent,或者说更具体的“养龙虾”。
OpenClaw 是一个开源的 Agent 框架。框架本身就像龙虾的身体,它需要一个“大脑”,也就是模型来驱动。K2.5 成了 OpenClaw 官方推荐的主力“饲料”之一。随后,大厂纷纷跟进,字节的 ArkClaw、腾讯的 QClaw、智谱的 AutoClaw 等密集上线。这些框架底层调用量最大的模型,就包括了 K2.5、DeepSeek、Qwen 系列等。中国的开源模型持续占据了 token 消耗的主流。
这条链路与实体供应链有相似之处。富士康给苹果、华为、小米代工,谁的手机卖得好,富士康都赚钱,因为它在供应链上的位置足够底层、足够通用。
如果说 Cursor 事件暴露的是 to B(企业端)供应链的故事,那么“龙虾”生态展示的则是 to C(用户/开发者端)供应链的故事。两条链路共同指向同一个事实:底座模型的位置,正越来越像数字经济时代的基础设施。 Token,就是未来 AI 时代的“水电煤”。
这个“水电煤”的市场有多大?有一组数据可供参考。据华泰柏瑞基金的统计,中国市场的日均 Token 消耗量从 2024 年初的约 1000 亿,增长到 2025 年年中突破 30 万亿,至 2026 年 2 月已达 180 万亿的量级。像龙虾这类 7x24 小时自动运行的 Agent 应用,其 Token 消耗量比传统的 Chatbot 对话高出几个数量级。
市场的嗅觉是最敏锐的。2026年3月16日,阿里巴巴宣布成立 Alibaba Token Hub (ATH) 事业群,与电商、云智能并列,由 CEO 吴泳铭直接带队。整个事业群就围绕一件事:创造 Token、输送 Token、应用 Token。
“Token”这个以前只在技术社区里流通的黑话,如今被一家万亿市值的公司拿来命名其核心事业群。如果 Token 真的在变成 AI 时代的水电煤,那么谁能稳定、低成本地提供海量 Token,谁就能在这个生态中占据不可或缺的位置。开源模型在这件事上具有天然优势:部署灵活、成本可控、不依赖单一供应商。像 DeepSeek 和 Kimi 这样能把成本打下来同时保持性能的开源模型,就相当于这个市场里的“低成本发电厂”。
“便宜”只是表象,技术纵深才是底气
为什么中国的开源模型会受到全球市场的欢迎?成本当然是第一块敲门砖。
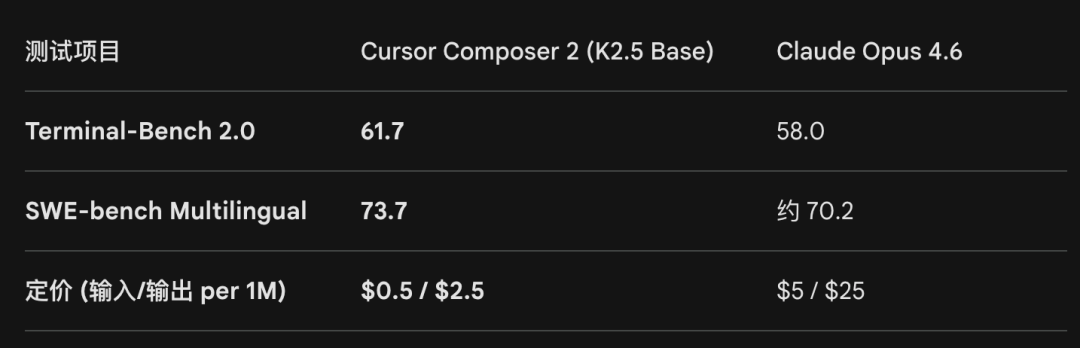
Cloudflare 做过实测,在其 Workers AI 平台上用 K2.5 替代其他模型,推理成本降低了 77%。Cursor 自己披露的数据也说明了其选择逻辑:Composer 2 在关键性能上略低于 GPT-5.4,但生成速度更快,最关键的是成本最低。对于一家年化收入达 20 亿美元的公司来说,这笔账很好算。
再看龙虾生态。K2.5 在 OpenRouter 上的定价大约是每百万输入 token 0.5 美元、输出 2.8 美元。而 Claude Sonnet 4.5 的价格是 3 美元和 15 美元,相差六到七倍。在龙虾这种需要高频、多步调用的场景下,六倍的成本差异不是“省一点钱”的问题,而是“这个应用能否经济可持续地跑起来”的问题。
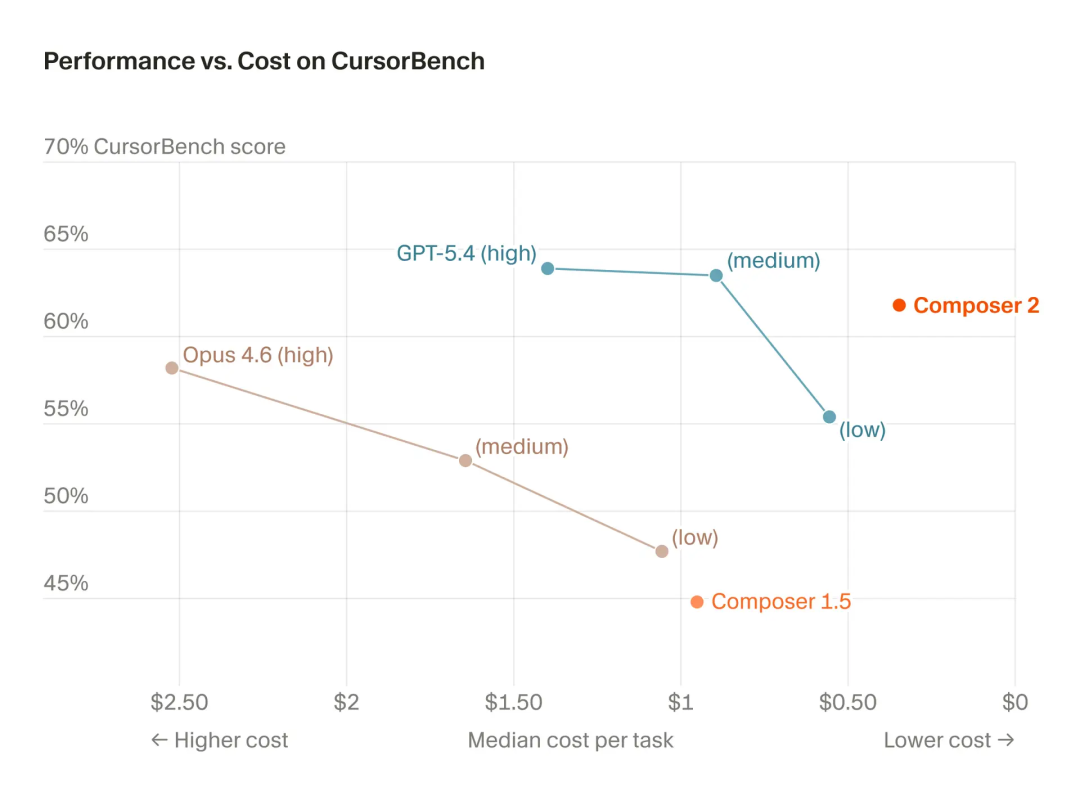
但光有便宜恐怕还不够。DeepSeek 用极低价格提供的,是与行业顶尖产品同等水平的服务。K2.5 也是如此。根据 Cursor 官方的测试数据,基于 K2.5 深度优化后的 Composer 2,在其内部的编程基准测试 CursorBench 上的得分超过了 Claude Opus 4.6。
这听起来像是在说 K2.5 比 Claude 更强?当然不能这么简单地下结论。Cursor 的副总裁 Lee Robinson 在回应中提到,最终模型只有大约 1/4 的“算力”来自 K2.5 这个底座,剩下 3/4 是 Cursor 团队自己进行的继续预训练和大规模强化学习的成果。
联合创始人 Aman Sanger 进一步解释,团队评估了多个候选底座,发现 K2.5 在编程相关的各项指标上潜力最好。他们在此基础上,进行了针对编程场景的继续预训练(调整任务分布和能力侧重),并投入了 4 倍于底座的算力进行强化学习训练。经过这些深度加工后,Composer 2 在各项 benchmark 上的表现已经与原始的 K2.5 “非常不同了”。
换句话说,Cursor 选择 K2.5,不是因为它“比 Claude 更聪明”,而是因为它作为一个底座,在编程这个垂直方向上的潜力最大。经过大量定向投资和训练后,能在特定任务上达到接近顶尖闭源模型的性能,同时成本却低得多。
这恰恰体现了整个开源生态的核心价值:应用层公司不需要从零开始训练一个千亿参数的模型,而是可以选取一个强大的开源底座,进行垂直场景的深度优化,从而在特定任务上与闭源巨头竞争。Cursor 不是唯一这么做的,另一家知名的 AI 编程工具 Cognition 的 Windsurf 也采用了类似的路径。
DeepSeek 在训练成本端打开的空间,被 Kimi 的 K2.5 在 Agent 和代码生成这两个关键场景中进一步延伸和夯实,共同构成了当下中国 AI 开源模型在全球供应链中的基本叙事。据报道,K2.5 发布后获得了极高的市场关注,其 20 天内的收入超过了 2025 年全年,海外收入首次反超国内,公司在三个月内估值从 43 亿美元飙升至 180 亿美元。
供应链的估值谜题与未来竞争
说到估值,有一个对比值得玩味。有传言称 Cursor 的新一轮融资估值将达到 500 亿美元。而为其提供核心底座模型的 Kimi,估值是 180 亿美元,大约是 Cursor 目标估值的三分之一。
放在供应链的语境里看,这好比一个品牌商的市值是其核心供应商的三倍,但品牌商产品的核心竞争力却很大程度上来源于这个供应商。这并不是说这个比例一定不合理,Cursor 卓越的产品力、用户粘性和商业模式确实具有独立价值。但这至少表明,当前资本市场对于“定义底层的技术基础设施”和“构建上层应用生态”的定价逻辑,可能存在一些认知上的时间差或差异。
类似的情况不止一例。前段时间大火的 AI Agent 公司 Manus,本身也没有自己的底层模型,完全依赖第三方,就因其创新的产品和场景被 Meta 开出 20 亿美元的收购价码。
更值得关注的是横向对比。Kimi 180 亿美元的估值,大约只是 OpenAI 估值的 2%,不到 Anthropic 估值的 10%。DeepSeek 目前没有进行公开融资,创始人梁文锋依靠幻方量化的资金自给自足,保持了极大的独立性。这种独立性让他们可以免受短期投资人回报压力的干扰,专注于长期的基础研究。
这两家公司的底层技术正在被全球开发者使用,但它们的市场价值,还在被“全球 AI 基础设施提供商”这个新身份重新评估。
当然,市场也存在另一种完全不同的看法:模型层最终会像当年的带宽或存储一样,变成高度标准化的大宗商品,真正的价值和利润会集中在离用户更近的应用层、数据层和解决方案层。按照这个逻辑,Cursor 的高估值恰恰反映了它离最终用户和商业闭环更近。两种判断都有其道理,现在下结论为时过早。在开发者广场里,关于技术栈价值分布的讨论也总是充满碰撞。
小公司的机会:挑战“第一性原理”
为什么 DeepSeek、Kimi 这类相对“小”的公司,能在基础模型层面找到技术突破口?
2026年3月中旬,Kimi 创始人杨植麟受黄仁勋邀请在英伟达 GTC 大会上发表演讲,他是唯一受邀的中国大模型公司代表。他演讲的主题是 Kimi 团队刚发表的论文《Attention Residuals》。

这篇论文的切入点非常有意思。“残差连接”是深度学习领域自2015年 ResNet 提出后就一直使用的基础架构组件,十年来几乎被视为默认配置,无人质疑。大多数研究团队选择在注意力机制、MoE 等上层模块进行优化,而 Kimi 团队则尝试回到最底层,从这些“默认配置”中寻找新的改进空间。这篇论文甚至得到了马斯克和 Karpathy 的点赞,而论文的第一作者,是一位17岁的高中生。
除了 Attention Residuals,Kimi 还开源了 MuonClip(一个旨在替代已沿用11年的 Adam 优化器的新方案)和 Kimi Linear(一种高效的线性注意力方案)。杨植麟在 GTC 上将这些工作统称为“Scaling Ladder”,即通过严谨的、大规模的实验,从那些看似已经定型的基础技术中,找到新的改进空间。
把 DeepSeek 和 Kimi 放在一起看,能看到一种互补的格局。DeepSeek 的贡献主要集中在训练方法论层面,例如用纯强化学习重新定义推理模型的训练路径,以及通过 MoE 和 MLA 的极致工程将训练成本压缩到行业标杆的十分之一。而 Kimi 的贡献则更多集中在网络架构的基础组件层面,从残差连接到优化器再到注意力机制,在最底层进行创新。
这两类工作有一个共同特点:它们主要不是在现有的跑分榜上争夺微弱的排名优势,而是在尝试做“范式”层面的事情。梁文锋曾说过,很多人以为 AI 突破就是“大力出奇迹”,但真正的突破往往来自更巧妙的方法,而非单纯的资源堆砌。杨植麟在 GTC 上也表达了类似观点:10年前的研究主要靠提出新想法,但缺乏严谨的大规模实验验证;现在有了充足的计算资源和“Scaling Ladder”方法论,能够更严格地从那些看似“已经定型”的技术里找到改进空间。
这与国内很多大型科技公司做模型的路径有所不同。大厂资源更充裕,产品线也更丰富,但其核心动作往往围绕自身现有业务进行集成和优化。在“回到第一性原理去挑战最底层假设”这件事上,受限于庞大的业务压力、复杂的组织架构和固有的路径依赖,大厂有时很难给这类长期、高风险的基础研究留出足够的空间和耐心。
这再次回到供应链的类比。在实体制造业的供应链中,拥有持久话语权的往往不是最终的组装厂,而是那些定义核心零部件和技术标准的一层,例如台积电的先进制程、高通的基带芯片、ARM 的指令集架构。AI 的供应链逻辑也正在显现出类似的趋势。如果中国的开源模型不仅仅提供“好用又便宜”的产品,还能持续输出底层的技术组件和创新方法论,那么它在全球 AI 供应链中的位置,就将从一个可替换的“供应商”,向不可替代的“基础设施和标准贡献者”演进。这个过程充满了挑战,但也正是开源实战的魅力所在,它让全球开发者都能站在巨人的肩膀上,同时也有机会成为新的巨人。
当然,这一切都还是一个正在展开的趋势,远未到可以下定论的时候。
开源的挑战与不确定的未来
开源从来不是一件轻松的事,尤其在商业竞争激烈的 AI 领域。它需要同时满足几个苛刻的条件:技术上必须有足够强的模型,开源后才有人愿意用;商业上要能忍受短期“让利”甚至“亏损”的阵痛期;战略上则不能被短期的价格战和市场竞争带偏方向。
现实是骨感的。例如,MiniMax 的最新模型 M2.7 已经转为闭源,不再公开权重。前不久,阿里千问的技术负责人林俊旸宣布离职,主流说法是技术理想与公司的商业化 KPI 之间存在难以调和的冲突。即便是开源先驱之一的 Meta,围绕 Llama 4 的测试和未来路线图也出现了内部争议,有报道称其下一代模型可能转向闭源路线。
大厂做开源,似乎总会遇到相似的困境:在短期,管理层很难直接看到开源带来的财务收益;在长期,开源团队的研究节奏又很难与大厂严格的绩效考核周期对齐。
即便已经初步形成了商业闭环,开源模型的未来窗口期依然充满不确定性。地缘政治因素正在收紧,DeepSeek 已经在一些国家受到使用限制,美国也有参议员公开呼吁加强对中国 AI 技术的管制。竞争对手从未停步,OpenAI 等巨头正在加速推出新模型。资本市场的耐心也并非无限,不是所有投资人都能接受“先让全世界免费用,长期再赚钱”这种延迟满足的逻辑。
如果未来有更多模型公司出于各种压力转向闭源,那么那些已经深度依赖中国开源模型的全球应用层公司和开发者,将不得不重新寻找替代方案。
结语:变量之一,而非终局
那么,从 Cursor “套壳” Kimi,到全球龙虾生态依赖中国模型,再到 DeepSeek 震惊业界,这一系列事件到底意味着什么?
在讨论时,我们很容易走向两个极端。一边是带着强烈民族情绪的“赢麻了”,另一边则是纯粹从技术细节出发的“不过如此”。这两种视角可能都失之偏颇。
开源模型及其催生的全球供应链,自然有其巨大的场景价值和商业潜力,但也必然有其局限性和待解决的问题。真正的未来,是在技术、商业、产品、政策的持续互动与迭代中逐步浮现的。
目前能够清晰看到的是,全球 AI 的基础设施格局正在从“美国提供核心模型,全世界开发应用”的单一结构,慢慢转变为一个参与方更多、层次更复杂、相互依存度更高的全球供应链体系。以 DeepSeek 和 Kimi 为代表的中国开源模型,无疑是这个宏大变化中的一个重要变量。但它们也只是变量之一。
这个过程才刚刚开始。正如过去全球消费电子品牌的繁荣,离不开珠三角强大供应链的支撑一样,我们或许也正在见证 AI 时代新型技术竞争力的形成与溢出。在智能 & 数据 & 云这个广阔的领域,每一次成本突破和架构创新,都在重塑生态。
对于我们这些普通的开发者、从业者或内容创作者而言,最实际、最直接的收获可能就是:我们能以更低的成本,用上更多、更好的 AI 产品和服务。而围绕技术演进与商业模式的思考,欢迎在云栈社区继续交流。
本文基于公开信息与行业分析,Claude、Gemini 在事实核对中亦有帮助。题图由 Midjourney 生成。
 发表于 2026-3-26 20:09:23
|
查看: 143|
回复: 0
发表于 2026-3-26 20:09:23
|
查看: 143|
回复: 0
