最近在技术圈引起热议的字节跳动开源项目 DeerFlow,很容易被简单归类为又一个“深度研究”框架。但如果你真的去研究它的代码和架构,会发现它的野心远不止于此。版本 2.0 的彻底重构,标志着它正从单一的研究工具转向一个更具普适性的 AI Agent 运行时底座。
那么,DeerFlow 到底是什么?它的 README 给出了一个直接的定义:Deep Exploration and Efficient Research Flow(深度探索与高效研究流)。然而,从 1.x 到 2.0 的变化并非仅仅是版本号的升级。开发团队明确指出,2.0 是一次彻底的重写,与 1.x 分支代码不互通。原版的 Deep Research 框架仍在 main-1.x 分支维护,而主分支已全力投入 2.0 的开发。这个信号表明,团队的目标已经从一个特定的应用场景,扩展到了一个更宏大、更底层的方向。
简单理解,你可以把 DeerFlow 2.0 看作:
- 前台:一个具备聊天交互界面的 AI Agent 应用。
- 后台:一套专为复杂、长时间运行任务设计的 Agent 运行时系统。
- 核心价值:其重点不在于让 AI 的“回答”更聪明,而在于能否稳健地处理“任务分解、执行、上下文管理、工具调用、外部集成,并持续运行”这一整套工程挑战。这正是它区别于众多“一次性演示”型 Agent 项目的关键。
它要解决的是什么问题?
许多 AI Agent 项目停留在了演示层面:大模型 + 联网搜索 + 网页抓取 + 一个漂亮的 UI,然后展示“帮我研究某个主题”。初次体验令人惊艳,但一旦试图将其融入实际工作流,各种工程问题便接踵而至:长上下文如何管理?复杂任务如何拆解与调度?生成的文件存放在哪里?如何安全、灵活地扩展工具链?又如何对接不同的消息渠道?
DeerFlow 所构建的,正是解决这整层问题的运行时基础设施。从官方架构图可以清晰地看出,它将系统清晰地解耦为三层:
- LangGraph Server:负责 Agent 运行时、线程状态管理和 SSE 流式响应。
- Gateway API:负责模型集成、技能(Skills)、MCP(模型上下文协议)工具、文件上传与产物管理等非对话层的能力聚合。
- Frontend:基于 Next.js 构建的聊天界面与管理工作台。
这三层通过 Nginx 反向代理统一暴露在 2026 端口。这种架构设计体现了强烈的工程化思维,将前端展示、核心运行时、配置管理、外部扩展等关注点分离,而非将所有逻辑混杂在一个单体 Web 应用中。
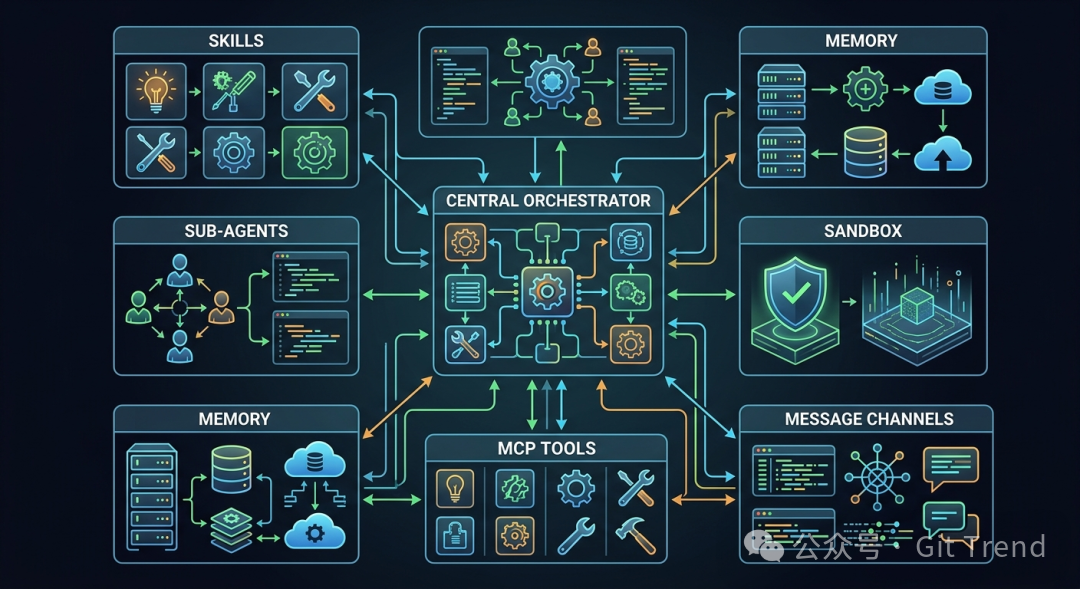
DeerFlow 的核心价值在于这套运行时底座,它将编排器(Orchestrator)、技能、子代理、记忆、沙箱、MCP 工具和消息通道统一整合进了一个可扩展的工作框架中。
深入核心:五个值得关注的设计亮点
1. Skills:作为结构化能力模块,而非提示词附件
DeerFlow 将 Skill(技能)视为结构化的能力模块,而不仅仅是“在系统提示词中插入一段功能描述”。项目仓库中的 skills/ 目录分为 public 和 custom 两类,每个技能都是一个包含 SKILL.md 说明文件的独立单元,甚至可以包含 Frontmatter 元数据。系统加载器会扫描目录、解析这些文件,并根据 extensions_config.json 的配置来决定启用状态。
这种设计的现实意义在于:工作流知识可以独立沉淀和版本化管理,技能可以按需启停、替换,并能根据任务进度渐进式加载,有效避免了在任务伊始就将所有上下文塞满模型,导致成本激增和效果下降。项目 README 也特别强调了“渐进式加载”这一点,这比许多追求“全量一次性注入”的系统要务实得多。
2. Sub-agent:作为运行时的一等公民
很多项目声称支持多智能体(Multi-Agent),但实现往往只是预设了几个具有不同角色的提示词(Prompt)。DeerFlow 则不同,在 subagents/executor.py 中,你可以找到独立的 SubagentExecutor 类、明确的任务状态枚举、后台任务池、超时控制以及结果回收逻辑。在这里,子代理是真正可以在后台异步执行的单元。
它首先解决了以下基础问题:
- 状态管理:定义了
PENDING(等待)、RUNNING(运行中)、COMPLETED(完成)、FAILED(失败)、TIMED_OUT(超时)等状态。
- 并发控制:将任务调度池与实际执行池分离。
- 超时机制:可为每个子代理单独设置超时时间。
- 结果保留:保存执行的
ai_messages 和最终结果,便于主代理进行结果汇总和决策。
这不再是“在一次对话中模拟多个角色发言”,而是为长周期、多步骤任务设计的运行时机制。
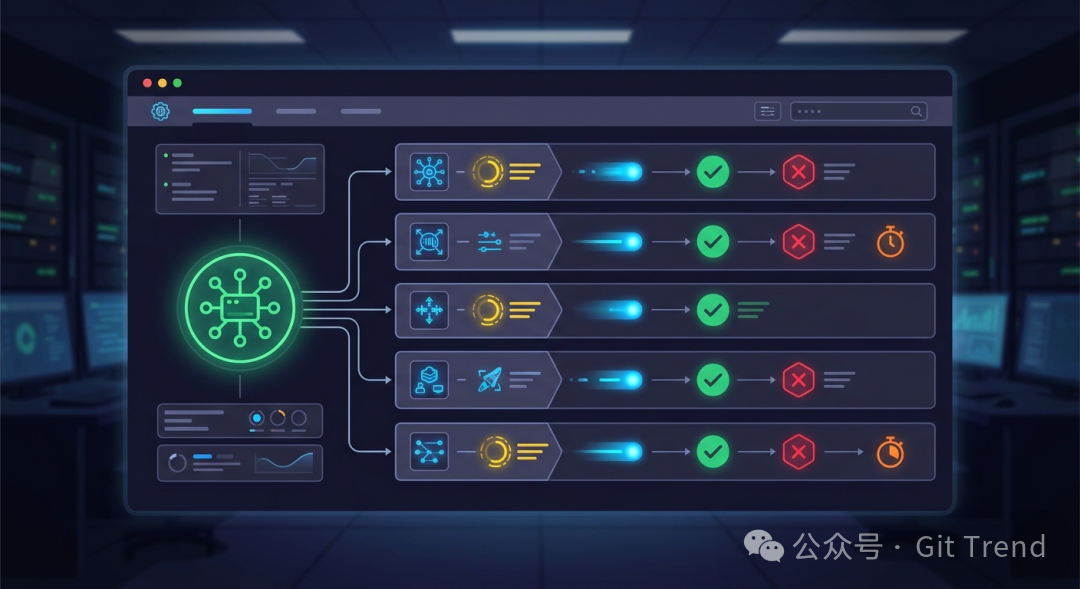
子代理在 DeerFlow 中拥有完整的生命周期管理,包括并发执行和状态流转,而非简单的角色扮演。
3. Sandbox:默认的安全执行环境,而非可选功能
README 中有一句非常精准的判断:真正的区别不在于“是否有工具的聊天机器人”,而在于“是否拥有真正的、隔离的执行环境”。
DeerFlow 默认将沙箱(Sandbox)作为核心能力来阐述,并且支持多种模式以适应不同场景:
- 本地进程执行
- Docker 容器内执行
- 通过 Provisioner 在 Kubernetes Pod 中执行
如果你只是构建演示,本地执行最快;但若期望 Agent 能够持续、安全地读写文件、执行系统命令、处理用户上传的产物,没有隔离层几乎是不可行的。DeerFlow 甚至细致地规划了虚拟路径映射,将工作区、上传目录、输出目录统一管理。这一点看似琐碎,实则至关重要,因为它直接关系到文件系统的清晰性和任务的可复现性。
4. Memory、Summary 等能力被中间件化
评估一个 Agent 系统的成熟度,一个好方法是看它如何处置那些“不属于核心推理链路,但长期运行必不可少”的辅助能力。
DeerFlow 采用了中间件(Middleware) 模式。在 lead_agent/agent.py 中,主代理的中间件链依次串联了 Summarization(总结)、Title(生成标题)、Memory(记忆)、ViewImage(查看图片)、Clarification(澄清)、LoopDetection(循环检测)、Todo(待办事项)、SubagentLimit(子代理限制)等功能。
这样做的好处是边界清晰,未来替换、增删、调整执行顺序都变得可控。尤其是 Summary + Memory 的组合,非常贴近真实生产环境的需求:总结用于压缩当前会话的上下文,防止超出模型限制;记忆则用于跨会话持久化用户信息和偏好。
5. 周全的外部生态系统接入
DeerFlow 的定位不是一个仅供 Web 访问的孤立应用。其文档已经明确支持接入 Telegram、Slack、飞书(Lark) 等主流消息平台,并且是按照各平台推荐的传输方式配置的,如 Telegram 的长轮询、Slack 的 Socket Mode、飞书的 WebSocket。
在工具扩展层面,它对 MCP(Model Context Protocol) 的支持也相当深入。extensions_config.json 支持配置 stdio、sse、http 三种 MCP Server 接入方式,并为 HTTP/SSE 方式补充了 OAuth token 的获取与刷新逻辑。
这表明,DeerFlow 旨在构建一套能够灵活嵌入网页、即时通讯工具乃至其他外部系统的 Agent 能力基座。
如何快速上手与评估?
如果你希望快速理解 DeerFlow 的核心,不建议一开始就陷入所有特性的细节。建议按照以下“最短上手闭环”进行:
最短上手步骤
git clone https://github.com/bytedance/deer-flow.git- 在项目根目录执行
make config 生成初始配置文件。
- 编辑
config.yaml,至少配置一个可用的 AI 模型终端。
- 在
.env 文件中填入对应模型的 API Key。
- 运行官方推荐的启动命令:
make docker-start。
- 打开浏览器,访问
http://localhost:2026。
如果你不想使用 Docker,也可以选择本地开发模式,但前提是备齐所需环境:Node.js 22+、pnpm、uv、nginx 等。仓库也提供了 make check 和 make install 等辅助命令。
一个值得注意的细节是,README 中的配置示例已将 Codex CLI 和 Claude Code OAuth 列为模型供应商。这暗示其目标用户不仅包括调用云端 API 的开发者,也涵盖了那些日常已在终端使用 CLI 形态 AI 工具的高级开发者群体。
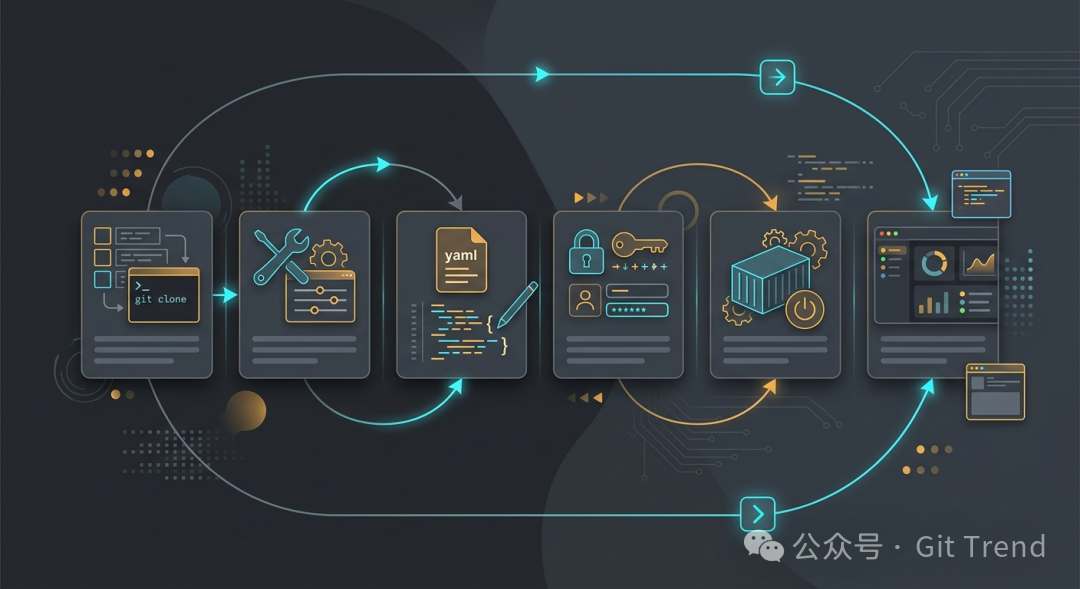
从克隆仓库到本地运行,DeerFlow 提供了清晰的上手路径。
谁适合,谁不适合?
适合的开发者/团队
- 希望搭建属于自己的、可掌控的 AI Agent 工作台,而非依赖封闭的 SaaS 服务。
- 已经在探索或计划使用 LangGraph、MCP、技能编排、安全沙箱等基础设施。
- 有需求让 AI Agent 实际处理文件操作、异步长任务、多阶段复杂工作流。
- 希望从特定的“深度研究”场景,迈向更通用的、可编程的 Agent 运行时。
可能不适合的情况
- 仅想要“一条命令启动,即刻能用的网页搜索助手”。
- 不关心运行时架构、权限安全、扩展性、沙箱隔离和配置管理,只追求现成的、开箱即用的结果。
- 不愿意投入精力维护部署、更新配置和模型密钥。
简而言之,DeerFlow 并非一个“零配置、五分钟获得幸福感”的消费级产品。它更像一个已经搭好核心骨架、等待你按需填充血肉的 AI Agent 系统底座。它的核心价值也正在于此。
最后的判断
DeerFlow 值得我们关注,并非因为它再次讲述了“深度研究”的故事,而是因为它正在认真尝试回答一个更困难的问题:当 AI Agent 不再是一次性的对话玩具,而要成为能够长期接管任务、自主分解、安全执行、并无缝集成到现有工作流中的“数字员工”时,其底层的技术基座究竟应该如何构建?
这或许也是它在 GitHub 上获得快速增长的原因。许多开发者在表面上是寻找“下一个好用的 AI 项目”,实质上是在寻找一套能够承载复杂、规模化智能工作流的可靠基础设施。DeerFlow 2.0 的探索,恰好踩在了这个技术演进的关键节点上。
 发表于 2026-3-27 04:46:13
|
查看: 262|
回复: 0
发表于 2026-3-27 04:46:13
|
查看: 262|
回复: 0
