LLM Agent 看起来越来越智能了。但实际上,它们的性能提升很可能只是因为拿到了更多信息。
随着Agentic工作流的普及,大语言模型正被频繁用于迭代优化机器学习模型:提出配置方案、观察实验结果、逐步改进决策。从表面上看,这似乎体现了模型的推理能力,但一个根本问题却悬而未决:系统性能的提升,究竟是源于内在的推理能力,还是源于输入端信息可见性的改善?
在当前主流的人工智能优化框架中,信息暴露——即Agent能“看到”什么——往往未被当作一个受控的实验变量。上下文的引入方式通常是启发式的,通过提示工程、工具集成或系统层面的设计选择来完成。
这就导致了归因困境:不同Agent系统间观察到的性能差异,反映的可能是信息访问权限的不同,而非模型推理能力的高低。其结果既难以归因,也几乎无法在不同实现间复现。
实际上,任何Agentic优化框架中都有一个核心却常被忽视的设计要素:LLM可用的上下文。任务描述、评估指标、参数约束、历史优化记录——这些都直接左右着Agent对环境的理解和后续配置的生成。
如果不控制上下文,我们就无法判断一个Agent是在进行真正的推理,还是在根据输入信息做条件反射。
ContextEval评估框架
ContextEval正是基于这一思路构建的受控评估框架。它的核心思想并非优化提示本身,而是系统地变更Agent被允许“看到”的内容,并测量这一单一因素对优化行为的影响。
框架选择的核心任务是超参数优化(HPO)。寻找最优超参数通常是一个缓慢的手动过程,网格搜索就是最典型的例子。但如果让一个LLM扮演自主工程师的角色,提出配置、观察结果,并根据选择性揭示的信息来修正下一步的猜测,它的表现会怎样?
为了验证这一设想,实验系统让LLM Agent在四个机器学习基准的超参数空间中进行了测试,目的在于识别优化过程中真正起作用的信息到底是什么。
给 LLM 更多信息,是否真的改善了优化效果——还是仅仅改变了它的行为模式?
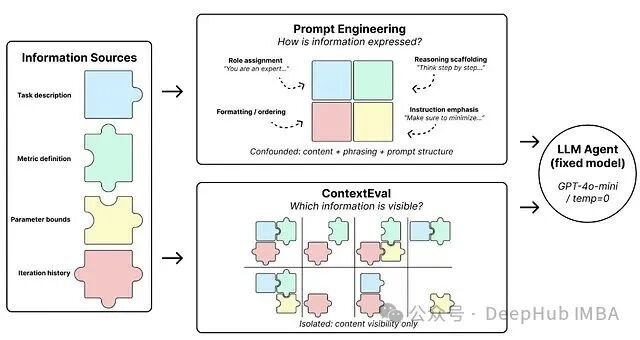
测试方法
上下文可见性与“上下文策略”
实验固定了模型(GPT-4o-mini)和任务,并沿着四个正交的维度来变化上下文:
- 任务描述:逐字引用的Kaggle竞赛规格说明。
- 指标暴露:数学评估规则的明确定义。
- 参数边界:显式的搜索空间约束。
- 反馈深度:历史长度,即1步或5步的历史记录。
由此构建出一个包含16种“上下文策略”的全因子网格,每种策略定义了Agent在每一步中的信息可见范围。随后,在四个基准上对每种策略逐一进行评估。
实验前的模型配置初始化
要评估Agent是否“智能”,其起始条件必须受到严格控制。一个足够好的初始配置很可能会掩盖推理能力的不足。实验采用了Sobel采样(256种配置)来对每个任务的性能曲面进行特征化,并从中选取了三个分层的起始点:
- 低质量(“Broken”):性能在底部20%。
- 中等质量(“Average”):性能在中间区域。
- 高质量(“Pro”):性能在顶部20%。
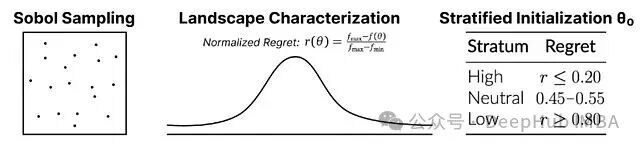
实验采用归一化遗憾值作为性能衡量指标,即与最优配置间的标准化距离。这个指标有助于区分真正的优化进步和对糟糕起点的简单修正。
结果与发现
实验结论是一致的:Agent能看到什么,比它如何“推理”更重要。
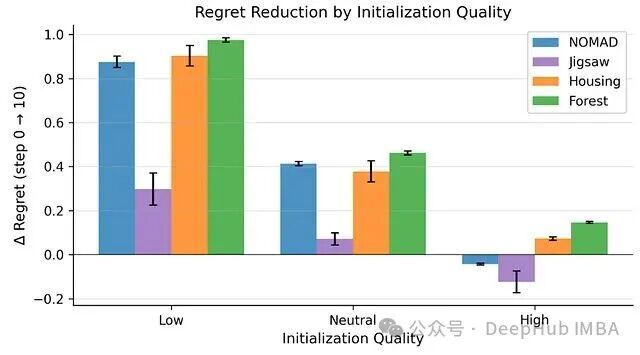
1. 初始配置占主导地位
成功的最强预测因子不是Agent做了什么,而是它从哪个配置出发。
- 起点较差的Agent能快速改善,但很快会触及性能天花板。
- 起点接近最优的Agent,其改善幅度则极小,在NOMAD基准上甚至出现了性能退化。
解读:Agent的行为更接近于一个纠错系统,而非一个主动的优化器。
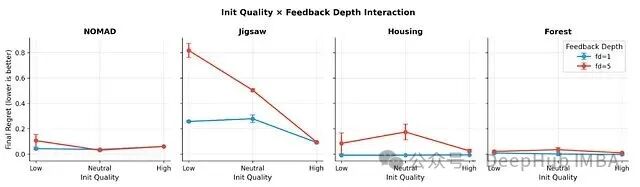
2. 反馈深度悖论及其与初始化的交互效应
提供更长的历史信息(fd=5 vs fd=1)在所有基准上持续恶化性能,归一化遗憾值上升,在Jigsaw基准上尤为突出。一长串低分记录会“锚定”Agent的认知,压缩其探索空间,阻碍其从糟糕状态中恢复。
这说明,更多信息并不总意味着更好的推理,反而常常构成一种约束。这种效应在起点差的情况下最明显——负面反馈层层累积;而在强起点下,性能差异则可以忽略不计。
3. 可行性 vs. 优化质量
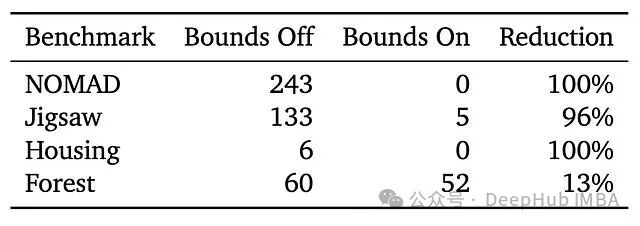
当为Agent提供明确的参数边界后,无效提议的数量大幅减少了96%–100%。然而,最终的优化性能并未因此得到改善。
这表明:遵循规则是一回事,在规则内进行有效优化则是另一回事。
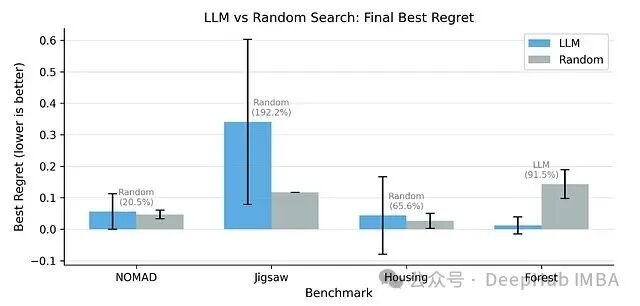
4. 与随机搜索的对比
LLM引导的优化并不稳定地胜过随机搜索。在Jigsaw——最复杂的基准之一——上,一个盲目选取配置的随机搜索算法,其性能超过了拥有完整上下文和优化历史的LLM Agent。
也就是说,在某些复杂场景中,无信息的随机探索可以优于LLM引导的“智能”优化。
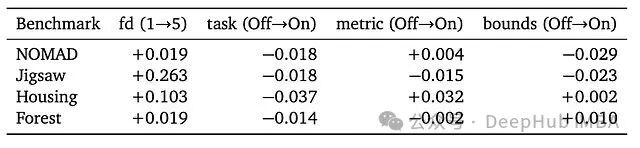
5. 任务上下文的影响
提供详细的任务描述带来的收益有限,甚至可能增加结果的不稳定性。性能表现看起来更多是由模型预训练时形成的先验知识驱动,而非迭代推理的贡献。
一个核心发现是:Agent能快速纠正明显较差的配置,但对已经不错的配置却束手无策。
核心启示:Agent更智能了,还是只是“信息更充分”?
LLM Agent的性能提升,可能很大程度上源于上下文线索对预训练先验知识的激活。当接收到任务描述或指标信号时,它们是从庞大的训练数据中回忆并推断出“合理的”超参数范围,而并非基于当前观察到的反馈进行真正的因果推理。
在实践中,Agent的行为模式更接近一种带反馈的先验驱动启发式方法,而非严谨的搜索算法。
Agent能修复糟糕的配置,但难以在好的配置上做出有意义的改进。
约束被遵循了,但约束内的优化却没有发生。明显的、与任务强相关的参数会被调整,而那些更敏感、更微妙的参数(如学习率)则处理得过于保守。
最关键的一点或许是:Agent的表现往往无法稳定超越随机搜索,尤其是在复杂任务上。 这暗示了其底层机制更像是部分信息下的模式匹配,而非真正的推理。
ContextEval框架的意义与对AI评估的启示
ContextEval框架的价值在于,它首次将信息暴露作为一个受控变量纳入LLM Agent的评估体系。通过隔离上下文,我们得以判断性能究竟来源于推理能力,还是来源于有用元数据的获取。这一框架有助于改进热启动策略、提升Agent评估的可靠性,并厘清跨系统比较的基础。
更深层的启示在于:未来的基准测试应将上下文可见性作为核心实验因素加以报告。缺少这一维度,我们很容易高估LLM Agent的实际能力边界。
一个在完整上下文下表现良好的Agent不一定更“聪明”——它可能只是拿到了更多信息。
原文地址:https://medium.com/99p-labs/are-llm-agents-actually-smart-or-just-better-informed-429c17d217bd
by Hikaru Isayama
这项研究为理解LLM Agent的工作机制提供了宝贵的实验视角,也提醒开发者在设计云栈社区这类技术社区中的实践案例时,需要更审慎地评估性能提升的真正来源。
 发表于 2026-3-27 02:34:13
|
查看: 140|
回复: 0
发表于 2026-3-27 02:34:13
|
查看: 140|
回复: 0
