今天想和大家分享一次深刻的量化策略认知转变。
我曾经对自己的遗传算法(比如 NSGA-II)工程实现颇为自豪。我的代码包括了 Walk-forward 滚动回测、Numba 底层加速、多进程并发以及多轮随机种子寻优,在工程层面上可以说是做到了极致,跑出来的历史回撤和收益率曲线堪称完美。然而,当我真正以专业量化的视角去审视这套基于纯价格动量的遗传算法策略时,我猛然意识到:在金融量化这个充满极高噪音的非稳态系统里,我曾引以为傲的复杂启发式算法,其实是一种极其危险的“花拳绣腿”。
量化交易的本质不是对历史数据做精雕细琢,而是对未来不确定性进行严密的控制和应对。以下是我总结的五个优化方向,它们清晰地揭示了为何要从遗传算法全面转向凸优化,这也是我认知转变的底层逻辑。
一、 算法引擎:从“盲目寻优”到“严密求解”
以前我习惯用遗传算法来拟合过去 36 个月的最大回撤。GA 太“聪明”了,它会通过极其精妙的权重微调,完美地“预判”并避开过去三年里的每一个大跌日。但这实际上是一种“背书”行为,而非真正的“预测”。
拥抱凸优化与正则化
标准的资产配置问题,在数学上往往存在全局唯一的最优解。与其用计算成本高昂且带有随机性的 GA 在非凸空间里盲猜,不如回归到经典的马科维茨均值-方差框架,并引入正则化惩罚项。
在凸优化框架下,目标函数可以表达为:
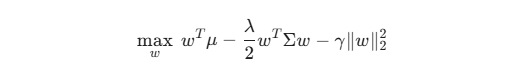
这里的 w 是资产权重向量, μ 是预期收益率, Σ 是协方差矩阵, λ 是风险厌恶系数。
最关键的是尾部的 L2 正则化项,它能强制惩罚过大的极端权重,迫使模型选择更分散、更平滑的资产配置。GA 给出的往往是为了避开某次大跌而产生的畸形权重,而凸优化加上正则化,给出的则是一个具备统计学鲁棒性的全局最优解。
二、 数据源头:打破纯价格的“信息茧房”
过去我只是把 ETF 过去 36 个月的收益率矩阵喂给模型,本质上是在做隐式的动量或均值回归。当面对宏观突变,比如流动性危机或加息周期时,这种固定窗口的价格回溯反应会极其迟钝。
引入多因子驱动与状态切换
市场的运行规律并非单一的价格寻优。资产的预期收益不应只是过去表现的线性外推,而应该是一个多因子叠加的系统:
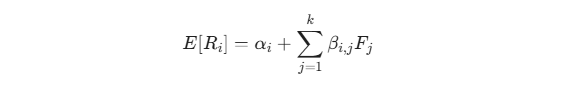
我们需要引入外生的宏观变量 F_j ,例如美债 10年期与 2年期利差、VIX 恐慌指数、信用利差等。
此外,36 个月的固定窗口过于死板。更专业的做法是引入隐马尔可夫模型来识别不同的市场状态。当模型依靠波动率和流动性指标侦测到系统切换至“高风险状态”时,策略应主动缩短计算协方差矩阵的半衰期,甚至硬性降低风险资产的上限,而不是被动等待遗传算法那慢半拍的信号。
三、 风险建模:从“事后砍仓”到“事前波动率控制”
我以前的脚本会设置一个硬性的 -15% 净值止损线。但这种账户级别的粗暴止损,在实盘中极易因市场反复震荡(Whipsaw 效应)而倒在黎明前的最低点。
目标波动率与协方差收缩
顶尖机构不会等亏损达到 15% 才采取行动,他们依靠的是事前风险控制。如果策略设定的目标年化波动率为 σ_target(例如 10%),那么在 t 时刻的实际仓位暴露 w_t 应该严格遵循:
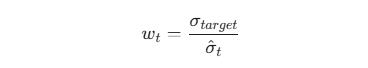
这里的 σ̂_t 是利用 EWMA 或 GARCH 模型对近期波动率的预测值。当市场恐慌导致预测波动率飙升时,系统会瞬间按比例自动降低仓位,将投资组合的整体风险牢牢钉死在目标值上。
同时,在计算资产间的协方差矩阵 Σ 时,直接使用样本协方差会引入巨大误差。必须引入 Ledoit-Wolf 收缩算法,将样本协方差向结构化矩阵收缩,这能增强投资组合应对未知的“相关性黑天鹅”事件的能力。
四、 交易执行:别让摩擦成本吃掉你的超额收益
以前的代码里写死了“权重变化超过 1% 就调仓”,手续费固定设置为 0.08%。这种做法在大资金实盘交易中几乎等同于儿戏。
非线性成本函数与不作为区间
最优的调仓逻辑,是一道复杂的边际平衡题:“不调仓带来的跟踪误差惩罚”与“调仓带来的确定性摩擦成本”,究竟哪一个更大?
在数学上,我们需要将交易摩擦作为 L1 惩罚项加入到目标函数中:
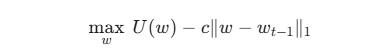
这里的 c 代表了包含买卖价差和市场冲击的综合交易成本。引入 L1 惩罚项后,凸优化求解器会自动形成一个“不作为区间”。只要目标理想权重落在当前权重附近的这个区间内,求解器就会输出“保持不动”的指令。这允许策略在市场波动较小时容忍一定程度的偏离,从而极大节省了无谓的交易磨损。
五、 鲁棒性验证:一条历史时间线证明不了什么
我曾沿着 2020 到 2023 年的历史顺序进行 Walk-Forward 回测,策略就通过了验证。但这可能仅仅是因为运气好,恰好踩中了特定时期的科技股牛市。
顶尖机构的视角:组合路径交叉验证
在量化领域,单向的历史验证是不及格的。历史只发生了一次,但未来有无数的可能性。
我们必须引入 CPCV(组合路径交叉验证)。如果将历史数据切分为 N 个时间块,每次抽取 k 个块作为测试集,我们能生成大量模拟的测试路径:
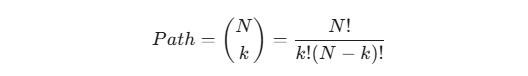
将历史收益率按周或月打乱并重新排列,在保留资产间相关性的前提下,生成成千上万条“平行世界”的收益率曲线。只有当策略在这些平行世界里的表现依然能跑出正期望,而不是仅在真实历史这条单一路径上赚钱,才有资格进入实盘阶段。
从遗传算法到凸优化,表面上像是从“前沿 AI”退回到了“传统数学统计”,但对我而言,这是从“纸上谈兵”迈向“工业级量化”的关键一步。量化交易的过程就是不断的自我怀疑和自我证明。
金融市场没有魔法,奥卡姆剃刀原理在这里依然适用:在具有同等解释力的前提下,数学根基越深,策略在未知样本外的存活概率就越高。放弃对复杂黑盒算法的盲目崇拜,转而敬畏风险、拥抱数学常识,这并非退步,而是在认清市场本质后的一种返璞归真。这也是我作为一个开发者,在量化之路上想要走得更远所必须建立的坚实认知。希望我的这次思考与转变,能为你带来一些启发。如果你想与更多同行交流类似的技术心得,欢迎来云栈社区一起探讨。
 发表于 2026-3-31 06:06:35
|
查看: 120|
回复: 0
发表于 2026-3-31 06:06:35
|
查看: 120|
回复: 0
