前面几篇我们其实一直在沿着同一条线往前写。
从《Skills 详解》聊到《Codex 为什么能又快又稳》,主线都差不多:AI 编程真正拉开差距的,不是模型突然更会写代码了,而是团队有没有把上下文、经验和默认流程提前写进系统。
Matt Van Horn 这篇原文,刚好把这条线又往前推了一层。
Kevin Rose 在 X 上问了一个很典型的问题:现在该用什么 IDE 配 AI 编程?Matt 的回答很短,也很有攻击性:不用 IDE,只用 plan.md 和语音。
如果只看这句话,很容易把它理解成又一个“命令行比 IDE 更高级”的姿态。但把原文和他最近的实践放在一起看,重点根本不在这里。按他自己给出的数据,最近 30 天里,他已经积累了 70 份 plan.md、263 次 commit,还持续给 Python、OpenCV、Vercel Agent Browser、Zed、Compound Engineering 等项目提交改动。
所以本文真正值得拆的,不是一个高手装了哪些工具,而是他怎么把开发工作流重写成另一种形态:先研究,后计划,再执行;先把上下文压进 plan.md,再让 AI 去消耗它。
我们在《AI编程实践:从 Claude Code 到团队协作的 6 个落地抓手》里,其实已经讲过一次类似的问题:Claude Code 上手容易,用顺很难。难的不是记住命令,而是把“聊天”改成“协作协议”。Matt 这篇原文补上的,是更靠近一线使用习惯的那部分。不是抽象方法论,而是一组已经跑进日常工作流的实战动作。
太长不看版
- 本文最值钱的,不是“Claude Code 还能这么玩”,而是它把
plan.md 推到了工作流中枢的位置。
- Matt 的真正升级,不是工具装得多,而是把截图、语音、会议、社区信息都变成了 planning 输入。
/last30days 不是一个搜索技巧,而是一套工程化的研究引擎:10 个来源并发、两阶段搜索、多信号评分、自动存档,已经 455+ 测试。- 4 到 6 个会话并行不是炫技,前提是调研、计划、执行、验证已经被拆成了不同状态。
- 这套方法对个人很强,对团队更有价值,因为它逼着我们把隐性上下文显性化。
- 但它也有边界:没有测试、没有 review、没有回滚纪律,只开危险权限,效率不会自动变高。
先看一张总览图,Matt 这套工作流大概长这样:
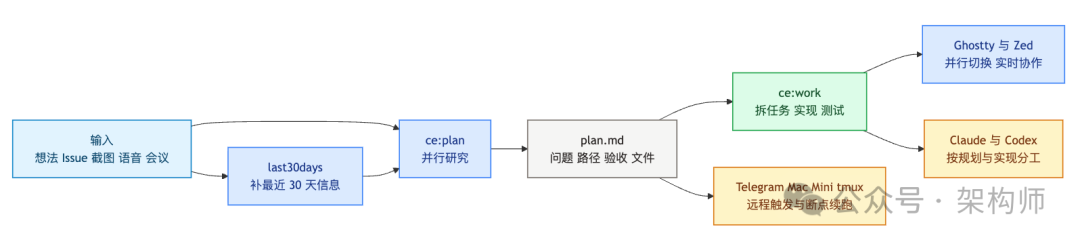
01|别急着写代码,先把任务入口扩出来
Matt 在原文里反复强调一个动作:一有想法,先 /ce:plan。
这句话表面上是在讲命令,实际上是在讲任务入口。以前一个任务的入口通常只有两种,要么先由人自己想清楚再开工,要么别人把 issue 写清楚再接手。Matt 把入口放宽了很多。
GitHub issue 可以直接 plan。终端报错可以截图后 plan。设计稿、Slack 对话、bug 现场、产品想法,甚至一段说得磕磕绊绊的口述,都可以先进入 planning 流程。
这个动作看起来简单,真正值钱的地方在于:我们不必等“信息足够规整了”才开始。可以先把高噪声信息喂进去,让系统替我们做第一轮结构化整理。
我们在团队里也有类似的体感。很多任务推进慢,不是因为没人会写代码,而是因为输入阶段太依赖人的临场表达。能把截图、聊天、会议、零散想法都变成任务入口,本身就在省时间。
02|把 plan.md 从备忘录,升级成任务中枢
Matt 这套工作流里,plan.md 不是随手写两句的待办,而是研究结果、实施路径、验收条件和上下文检查点的集合。
他描述的 /ce:plan 不只是“请帮我想一下方案”。它会并行拉起多个 research agent,一边读代码库,一边查内部文档、历史 bug、既有约定,必要时再补外部资料,然后把结果落成一份结构化计划。
一份能用的 plan.md,至少会回答四件事:
- 这次到底在解决什么问题。
- 为什么选这条方案,而不是别的方案。
- 需要改哪些文件,要沿用哪些既有模式。
- 什么算完成,怎么验证。
这就是为什么 Matt 会说,除非真的是一行修改,否则一定先有 plan.md。因为在 AI 参与开发之后,真正稀缺的不是“写出代码”,而是“把任务边界和上下文说准”。只要这一步没做好,后面再强的模型也很容易跑偏。
不过我们的体会是,plan.md 很重要,但它还不够。只有 plan,没有验收,最后很容易变成一份更漂亮的待办清单。
我们在《AI编程实践:从 Claude Code 到团队协作的 6 个落地抓手》里也聊过类似的事:先写“怎么证明它是对的”,再写“怎么实现”。Matt 这套 Planning-First 给出了很强的任务中枢,但真要落到团队协作日常里,最好再补上验收命令、风险边界和回滚方式。不然 plan 虽然存在,交付还是会漂。
这和我们前两天聊《Codex 为什么能又快又稳》时看到的逻辑是一条线。那篇讲仓库级上下文,里面有一句话我印象很深:Agent 看不见的东西,就等于不存在。 Matt 这里做的,其实是把这句话落到了任务层。仓库里的经验要写进系统,单次任务里的意图、约束、验收,也要写进 plan.md。
原文里还有一个特别实用、但很容易在转述里被写没的细节:/ce:plan 不是终点,/ce:work 才是它的配套动作。
Matt 的说法很直接。/ce:plan 负责把问题、路径、验收条件和代码库约束写进 plan.md;/ce:work 再接过这份计划,把任务拆开、逐个实现、运行测试、勾掉检查项。上下文中途丢了也没关系,重新开一个会话,指向这份 plan.md,还能接着干。
这也是为什么我们更愿意把 plan.md 理解成“检查点”,而不只是“计划书”。真正能扛住多会话切换、多模型切换、甚至隔天继续做的,不是聊天记录,而是这个结构化中间层。
03|让 plan 先吃到“最新世界”,而不是过期知识
原文里更有现实价值的一个动作,其实不是 /ce:work,而是 /last30days。
Matt 在做技术选型前,不先翻官方文档,而是先抓最近 30 天社区怎么讨论。他举的例子是比较 Vercel agent-browser 和 Playwright。几分钟内,他拿到了 78 个 Reddit 讨论、76 条 X 帖子、22 个 YouTube 视频、15 个 Hacker News 话题。然后再把这些内容交给 planning 系统消化。实际上 last30days 现在已经内置了比较模式,当输入 X vs Y 格式时,它会自动跑 3 轮并行研究,分别研究 X、Y、以及 X vs Y,最后输出一张包含优势、劣势和正面对决的对照表。Matt 那次选型,大概率就是这么跑的。
这个顺序很值得抄。
官方文档告诉我们“设计目标是什么”,最近 30 天的社区讨论告诉我们“今天谁在踩坑、坑有多大、代价是谁在付”。前者是产品自述,后者更接近真实运行状态。
所以 Matt 的方法并不是“相信模型比文档懂得多”,恰恰相反。他是在先补最新信息,再让模型做整合。对那些更新很快的框架、工具、Agent 产品,这一步往往比多问几轮提示词更重要。
这次我们顺手把 last30days-skill 仓库也翻了一遍,反而更能理解 Matt 为什么会把它放在工作流前面。
现在这个仓库已经不是一个“顺手搜一下最近讨论”的轻插件了。README 显示当前版本是 v2.9.5,默认覆盖 Reddit、X、Bluesky、Truth Social、YouTube、TikTok、Instagram、Hacker News、Polymarket 和 Web,比较模式会对 X vs Y 跑 3 轮并行研究,Open 变体还支持 watchlist、briefing、history 和外部调度。
更关键的是,它内部已经很像一个小型研究引擎,而不是一段提示词。主入口是 scripts/last30days.py,里面用 ThreadPoolExecutor 并发调不同来源;scripts/lib/ 下按职责拆了 30 多个模块——openai_reddit.py 通过 OpenAI Responses API 做 Reddit 定向搜索,bird_x.py 和 xai_x.py 分别走免费 GraphQL 和付费 xAI 两条 X 搜索链路,reddit_enrich.py 再回 Reddit JSON API 补真实互动数据(点赞、评论数、热门回复),score.py 做多信号加权评分(文本相似度、互动速度、来源权威度、跨平台收敛检测),dedupe.py 做近重复去除,polymarket.py 和 hackernews.py 各自对接免费公开 API。docs/how-search-works.md 直接把 Reddit、X 两条主链路的抓取、归一化、评分、去重画成了架构图;仓库里还有一整套 tests/,README 里写的是 455+ 测试。
搜索本身还分两个阶段。Phase 1 做广泛发现,把所有来源的结果拉回来;Phase 2 做智能补充——从 Phase 1 的结果里提取实体(比如 X 上的 @handle、Reddit 的子版块名称),再针对性地跑第二轮定向搜索,然后合并去重。--quick 跳过 Phase 2 换速度,--deep 则把每个来源的请求量翻倍。这和一般的“帮我搜一下”完全不是一个量级。
翻完仓库源码,我把这个流程画了出来:
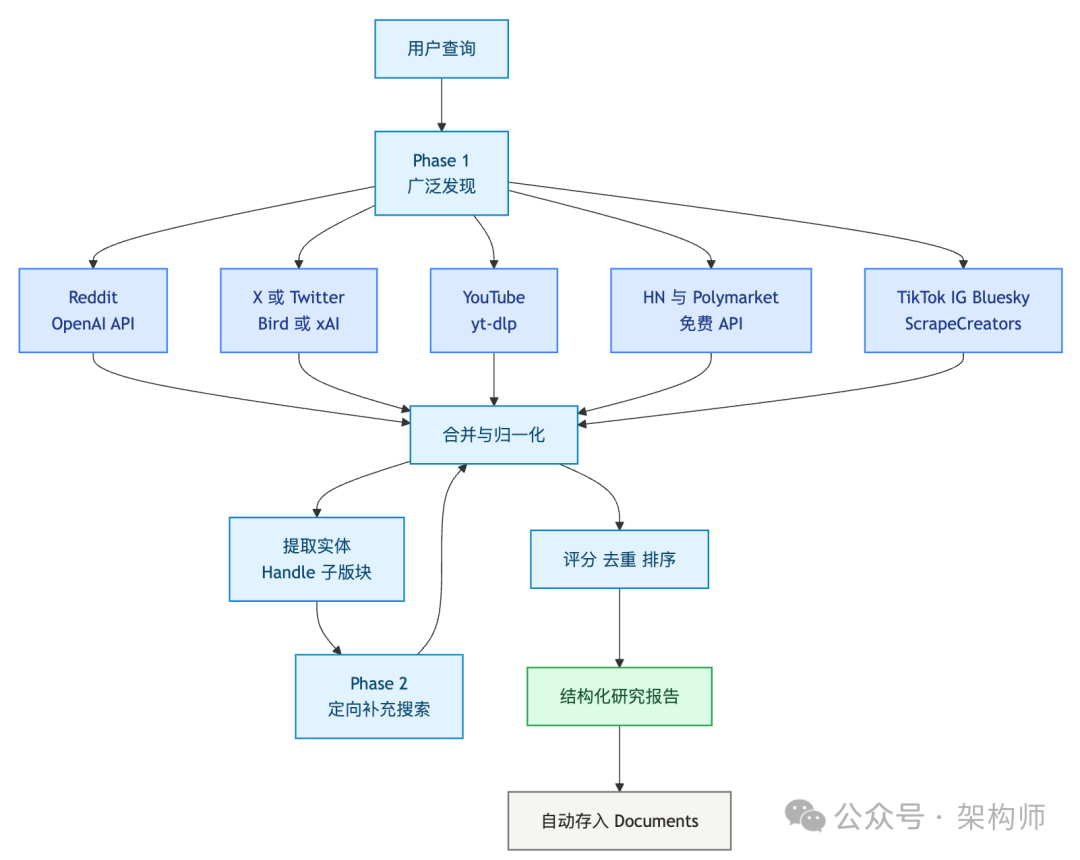
另外还有一个小细节值得提:从 v2.9.1 开始,每次研究结果会自动保存为 ~/Documents/Last30Days/ 下的 .md 文件,按话题命名。跑得越多,你的本地研究库就越厚。这也解释了 Matt 为什么能在 /ce:plan 的时候随时引用过去的调研——它们本来就躺在文件系统里,Claude Code 直接就能读到。
也就是说,Matt 前文里那句“先 /last30days,再 /ce:plan”,并不是一个随手加的习惯。它背后其实已经站着一套独立的、经过工程化打磨的研究流水线。
这和我们之前在《Skills 详解》里讲过的路线也能接上。真正能长期复用的方法,不是把一大段 prompt 记在脑子里,而是把查询、评分、过滤、引用、输出这些动作拆成稳定结构。last30days 现在越来越像这种结构化研究件,而不只是“一个很会搜的技能”。
04|语音不是花活,它是在提高输入带宽
Monologue、WhisperFlow 这一层,很多人第一次看会觉得太重度用户了。开车时口述、走路时口述、坐在车里改文章,像是在展示一种很新的工作方式。
但更值得注意的,不是输入形式,而是输入带宽。
LLM 出现前,语音输入经常让人烦躁,因为识别错了就是错了。现在不一样,模型可以用上下文去补齐说乱了、说断了、说错了的部分。我们不需要每一句都像在念稿,只要把意图倒出来,系统就能先把它整理成结构。
这会直接改变任务发起的成本。以前脑子里有个半成品想法,得先自己整理成熟了才值得写下来。现在可以先说,先贴图,先把模糊的想法甩进系统,让它先把骨架搭出来。
这背后不是“语音取代键盘”,而是输入阶段从低带宽变成高带宽。
05|并行开 4 到 6 个窗口,核心不是多开,而是状态拆分
Matt 现在的日常,是 4 到 6 个 Ghostty 会话同时跑。一个在写计划,一个在执行旧计划,一个在跑 /last30days 调研,一个在修测试里发现的新 bug。
如果只学到“同时开很多窗口”,这套方法很快就会沦为更贵的分心。
它之所以成立,是因为每个窗口干的不是同一种事。调研、计划、执行、验证,已经被拆成了不同状态。一个窗口在等 research agent 返回结果,另一个窗口就去执行已经成熟的计划;执行窗口跑测试时,第三个窗口可以先接新的输入。
换句话说,他不是把“写代码”并行化,而是把整个任务流水线摊平了。
这一点很像成熟团队看流水线的方式。真正提高吞吐量的,不是每个环节都更快,而是让等待时间不再空转。
这里还有一个很容易误读的点。很多人看到“4 到 6 个窗口并行”,第一反应是这得多烧 token。确实会烧,但问题不只在窗口数量。
我们在《OpenClaw 为什么越聊越贵:4 个 Token 黑洞 + 6 个止血指令》里拆过一次,真正让 Agent 成本和稳定性一起失控的,往往不是问题本身有多复杂,而是它一直背着一车历史、工具输出和失败轨迹在跑。
从这个角度看,Matt 的多窗口工作法并不只是“更猛”,它其实也在主动切断上下文雪球。每个窗口都对应一个相对单一的话题容器或阶段状态,计划是一个窗口,执行是一个窗口,新 bug 是另一个窗口。和把所有事揉进一个长会话相比,这种切法反而更接近可控。
06|三个小配置,撑起了“像协作一样工作”的体验
原文里提到的三个设置,其实构成了一整套协作感基础设施。
第一是 bypassPermissions。如果每个会话每一步都要停下来确认,根本没法并行切换。
第二是完成提示音。窗口一多,人脑根本记不住谁刚跑完,声音是最便宜的状态通知。
第三是 Zed 的 500ms 自动保存。Claude Code 监听文件变化,终端里的修改会立刻反映到编辑器里;编辑器里的改动,也会很快被会话看到。Ghostty 和 Zed 并排时,确实会有一种像 Google Docs 协作的感觉。
不过有一个边界值得多说两句。bypassPermissions 之所以危险,不是名字夸张,而是它真的把默认保护拆掉了。Matt 这套方法之所以能跑起来,背后默认有代码库纪律、测试、GitHub 回滚能力,以及对试错成本的承受能力。
如果一个团队没有这些基本盘,只学会“把权限全部放开”,那得到的往往不是高效,而是更快地把问题写进主干。
我们会分两层看。对 Matt 这种高频单兵工作流,bypassPermissions 是为了保持吞吐量。对团队落地,我们还是更认同那篇“6 个落地抓手”里讲的做法:把高频安全命令写进 allowlist,把确认弹窗留给真正危险的操作。不是完全不放,而是按风险分层放。
07|把会议、远程触发和非代码任务都拉进同一条 planning 链路
本文后半段最值得注意的,不是又多了一个技巧,而是它已经明显溢出到代码之外了。
Matt 举了几个很具体的例子。
他把一场 90 分钟的午餐谈话录进 Granola,谈话里既有产品脑暴,也有餐厅和孩子这些闲聊。录音整理后直接交给 Claude Code,要求把它变成产品 proposal。最后产出的不是摘要,而是一份可以发给候选人的完整提案。后来那位候选人真的全职加入了团队。
他也用同一套方法写战略文档。对着 Monologue 说出三种 go-to-market 路线、优缺点、语言风格调整、风险补充,Claude Code 一边读当前产品上下文,一边参考之前的战略 plan.md,把新文档持续往前推。
甚至在足球场边,他还能把 Disney World 的聊天需求,先用 /last30days 查近况,再生出一份结构化行程计划,接着部署成网页,最后把关键提醒接进 Telegram 和自动化系统。
原文里还有一条我很喜欢的链路,是把执行从“人坐在电脑前”这件事里解放出来。
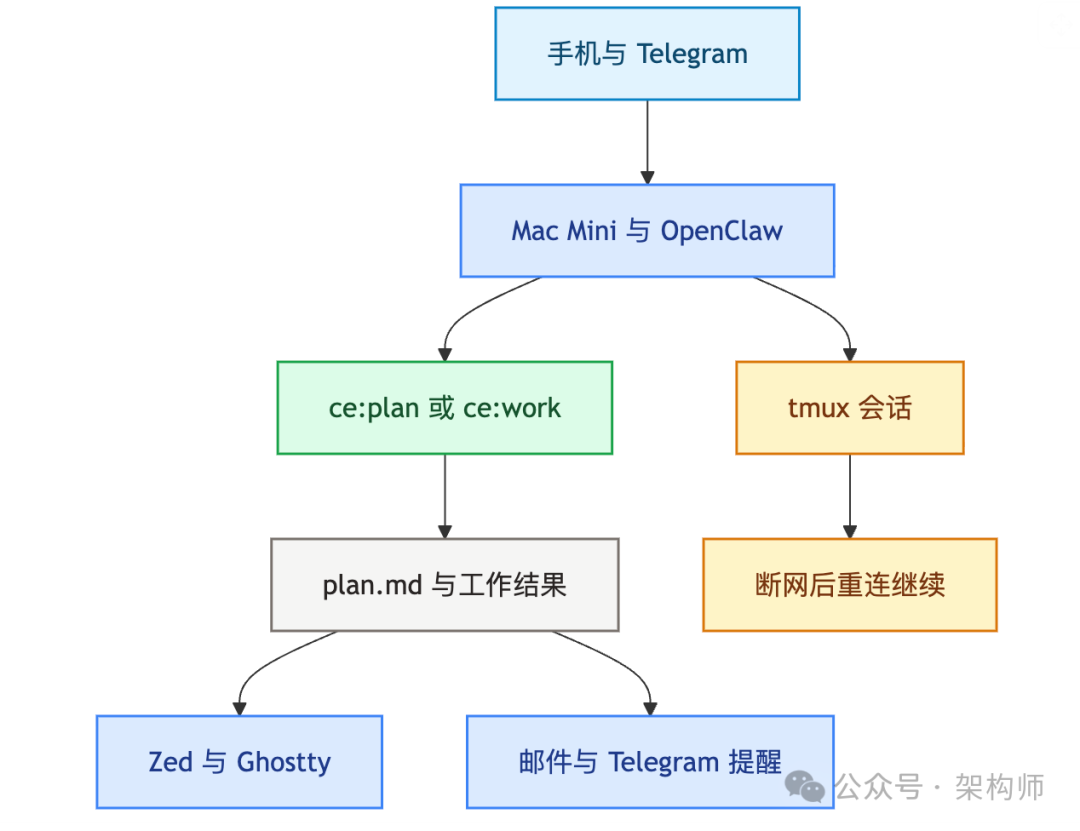
Matt 有一台专门跑 OpenClaw 的 Mac Mini。他会直接从手机 Telegram 给这台机器发消息,比如吃饭时想到一个 bug,就发一句 /ce:plan fix the timeout issue。等他回到屏幕前,计划已经写好,甚至还能通过 AgentMail 发回给他。
飞机上网络不稳时,他也不会把会话跑在笔记本本地,而是先 tmux 到 Mac Mini 上,让会话真正跑在远端机器。这样就算中途断网,回来重连,任务还在原地继续。
把这条链路画出来,大概是这样:
这时候回头看 last30days 的仓库也很有意思。它其实已经在往“持续研究基础设施”走了,而不是只服务一次性查询。除了普通模式,仓库里还有 variants/open/、scripts/watchlist.py、scripts/briefing.py、scripts/store.py 这套 open 变体,专门为 OpenClaw 这类 always-on bot 设计。可以把竞品、特定人物、任何感兴趣的话题加进 watchlist,设好频率(每周、每月),由外部调度器定时触发 watchlist.py run-all,研究结果持续写入本地 SQLite 数据库,随时可以用自然语言查询历史发现、生成摘要简报。换句话说,它的目标已经不只是“帮你搜一次”,而是“把近期外部世界的变化,持续积累成一个可查询的研究层”。
这些例子真正说明的,是 plan.md 正在从“代码任务的中间层”变成“知识工作的中间层”。产品方案、战略文件、竞品分析、旅行规划、提醒编排,本质上都在复用同一种模式:
- 先吸收杂乱输入。
- 再整理成结构化计划。
- 再交给不同执行器去落地。
从架构视角看,这已经不是一个编码技巧,而是一套通用任务编排方式。
这也和我们年初在《我真不敢相信,AI 先加速的是工程师》里的判断是连起来的。那篇文章里我们写过,AI 先加速的不是简单重复劳动,而是知识工作里最可结构化、最可验证的那一层。Matt 这篇原文几乎就是这个判断的日常化版本。
代码、产品提案、战略文档、旅行规划,看起来跨度很大,但它们共同满足一件事:都可以先被整理成一个结构化中间层,再交给不同执行器继续推进。真正被 AI 放大的,不是某一个软件,而是这种“把模糊问题整理成可执行结构”的能力。
再压缩一点说,Matt 真正做的,不是把 Claude Code 用成“更强的 IDE”,而是把它推成了一个执行中枢。屏幕前可以做,路上可以做,会议里可以做,甚至断网场景下也能续上。
08|Claude 做规划,Codex 做重活,这才是成本和能力的重新分工
原文还有一个很现实的细节,经常会被忽略。
这套工作流很烧额度。4 到 6 个并行 Opus 会话全天运行,很快就会把 Claude Max 的月度预算吃完。所以 Matt 后面又接了一层 --codex,让 Compound Engineering 在 Claude 额度吃紧时,把实现工作切给 Codex。
这个动作值钱,不只是因为省钱。
它透露出一个更成熟的判断:不同模型不一定要竞争“谁全都做”,也可以在工作流里分工。Claude 更适合长链路规划、上下文组织、任务编排;Codex 更适合重型实现、批量执行、代码产出。让不同模型在一个 planning 中枢后面协同,比争论“谁更强”更接近真实生产环境。
这也是为什么更值得把 Matt 这篇原文理解成一篇架构文章,而不只是工具文章。规划层、研究层、执行层、远程触发层、通知层、成本层,都开始被拆出来了。
如果把这点和《Codex 为什么能又快又稳》放在一起看,会更清楚。Codex 那篇讲的是团队如何把经验沉到仓库和流程里;Matt 这篇讲的是个人如何把经验沉到任务和计划里。一个是仓库级“开发操作系统”,一个是任务级“执行中枢”,本质上都在回答同一个问题:怎么让高频迭代不靠临场发挥。
原文最后还有一个小细节,很能说明这套工作流为什么会越来越顺手。Matt 说,本文本身也是这样写出来的。Markdown 文件开在 Zed 里,Claude Code 跑在 Ghostty 里,他一边口述“开头不对,重写”“把 Granola 的故事加上”“别把 Zed 叫我的 IDE”,一边看文件实时变化,前后一共改了七版。
这个细节也说明,这套方法不是“只适合写代码”,也不是“只适合特别大的项目”。它已经开始反过来塑造作者自己的写作、思考和迭代方式。
看完之后,我们留下的 3 条
如果把上面这些压一压,我们真正留下的只有 3 条。
第一,除非任务极小,否则先产出 plan.md,再进入实现。
第二,把最新外部信息和内部上下文一起喂给 planning,而不是只让模型凭记忆回答。
第三,把调研、计划、执行、验证看成不同状态,而不是一股脑塞进一个会话里。
这三条一旦成立,不一定非要完整复制 Matt 的工具栈。可以不用 Ghostty,不一定非得上 Zed,也不需要第一天就跑 6 个窗口。哪怕只是让团队里那些总要反复解释的任务,先沉淀成一份像样的 plan.md,收益也会很明显。
所以,我们看完之后最强烈的感受,不是“Claude Code 原来还能这么玩”,而是另一个更底层的判断被再次坐实了:
AI 时代真正的高杠杆,正在从“谁写代码更快”转向“谁更会组织任务、上下文和执行顺序”。
回头看我们今年写的几篇,这个方向其实越来越清楚了:
- 《年初那篇》讲的是,工程师的价值正在从“产出层”迁到“责任层”。
- 2 月那篇讲的是,《Claude Code 要想真正进团队》,得把对话变成协作协议。
- 《前两天那篇讲的是》,Agent 能不能跑稳,取决于经验有没有提前写进仓库。
- 而 Matt 这篇原文补上的,是任务这一层:经验不只要写进仓库,也要写进 plan。
工具会继续变,模型也会继续变。但 Planning-First 这件事,大概率会留下来。
原文链接: https://x.com/mvanhorn/status/2035857346602340637
last30days-skill: https://github.com/mvanhorn/last30days-skill
Matt Van Horn 的实践提供了一个非常具体的观察窗口:当把 plan.md 置于工作流核心,并辅以工程化的研究工具(如 last30days)和状态拆分策略后,AI 编程的效率和可控性可以跃升到一个新的层次。这不仅是个人的效率技巧,更是对未来团队AI编程协作模式的一种预演。你对此有何看法?欢迎在 云栈社区 分享你的实践或想法。
 发表于 2026-3-28 04:03:16
|
查看: 122|
回复: 0
发表于 2026-3-28 04:03:16
|
查看: 122|
回复: 0
