3月27日消息,谷歌于昨日凌晨正式发布了其迄今最高质量的音频与语音模型——Gemini 3.1 Flash Live。这款专为实时语音交互优化的模型,已同步在Gemini App、Search Live以及Google AI Studio中开放,后者以预览版形式向开发者提供。
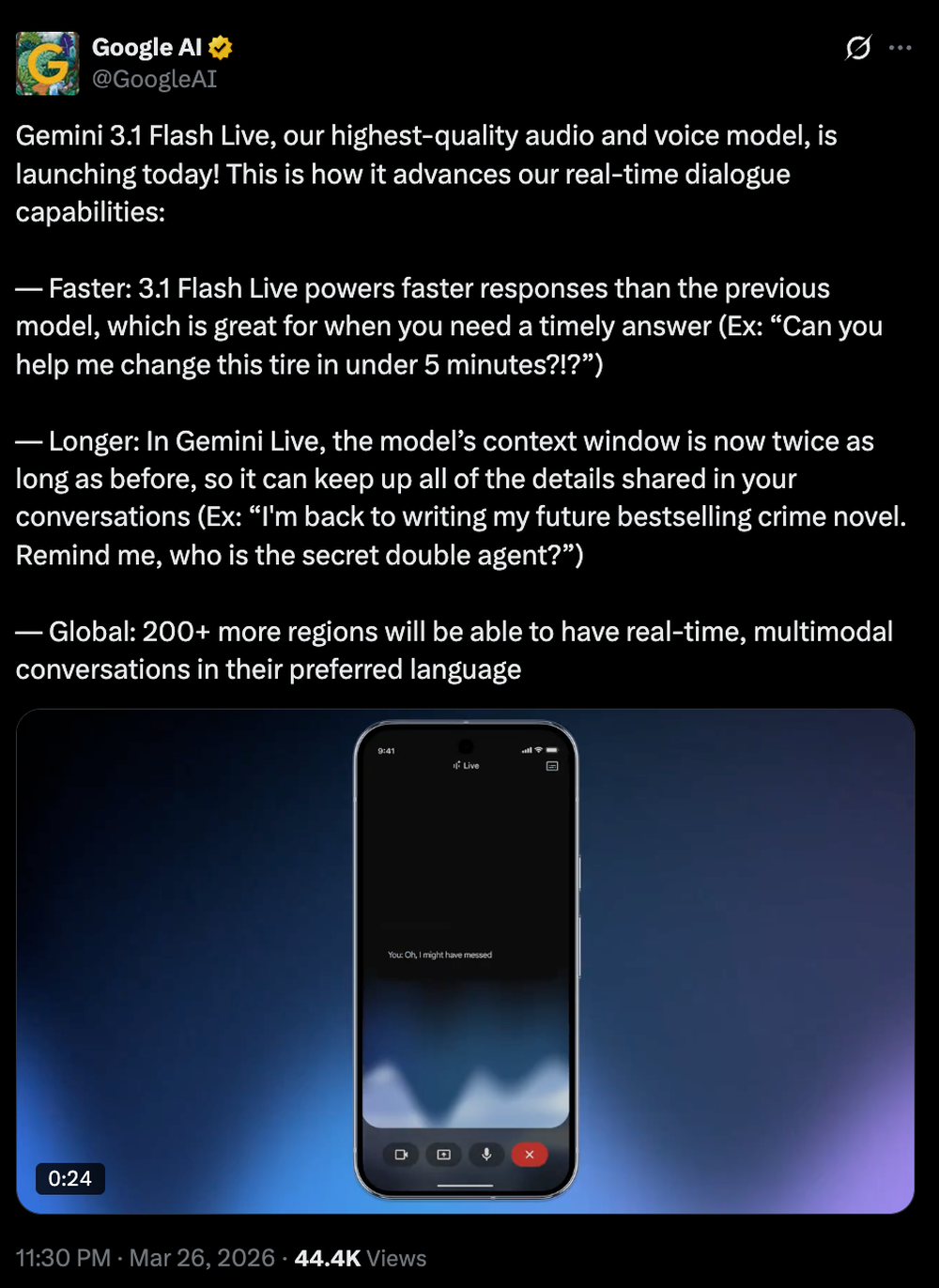
此次更新的核心在于实时语音Agent能力的全面升级。语音现在能够直接驱动应用开发(即vibe coding),同时,Gemini App的实时多模态对话能力也得到了增强。从公开的评测数据看,该模型在多项关键测试中超越了包括GPT-Realtime-1.5、Qwen3 Omni 30B A3B Instruct、GPT-4o Audio preview在内的多个竞品。
模型一经发布,便被海外社区视为对Siri等现有语音助手的一次强力挑战。巧合的是,就在同一天,有外媒爆料称苹果将在2026年WWDC上主推AI并发布新版Siri,且苹果已获得谷歌完整Gemini模型的直连权限,计划通过蒸馏技术自研轻量化端侧AI部署于iPhone。
性能提升:响应、记忆与精准度的飞跃
Gemini 3.1 Flash Live针对连续对话场景进行了整体优化,重点提升了响应延迟、上下文记忆、多语言支持及工具调用等关键能力。
- 更长的记忆:Gemini Live中的上下文窗口长度提升至此前的2倍,能够更好地保持对话细节。
- 更广的覆盖:Search Live现支持在超过200个国家和地区进行多语言实时交互。
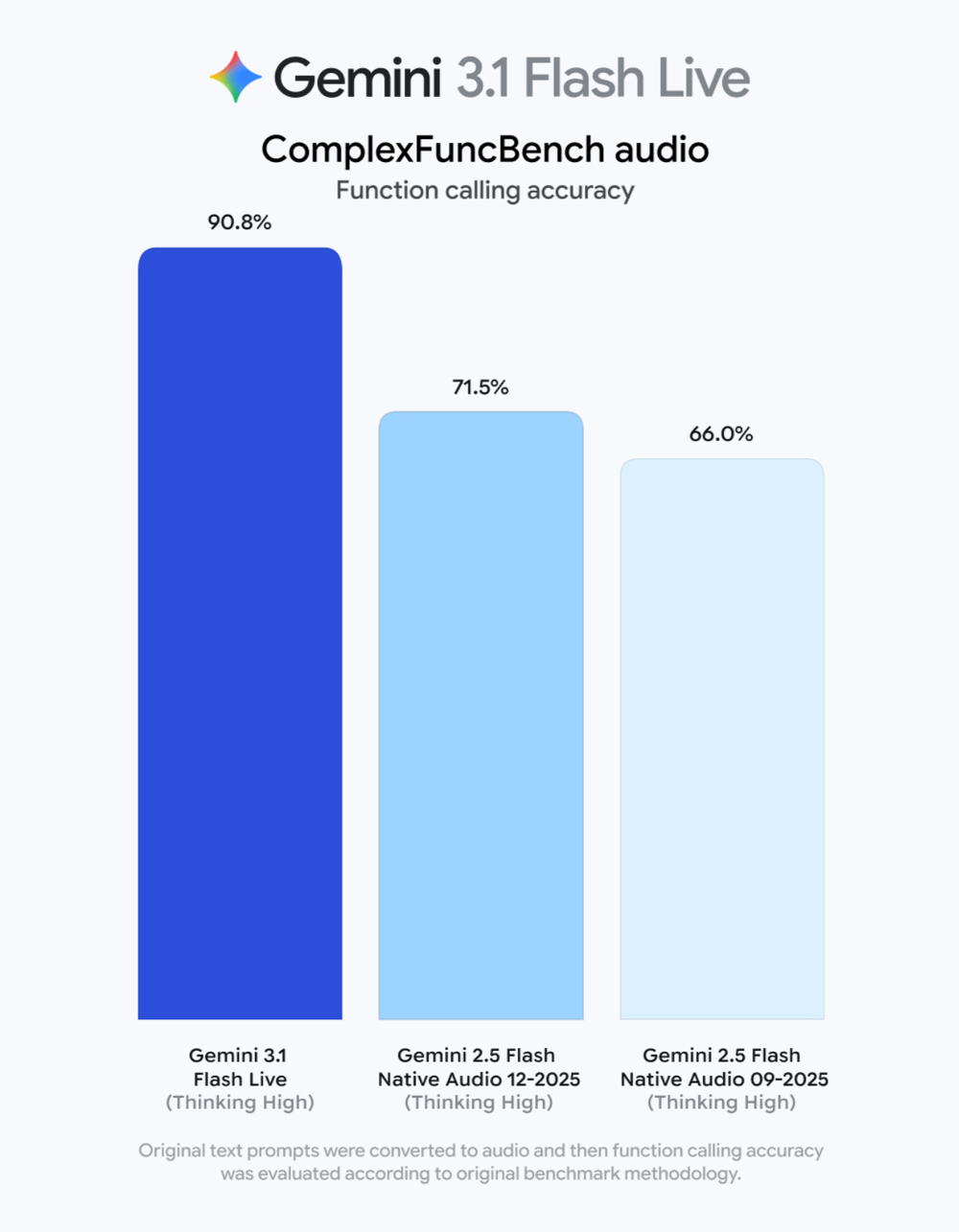
- 更强的功能调用:在ComplexFuncBench audio基准测试中,Gemini 3.1 Flash的函数调用准确率达到了90.8%,显著高于去年12月版本(71.5%)和去年9月版本(66.0%)。
- 领先的音频输出:在Scale平台的Audio MultiChallenge音频输出榜单中,该模型以36.1%的得分位列前列,高于GPT-Realtime-1.5(34.7%)、Qwen3 Omni 30B A3B Instruct(24.3%)等模型。

此外,新模型在实时对话体验上做了细致打磨:对语调、语速和停顿的感知更为细腻;在嘈杂环境下的背景噪音过滤能力增强;在复杂指令场景中,对系统约束的遵循能力也有所提升。已有用户尝试用语音指令让模型生成简短的演唱片段,这类创意交互已能在对话中被直接触发。
定价与社区反馈
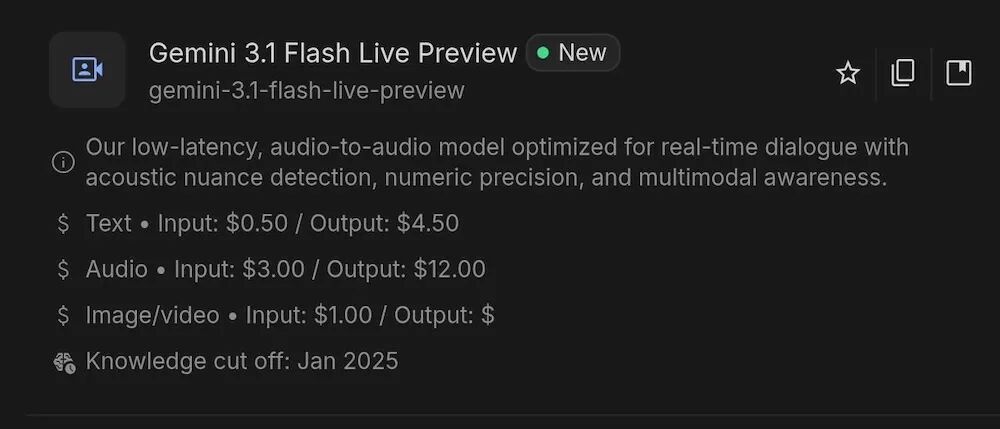
谷歌也同步公布了该模型的API价格:
- 文本:输入每百万Token 0.50美元,输出4.50美元。
- 音频:输入每百万Token 3.00美元,输出12.00美元。
- 图像/视频:输入每百万Token 1.00美元。
模型发布后,技术社区反应迅速。有网友评价这是一次“强势更新”,认为“更快的语音响应是一种用户体验层面的关键突破”,若能保持低延迟和多轮对话的一致性,语音交互的普及速度将会加快。
当然,也有开发者持谨慎态度。有人直言曾因语音模型回复质量远不如文本而放弃使用,并质疑这一现状是否真正得到了改变。
初步体验显示,其中文语音表现仍略显机械,且在多轮对话中可能出现中断,其宣称的连续交互能力有待进一步验证。目前,该更新正分批向iOS和安卓用户推送。
核心场景:开口改代码的“vibe coding”
本次发布最引人注目的演示之一是 “语音驱动应用开发(vibe coding)” 。在Google AI Studio中,开发者可以像与设计师沟通一样,通过纯语音实时修改应用界面。
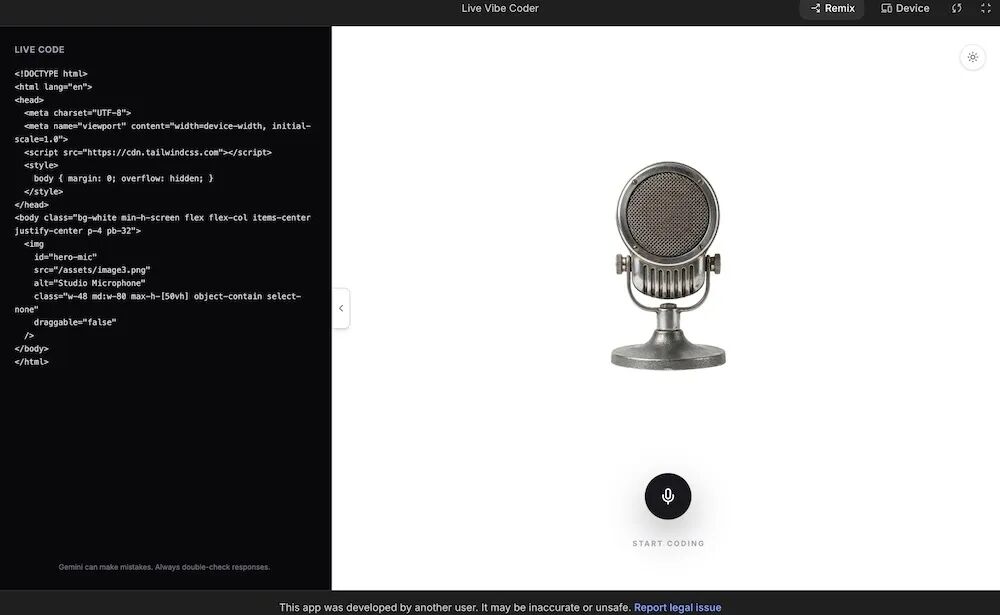
演示中,用户只需说出指令:“把麦克风做大一点”,界面元素随即调整;紧接着补充“背景加点黄色波点”,页面背景立刻更新。后续如“加入鼠标悬停反馈效果”、“让背景图案持续滚动”,甚至中途改变主意要求“整体改成波普风格”,所有修改都在一段连续的对话中流畅完成,实现了真正的实时、动态编码交互。这种将Agent能力深度融入开发流程的场景,展示了人工智能作为生产工具的新范式。
多元落地:设计、陪伴与游戏
除了开发,谷歌还展示了该模型在三个不同场景下的应用潜力:
- 设计协作:在设计工具Stitch中,用户可通过语音直接编辑界面。从切换模式到调整视觉细节(如“让数字更贴合圆形”、“试一个偏棕色的木质配色”),指令能被快速理解并执行,极大提升了设计迭代效率。
- 跨语言陪伴:在面向老年用户的AI硬件Ato的案例中,模型展现了强大的多语言连续对话能力。用户可以用英语聊天,然后无缝切换条件:“我要跟奶奶说话,但她只会西班牙语”,对话便能以西班牙语继续,且上下文不丢失,实现了自然的跨语言陪伴交流。
- 游戏角色互动:在RPG游戏《Wit‘s End》中,语音用于驱动游戏内角色。玩家就角色的实体形态、能力来源等问题提问时,模型能始终保持在角色设定内进行回应,语气和世界观保持一致,增强了游戏的沉浸感。
竞争态势:全栈能力与本土化路径并行
从此次发布可以看出,谷歌正致力于构建一套完整的“全栈语音Agent”能力体系。无论是vibe coding、硬件交互还是移动端入口,其语音能力正快速渗透到多种场景中。
在产品形态上,Gemini App与国内的豆包等产品类似,都以对话为核心入口。但在体验侧重上有所不同:豆包在中文语境、语气互动和用户黏性构建上更具优势;而谷歌目前更侧重于拓展能力的边界,尤其是在类似vibe coding这类需要高强度、连续逻辑交互的场景中,展现了领先性。
与此同时,国内厂商在语音模型能力上也进展迅速。例如,阶跃星辰的Step-Audio R1.1曾在Artificial Analysis语音推理榜单中获得第一,显示了国内团队的技术实力。
当前的竞争格局已经清晰:一方在持续拉高语音Agent的技术上限,试图覆盖更复杂的应用场景;另一方则在用户规模和模型能力上双线推进。语音Agent的赛场,正变得越发拥挤和激烈。对于开发者而言,关注这些前沿动态并思考如何将其融入自己的前端或全栈项目,将是把握下一代交互趋势的关键。
 发表于 2026-3-27 23:46:45
|
查看: 194|
回复: 0
发表于 2026-3-27 23:46:45
|
查看: 194|
回复: 0
