这原本是一条来自Google Research的、略显枯燥的技术新闻,却在社交网络上引发了病毒式传播。不到24小时,其推文就收获了超过1280万次浏览。
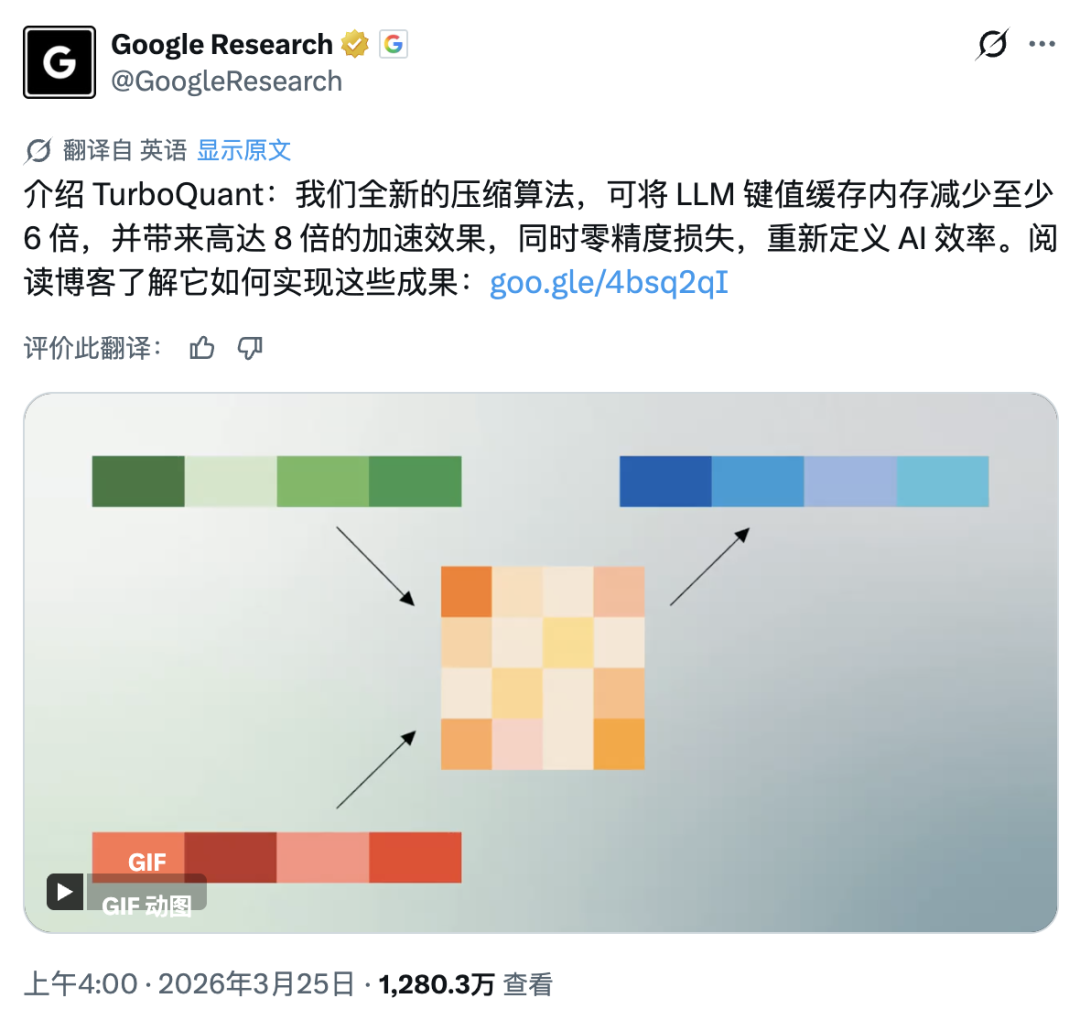
原因无他,这项名为TurboQuant的AI压缩技术,其设定与HBO神剧《硅谷》中虚构的“中间压缩算法”惊人地相似。看过这部剧的朋友,想必都对那个名为Pied Piper(魔笛手)的虚构公司念念不忘。在剧中,男主角发明了一种能以极高压缩率无损处理文件的算法,甚至因此改写了互联网规则。

当时我们都以为这只是编剧的脑洞。直到Google Research正式发布了TurboQuant。这项技术的核心承诺直击痛点:在不损失模型性能的前提下,将AI的“工作记忆”压缩至少6倍,并带来高达8倍的加速效果。
市场的反应也极为真实。TurboQuant发布当天,美股存储芯片板块盘中遭遇明显抛售。美光科技(MU)、闪迪等头部企业股价显著收跌。
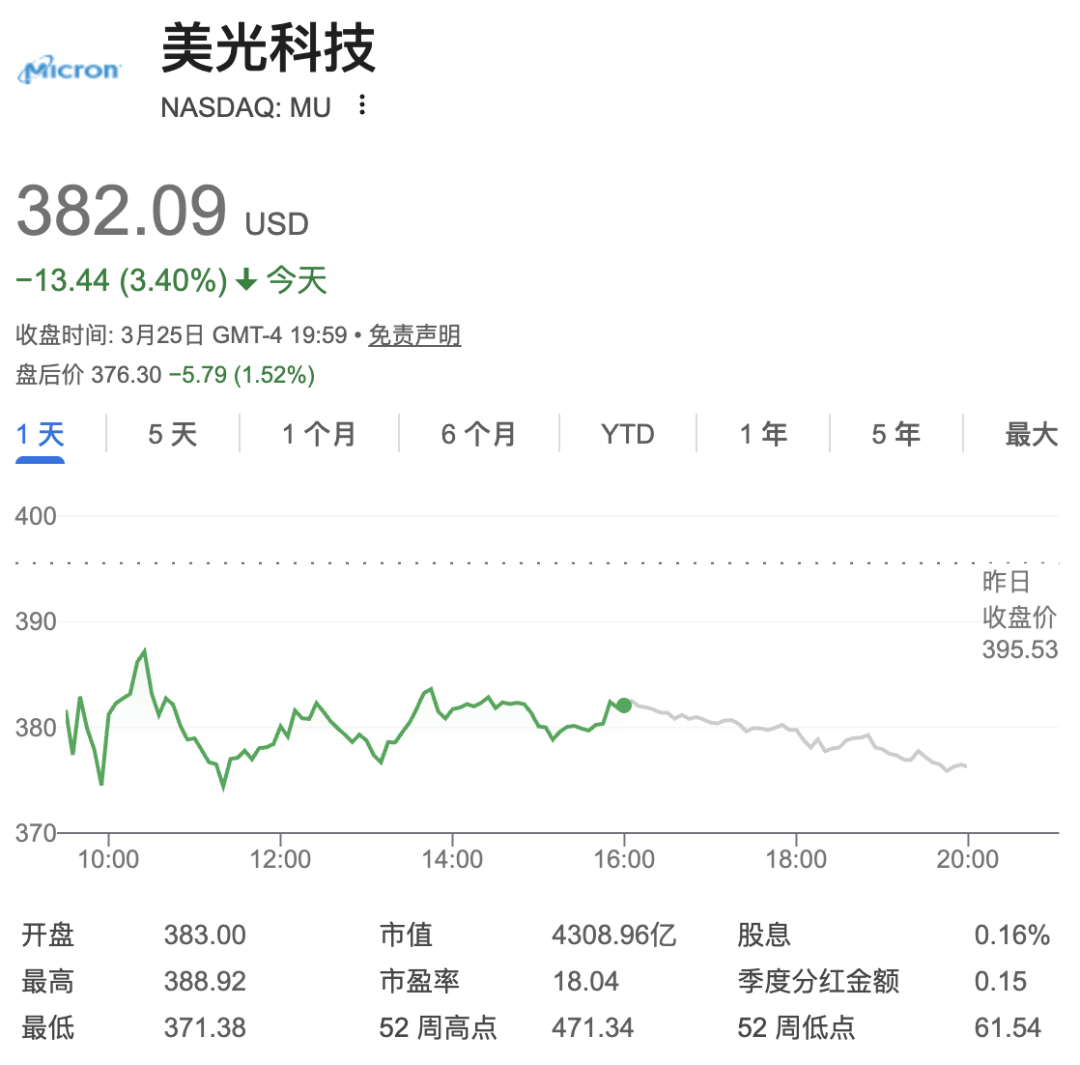
这不禁让人好奇,一项纯软件层面的算法创新,为何会让硬件供应链先慌了神?Google到底向当前的AI牌桌上扔了一张怎样的底牌?
困在“记忆黑洞”里的大模型
抛开网络热梗,TurboQuant的出现其实是为了解决一个让整个AI行业头疼已久的真实瓶颈:KV Cache(键值缓存)膨胀问题。
众所周知,现在的基于Transformer架构的AI模型越来越大,对显存(GPU内存)的胃口也像无底洞。尤其是在推理阶段(也就是你和AI聊天的时候),模型需要记住整个对话的上下文信息,这部分临时存储的数据就是KV Cache。
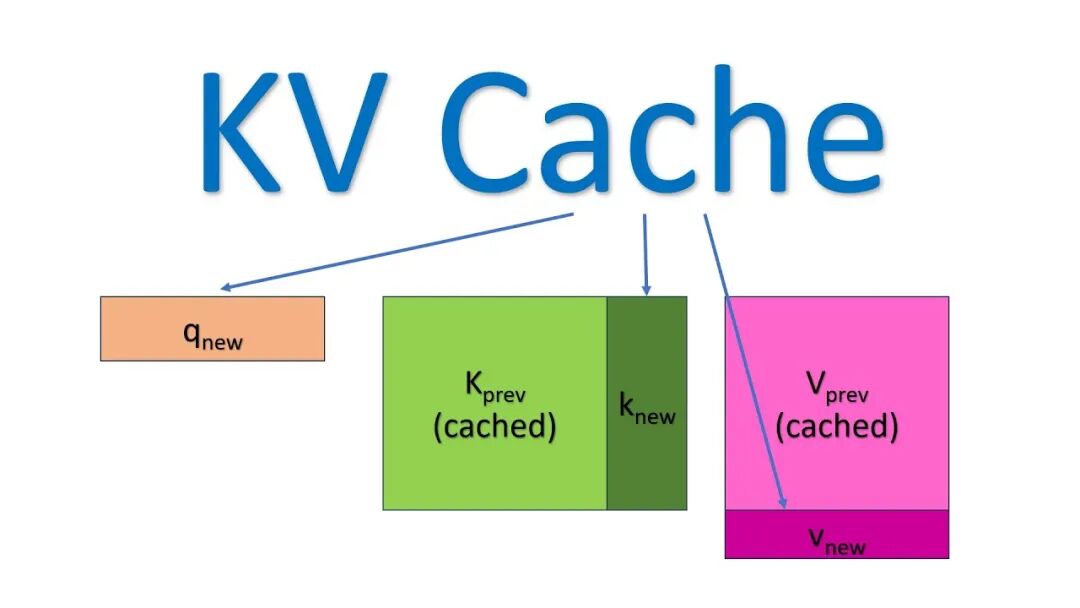
你可以把它想象成AI的“短期记忆便签”。每处理一个词(token),模型都要把它转换成一个高维向量存进显存。对话越长,这份“数字备忘录”就膨胀得越快,很快就会把宝贵的GPU显存塞满。这就是为什么你的AI助手聊久了可能会“变笨”或者直接报错——它的“脑容量”不够了。
更棘手的是,传统的压缩方法一直面临一个两难困境:为了在压缩数据后能准确还原,需要额外存储“量化常数”之类的元数据来告诉模型怎么解压。这些元数据听起来很小,但积少成多,往往会把压缩带来的收益全部抵消掉。
TurboQuant如何实现“无损瘦身”?
Google的TurboQuant正是为此而生。研究人员设计了一套两阶段的数学解法,巧妙地绕开了传统瓶颈。
第一阶段:PolarQuant(极坐标量化)
这一阶段的核心是一个聪明的几何变换。研究人员把数据向量从传统的笛卡尔坐标系(用X, Y, Z坐标表示)转换成极坐标系(用半径和角度表示)。
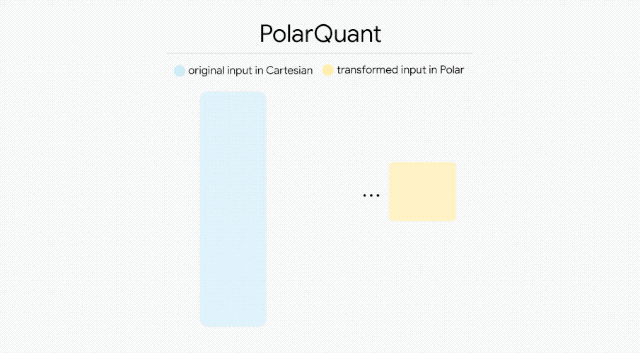
这个变换的妙处在于:转换后,向量“角度”的分布变得高度有规律且可预测。模型不再需要为每个数据块单独存储昂贵的归一化常数,可以直接映射到固定的圆形网格上,这部分开销几乎为零。
第二阶段:QJL(量化Johnson-Lindenstrauss变换)
第二阶段充当数学层面的“纠错器”。它把第一阶段压缩后可能残留的微小误差,投影到一个更低维的空间中,再把每个误差值压缩成一个简单的符号位(+1 或 -1)。
这个精妙的设计保证了AI在后续计算“注意力分数”(即判断上下文中哪些词更关键)时,使用压缩版数据得到的结果,与使用高精度原始数据在统计意义上完全一致。
如果说以前AI记笔记是“逐字逐句抄写”,那么TurboQuant就像发明了一套“极简速记符号”:该记的信息一个不漏,占用的空间却少了六倍。
实测数据:性能与效率兼得
光有理论不够,硬核的实测数据才是关键。TurboQuant在多项基准测试中都交出了亮眼的成绩单。
- 精度零损失:在需要从超长文本中精准定位信息的“大海捞针”测试中,TurboQuant在Llama-3.1-8B和Mistral-7B等主流开源模型上实现了100%的召回率。
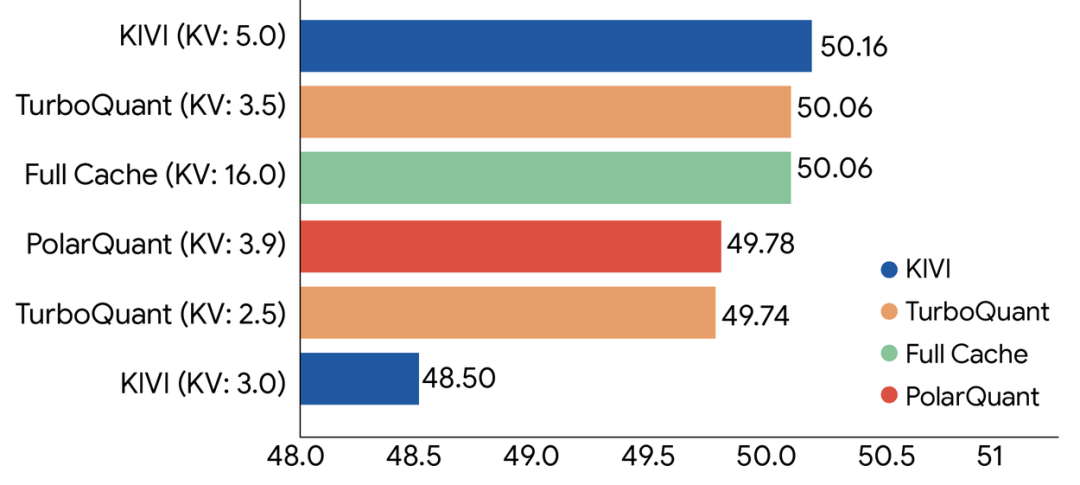
- 全面领先:在涵盖问答、代码生成、长文摘要的LongBench综合评测中,TurboQuant全面追平甚至超过了此前最强的基线方法KIVI。
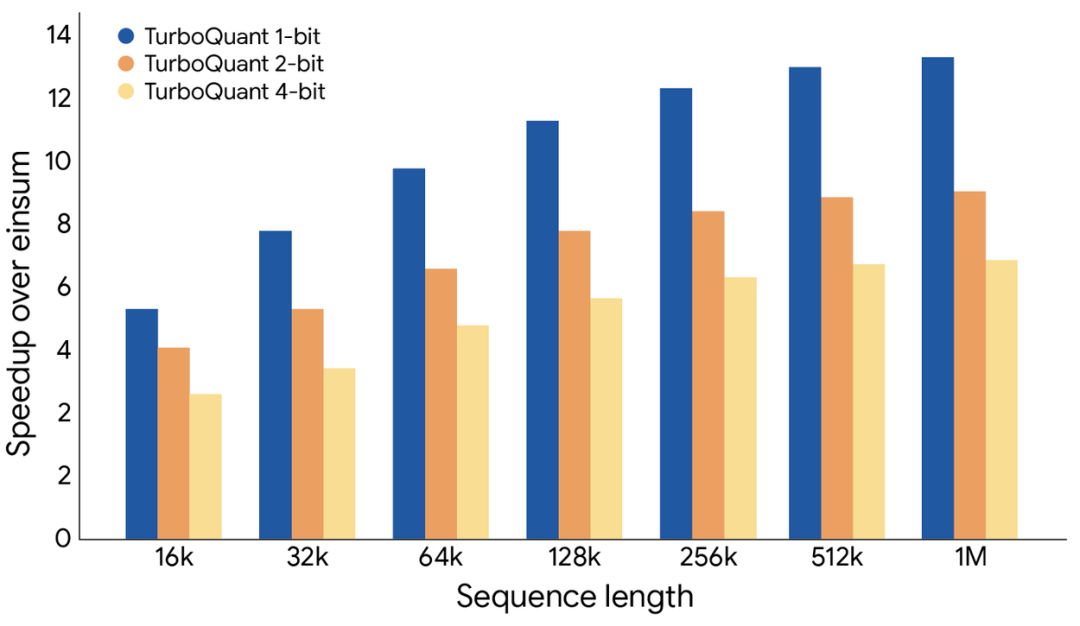
- 速度飞跃:最硬的数字来自英伟达H100 GPU的实测。结果显示,4位精度的TurboQuant在计算核心的注意力机制时,速度比未压缩的32位方案快了整整8倍。并且,序列越长,加速效果越明显。
这套方法还有一个对开发者与企业格外友好的特性:无需重新训练模型。现有的开源模型或已经微调好的专属模型,可以直接套用TurboQuant进行推理,无需准备额外数据或重新进行耗时费钱的训练流程。
社区的“DeepSeek时刻”?
论文发布后24小时内,AI开发者社区就已经开始行动验证。Apple Silicon MLX框架的知名开发者@Prince_Canuma将算法移植到MLX框架,并测试了Qwen3.5-35B模型。

他的测试覆盖了从8500到64000的上下文长度,每个量化等级都跑出了100%的精确匹配。他还发现,2.5位的TurboQuant能将KV Cache的显存占用压缩近5倍,且准确率零损失。
| config |
exact match |
avg cache GB |
vs full |
| full |
6/6 |
0.703 |
1.0x |
| TurboQuant 2.5 |
6/6 |
0.143 |
4.9x smaller |
| TurboQuant 3.5 |
6/6 |
0.185 |
3.8x smaller |
对于TurboQuant的发布,Cloudflare的CEO Matthew Prince甚至将其称为Google的“DeepSeek时刻”。他在推文中暗示,AI推理在速度、内存使用等方面仍有巨大优化空间。
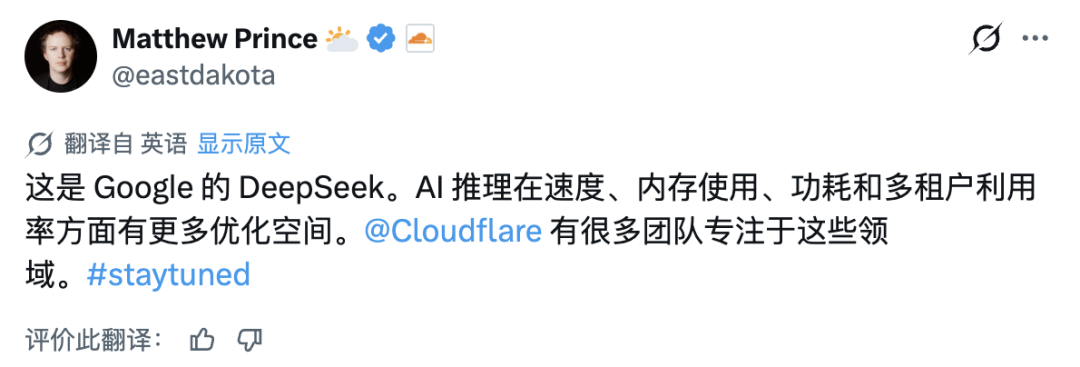
这个类比意味深长。一年前,DeepSeek以极高的成本效率训练出强大模型,打破了“高成本才能出高性能AI”的迷信。而TurboQuant则可能从另一个维度——推理效率——再次冲击行业。如果这项技术能大规模应用,其商业价值将肉眼可见:同样一张H100显卡,推理成本有望直接减半;端侧部署门槛也将大幅降低,以前只能在云端运行的大模型,未来在Mac Mini或本地服务器上也能流畅运行。
技术革新 vs. 市场反应:是颠覆还是过虑?
市场的反应,已经说明了部分投资者对此技术的重视程度。TurboQuant发布当天,存储芯片板块的下跌,反映出一种担忧:如果AI巨头能用一套纯软件算法把显存需求砍掉一大半,那么过去两年支撑存储股估值的核心逻辑之一——“AI对高带宽显存的需求只会无限增长”——就被动摇了。

当然,业内也不乏冷静的声音。有网友尖锐指出,这篇论文的底层研究早在去年四月就已公开在arXiv上,并非横空出世,当下的热潮有炒作旧闻之嫌。在他看来,存储股因一篇算法论文大跌,恰恰暴露了市场中有多少参与者没搞清技术的边界。
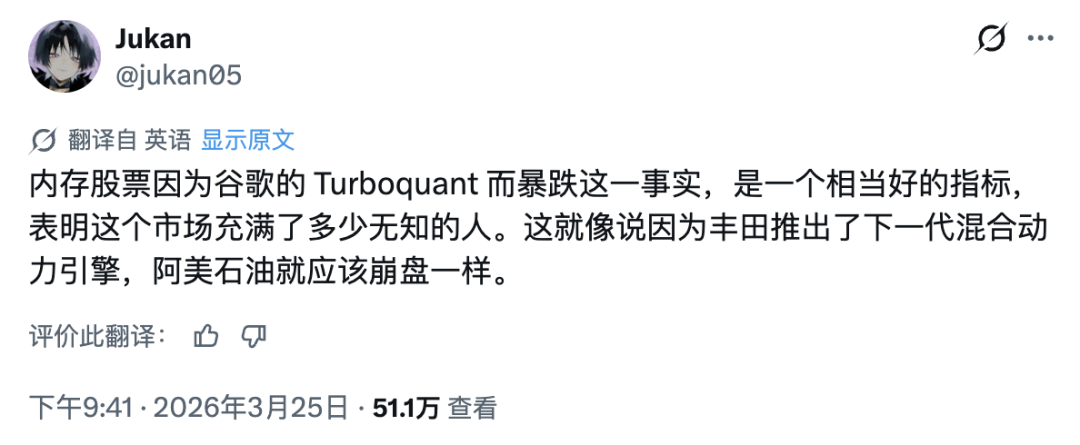
他将这波市场反应类比为“因为丰田推出了下一代混合动力引擎,所以阿美石油就应该崩盘”,认为其逻辑荒谬。
泼冷水是有必要的。一方面,历史上存在“杰文斯悖论”:效率提升往往不会减少总消耗,反而因为成本降低而刺激更多需求,导致总消耗量上升。AI推理变得更便宜,可能意味着会有更多应用、更频繁的使用,最终消耗的总算力与显存未必减少。
另一方面,TurboQuant目前仍处于实验室论文阶段。根据消息,Google计划在接下来的ICLR 2026等顶级学术会议上正式展示这项技术。但从论文到大规模生产部署,中间还隔着工程适配、不同硬件架构的兼容性测试、真实复杂场景的性能验证等诸多关卡,每一步都不轻松。
更重要的是,TurboQuant目前瞄准的是推理阶段的显存瓶颈。而训练一个大型AI模型所需的巨大算力与显存,依然是另一座难以逾越的成本大山。这项技术并未改变训练阶段的天文数字需求。
结语
在《硅谷》的剧情里,Pied Piper的压缩算法最终改变了整个互联网。在现实中,TurboQuant的野心或许没那么宏大,它的目标现实而具体:让AI在有限的物理硬件资源里,记得更多、算得更快、跑得更便宜。
现实终究不是好莱坞剧本。不必彻底改变互联网,能让我们的AI助手聊得更久、不再中途“失忆”报错,对于广大开发者和用户而言,已经是一个足够激动人心的进步。这项关于AI模型压缩的技术探索,无疑为后续的效率优化打开了新的思路。技术的每一次突破,都值得我们在像云栈社区这样的开发者社区中持续关注和深入讨论。
相关资源:
 发表于 2026-3-27 02:55:50
|
查看: 107|
回复: 0
发表于 2026-3-27 02:55:50
|
查看: 107|
回复: 0
