

即便你对生成式AI模型的内部原理了解不深,也大概率听说过它们对内存的“贪婪”消耗。内存开销已成为AI推理规模化部署的主要瓶颈之一。
最近,谷歌研究院宣布了一项名为TurboQuant的新型压缩算法。它宣称能够在保证模型输出精度不损失的前提下,将大语言模型推理时的关键工作内存——键值缓存(KV cache)压缩至少6倍。如果实现产业化落地,这项技术有望在英伟达H100等硬件上带来最高8倍的推理速度提升,从而显著降低AI模型的运营成本。
一些业界观察家,包括Cloudflare的CEO Matthew Prince,将此称为谷歌的“DeepSeek时刻”。此前,中国的DeepSeek模型因其以极低训练成本实现高性能而震惊业界。现在,谷歌似乎在推理效率的优化上,投下了一颗重磅炸弹。
TurboQuant最令人兴奋的承诺在于:精度零损失。它不需要对模型进行额外的微调,也无需使用特定训练数据,就可以直接应用于现有的Transformer架构模型,大幅压缩其KV缓存,同时确保输出结果与全精度版本完全一致。倘若这一效果能在真实的生产环境中得到验证,几乎可以在一夜之间改写长文本、长上下文的推理成本格局。
市场的反应迅疾而直接。在该技术发布后数小时内,主要内存制造商的股价应声下跌:美光科技跌3%,西部数据跌4.7%,闪迪跌5.7%。投资者的逻辑很清晰:如果AI模型所需的内存能被如此高效地压缩,那么整个行业未来的物理内存需求可能需要被重新评估。
极致无损压缩,革新向量检索
在官方博文中,谷歌研究院将TurboQuant描述为一种在不牺牲性能的前提下,大幅削减AI运行时内存的全新方法。其核心是采用一种创新的矢量量化方案,旨在解决AI处理中的缓存瓶颈。简单来说,它能让AI在记住更多信息的同时,占用更少的空间,且不损失“记忆力”。
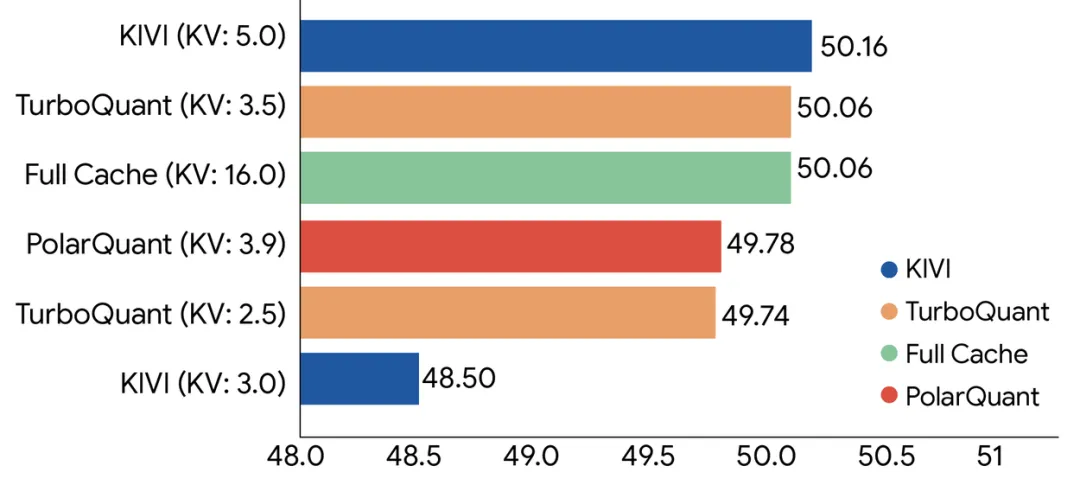
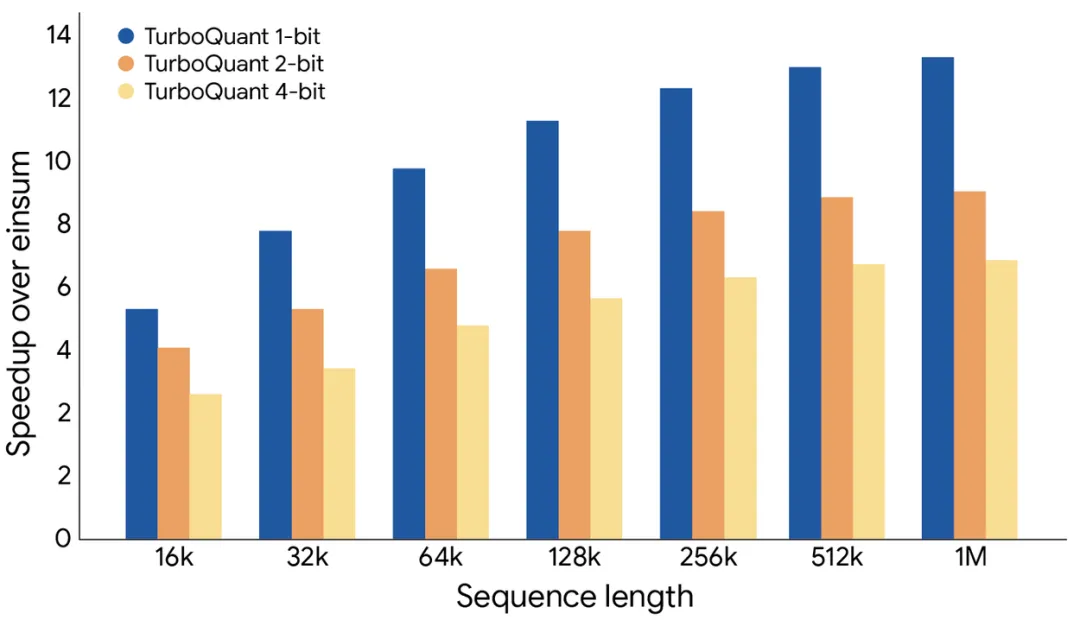
KV缓存就像是模型的“数字草稿纸”,用于存储计算过程中生成的关键中间结果,以避免对相同内容进行重复计算。这块“草稿纸”不可或缺,但也往往是内存消耗的大户。为了让模型更“轻快”,开发者常使用量化技术,但传统量化往往以牺牲输出质量为代价。而谷歌的早期测试数据显示,TurboQuant在部分场景下能实现性能提升8倍、内存占用减少6倍,且精度毫无损失。
谷歌表示,他们在Gemma和Mistral等开源模型上,使用一系列长上下文基准测试了这套新算法。结果表明,TurboQuant在所有下游任务中均保持了完美的性能表现,同时将KV缓存的内存占用降低了6倍。该算法无需额外训练,就能将缓存量化至仅3比特,并可直接应用于现有模型。在英伟达H100上,使用4比特TurboQuant计算注意力分数,速度比未量化的32比特KV缓存快8倍。
需要明确的是,TurboQuant目前仍是实验室阶段的突破,尚未大规模部署。但它指明了未来的可能性:一是直接降低现有模型的运行成本和内存消耗;二是利用节省出的内存资源,运行更复杂、能力更强的模型。这两种方向很可能并行发展。其中,移动端AI可能是最直接的受益者,这类压缩技术能在不将数据上传云端的前提下,显著提升设备端AI的生成质量和效率。
除了大语言模型推理,TurboQuant同样适用于向量检索场景。在RAG和相似度搜索中,高维向量同样面临巨大的内存压力。使用TurboQuant后,索引构建时间几乎可以忽略不计(例如,处理1536维向量仅需0.0013秒,而传统的乘积量化方法需要239.75秒),同时在GloVe数据集上的召回率也优于主流基准方法。
技术核心:PolarQuant压缩与QJL纠错
将TurboQuant应用到AI模型主要分为两个阶段,对应两项核心技术:量化方法PolarQuant,以及训练与优化方法QJL。
为了实现高质量的压缩,谷歌设计了名为PolarQuant的系统,它采用了一种完全不同的思路来解决内存开销问题。传统上,模型中的向量采用类似XYZ笛卡尔坐标的标准编码。而PolarQuant则将向量转换为极坐标表示。在这个环形网格中,一个向量被简化为两项信息:半径(表示数据的核心强度)和方向(表示数据的语义含义)。谷歌用一个生动的比喻来解释:传统编码好比“向东走3个街区,再向北走4个街区”,而极坐标表示则可以简化为“沿37度方向走5个街区”。这不仅占用空间更少,还省去了计算开销高昂的数据归一化步骤。PolarQuant承担了主要的压缩职责,但会引入少量残留误差。
第二个步骤则专门用于修复这些瑕疵。为此,谷歌提出了量化约翰逊-林登斯特劳斯变换(QJL)来进行平滑处理。该技术能在压缩复杂高维数据的同时,保留数据点之间关键的距离与关联信息。它相当于为模型添加了一层1比特的误差校正层,将每个向量压缩至单个比特(+1或-1),本质上构建了一套高速“简写”系统,且内存开销近乎为零。为保证最终精度,QJL采用了一种特殊的估算器,在高精度查询与低精度简化数据之间进行巧妙平衡,使模型能够精确计算注意力分数——这是神经网络判断信息重要性的核心机制。
二者结合的效果是:PolarQuant实现极致的初步压缩,QJL则以近乎零成本进行误差修正。谷歌计划在下个月的ICLR 2026会议上正式展示这项研究成果的细节。
开发者社群先行复现,挑战与机遇并存
尽管谷歌尚未发布任何官方代码或集成库,全球的独立开发者社群已经仅凭论文开始了热火朝天的复现工作。
有开发者在PyTorch中利用Triton自定义了内核,并在RTX 4090显卡上对Gemma 3 4B模型进行了测试。结果显示,在2比特精度下,量化后模型的输出与未压缩的基准版本实现了逐字符完全一致。这初步验证了TurboQuant的理论保证在较小规模模型上的有效性。
另有开发者通过MLX框架在苹果芯片上运行了搭载TurboQuant的35B参数模型,并在各量化等级的“大海捞针”测试中取得了满分成绩。在llama.cpp社区,也有多名开发者正在开发C语言和CUDA版本,其中一位表示已通过全部18项测试,压缩比与论文数据完全吻合。
一项研究论文在官方发布前就能以如此速度被广泛复现,实属罕见。覆盖Triton、MLX、llama.cpp等多个技术栈的实现尝试,既体现了TurboQuant数学设计的清晰性,也充分反映出KV缓存优化已成为AI部署中最迫切的瓶颈之一。
然而,复现之路并非坦途。一位早期开发者指出,QJL误差校正模块的实现颇具挑战,简单的实现只会导致输出乱码。如果不能正确实现QJL对向量内积估算的偏差校正,量化误差会在推理过程中不断累积,最终导致输出结果完全不可用。目前,谷歌仍未发布TurboQuant的官方代码,主流的推理框架如vLLM、llama.cpp、Ollama等也尚未集成该技术。
市场波动与技术竞赛:效率革新进行时
资本市场的反应迅速且剧烈。内存类股票普遍下跌,A股市场的存储芯片板块也集体下挫。在一些分析师看来,这种波动或许反应过度。富国银行分析师Andrew Rocha指出,TurboQuant确实直接冲击了AI系统的内存成本曲线。如果该技术被广泛采用,整个行业需要重新评估未来所需的内存容量。但他和其他分析师也提醒,AI对内存的整体需求依然强劲,且压缩算法已存在多年,并未从根本上改变硬件采购的宏观规模。
不过,市场的担忧也并非空穴来风。当前AI基础设施支出正以惊人速度增长。一项能将内存需求降低6倍的技术,虽然不会让总支出同步减少6倍(因为内存只是数据中心成本的一部分),但它会显著改变成本结构。在数千亿美元级别的投入中,即便是小幅的效率提升,其带来的绝对价值也将是巨大的。
值得注意的是,TurboQuant并非KV缓存压缩领域的唯一玩家。据了解,英伟达也将在ICLR 2026上展示其KVTC算法,宣称可实现高达20倍的压缩率,且精度损失不到1%。KVTC采用了与TurboQuant不同的技术路径,例如基于主成分分析的去相关方法和熵编码。与TurboQuant“与数据无关”的设计不同,KVTC需要针对每个模型执行一次性的离线校准步骤。作为回报,它在处理长提示词时,能将首token延迟最高降低8倍。
两种相互竞争的压缩标准即将同期亮相,标志着KV缓存优化正从一个纯学术研究课题,迅速成熟为影响实际生产环境的关键基础设施层。对于广大开发者和企业而言,这意味着更高效的AI应用即将成为可能。欲了解更多前沿AI技术和工程实践,欢迎访问云栈社区,与全球开发者一同探索技术的边界。
参考链接:
 发表于 2026-3-29 03:53:40
|
查看: 118|
回复: 0
发表于 2026-3-29 03:53:40
|
查看: 118|
回复: 0
