在MySQL中设计表时,官方推荐使用连续自增的主键ID(AUTO_INCREMENT),而不是UUID或不连续不重复的雪花ID。为什么不建议采用UUID等随机值作为主键?使用它们究竟会带来哪些性能问题?本文将深入探讨这一问题。
一、实验准备与测试
为了直观地对比不同主键策略的差异,我们建立三张结构相同、仅主键生成策略不同的表:
- user_auto_key:使用自增ID (
AUTO_INCREMENT)。
- user_uuid:使用UUID作为主键。
- user_random_key:使用雪花算法生成的随机Long型ID(一串18位不连续的数字)。
表结构示例:
- id自增表:
id bigint(20) NOT NULL AUTO_INCREMENT
- 用户uuid表:
id varchar(32) NOT NULL
- 随机主键表:
id bigint(20) NOT NULL
我们使用 SpringBoot + JdbcTemplate 编写测试程序,在相同环境下,向每张表插入同等数量的随机数据,并记录插入耗时。
核心测试代码片段:
@Test
void testDBTime() {
StopWatch stopwatch = new StopWatch("执行sql时间消耗");
// 测试自增ID表插入
final String insertSql = "INSERT INTO user_key_auto(user_id,user_name,sex,address,city,email,state) VALUES(?,?,?,?,?,?,?)";
List<UserKeyAuto> insertData = autoKeyTableService.getInsertData();
stopwatch.start("自动生成key表任务开始");
long start1 = System.currentTimeMillis();
if (CollectionUtil.isNotEmpty(insertData)) {
boolean insertResult = jdbcTemplateService.insert(insertSql, insertData, false);
}
long end1 = System.currentTimeMillis();
System.out.println("auto key消耗的时间:" + (end1 - start1));
stopwatch.stop();
// 测试UUID表插入(代码类似,略)
// 测试随机ID表插入(代码类似,略)
System.out.println(stopwatch.prettyPrint());
}
二、测试结果分析
初始数据量130万时,插入10万数据的性能对比:
| 主键类型 |
耗时(近似) |
自增ID (AUTO_INCREMENT) |
约 7.5 秒 |
| 随机Long ID (雪花ID) |
约 21 秒 |
| UUID |
约 39 秒 |
结论: 在大数据量插入场景下,性能排名为:自增ID > 随机ID(雪花ID)> UUID。UUID的插入效率最低,且随着数据量增长,其性能下降更为明显。
三、性能差异的底层原理
为何不同的主键策略会导致如此巨大的性能差距?这需要从 InnoDB索引的物理结构 说起。
1. 使用自增ID的索引结构
自增ID的值是连续递增的。
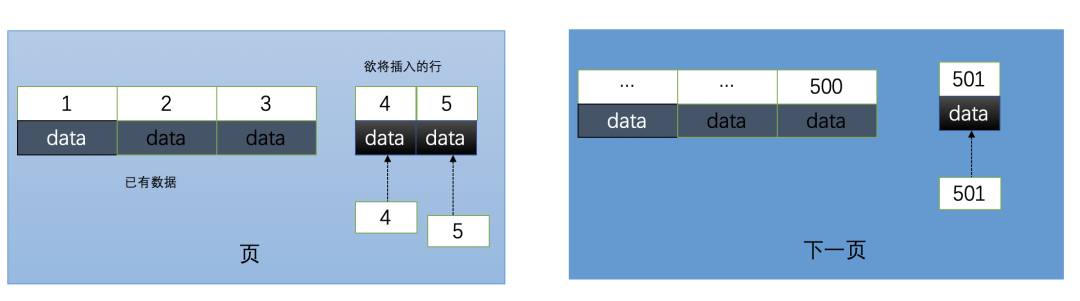
- 顺序写入:新插入的数据行总是位于索引B+树的最右叶节点,即当前最大ID的后面。这种操作近乎顺序I/O,效率极高。
- 高页填充率:数据按顺序填满页,能充分利用存储空间(默认填充因子15/16),减少页碎片。
- 避免页分裂:由于总是追加写入,极大降低了因插入中间值而导致索引页分裂的概率。
2. 使用UUID/雪花ID的索引结构
UUID或雪花ID的值是无序的。
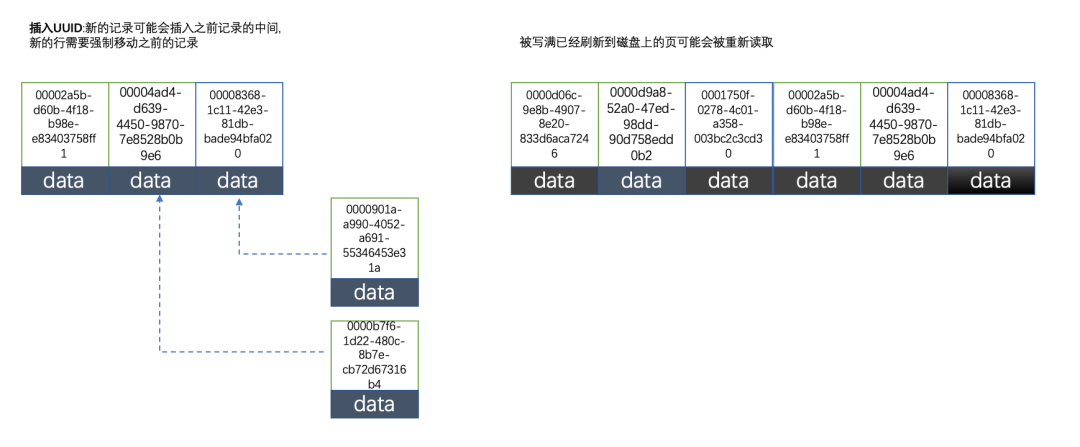
- 随机写入:新行的主键值无法保证比之前的大,InnoDB需要为它寻找合适的插入位置(可能在已有的数据页中间)。
- 大量页分裂与碎片:为了给新数据腾出空间,InnoDB不得不频繁进行页分裂。这会导致:
- 随机I/O增加:目标数据页可能不在内存中,需要先从磁盘读取。
- 数据移动开销:页分裂需要移动大量已有数据。
- 空间碎片化:频繁分裂使数据页填充不规则,产生碎片,降低空间利用率和后续查询性能。
这正是UUID插入性能远低于自增ID的根本原因。关于数据库索引的深入优化,可以参考云栈社区的数据库/中间件板块,里面有更多关于MySQL性能调优的实战内容。
3. 自增ID的潜在缺点
当然,自增ID也并非完美,存在一些需要注意的点:
- 信息可推测性:自增ID可能暴露业务数据量或增长趋势。
- 高并发插入热点:所有插入都集中在索引最右端,在极高并发场景下可能形成锁争用。
- 自增锁开销:
AUTO_INCREMENT的锁机制(可通过innodb_autoinc_lock_mode参数调优)在特定场景下会带来一定的性能损耗。在实际开发中,合理使用例如SpringBoot等框架的事务管理,有助于理解和优化这类并发控制问题。
四、总结与选型建议
通过实验测试和原理分析,我们可以清晰地看到:
- 性能上:自增ID在写入性能上具有压倒性优势,尤其适合写入密集型的应用。
- 适用场景上:
- 自增ID:是绝大多数场景下的默认推荐选择,简单高效。
- UUID / 雪花ID:适用于需要全局唯一、分布式生成、或不希望暴露业务顺序的场景。但必须意识到其带来的写入性能损耗,并做好数据碎片整理(如定期
OPTIMIZE TABLE)的准备。
MySQL的设计博大精深,深入理解其存储引擎的工作原理,对于进行高效的数据库设计至关重要。在选择主键策略时,应综合考虑数据量、并发度、分布式需求以及安全性等因素,没有绝对的最优解,只有最适合当前场景的平衡之选。 |  发表于 2025-12-10 04:11:41
|
查看: 202|
回复: 0
发表于 2025-12-10 04:11:41
|
查看: 202|
回复: 0
