近期,一个国内开源项目凭借其高质量的代码、快速的迭代节奏以及简洁友好的操作体验,正在技术社区中迅速获得关注。短短半年时间,它已经在国内外收获了大量开发者和生产环境用户的青睐。这个项目就是 GPUStack。
GPUStack 是一个 100% 开源的大模型服务平台。用户只需简单配置,即可高效整合包括 NVIDIA、Apple Metal、华为昇腾和摩尔线程在内的各类异构 GPU/NPU 资源,构建统一的异构 GPU 集群,为企业提供本地化、私有的大语言模型部署方案。
GPUStack 全面支持构建私有化 RAG 系统和 AI Agent 系统所需的各种关键模型,例如 LLM(大语言模型)、VLM(多模态视觉语言模型)、Embedding(文本嵌入模型)、Rerank(重排序模型)、Text-to-Image(文生图模型),以及 STT(语音转文本)和 TTS(文本转语音)模型。更重要的是,它提供了统一的认证机制和高可用的负载均衡,所有模型都通过标准化的 OpenAI 兼容 API 对外服务,使得用户能够无缝地将现有应用从云服务迁移到本地部署的私有大模型服务上。
GitHub 仓库地址:https://github.com/gpustack/gpustack
GPUStack 核心介绍
GPUStack 是一个集集群化与自动化于一体的大模型部署解决方案。用户无需再手动管理多台 GPU 服务器或协调资源分配。GPUStack 内置了多种智能调度策略,如紧凑调度、分散调度、指定 Worker 标签调度、指定 GPU 调度等,能够自动将任务分配合适的 GPU 资源来运行模型。
对于参数量过大、无法在单张 GPU 上运行的模型,GPUStack 提供了分布式推理能力,可以自动将模型拆分并运行在跨主机的多个 GPU 上。同时,为了满足实验和兼容性需求,用户还可以选择 GPU 与 CPU 混合推理 或 纯 CPU 推理 模式,利用 CPU 算力来运行大模型。
主要特性详解
1. 多平台与异构 GPU 支持
GPUStack 支持 amd64 和 arm64 架构的 Linux、Windows 和 macOS 操作系统,能够纳管 NVIDIA、Apple Metal、华为昇腾和摩尔线程等多种类型的 GPU/NPU 硬件。
2. 多推理引擎与版本管理
GPUStack 支持 vLLM、llama-box(基于 llama.cpp 与 stable-diffusion.cpp)以及 vox-box 三大推理引擎,以适应不同场景下的部署需求。
- vLLM:面向生产环境的高性能推理引擎,专为高并发、高吞吐场景优化,但仅支持 Linux 系统。
- llama-box:由 GPUStack 推出的灵活推理引擎,基于 llama.cpp 与 stable-diffusion.cpp。它兼容 Linux、Windows 和 macOS,支持在 NVIDIA、Apple Metal、华为昇腾、摩尔线程等多种 GPU/NPU 以及纯 CPU 环境下运行模型,是资源有限的 AI PC 和边缘计算场景的理想选择。
- vox-box:专注于语音模型的推理引擎,支持 TTS 和 STT 模型,并提供 OpenAI 兼容 API。它集成了 Whisper、FunASR、Bark 和 CosyVoice 等后端。
此外,GPUStack 提供了推理引擎版本管理功能。用户可以为每个部署的模型固定任意的可用引擎版本,运维人员可以同时使用多个版本来满足新旧模型的兼容性需求,在引入新模型的同时保证旧服务的稳定运行。
3. 全栈模型类型支持
GPUStack 支持 LLM、VLM、Embedding、Rerank、文生图、STT、TTS 等各类模型。用户可以从 Hugging Face、ModelScope、Ollama Library、私有模型仓库或本地路径部署这些模型。
- 大语言模型 (LLM)
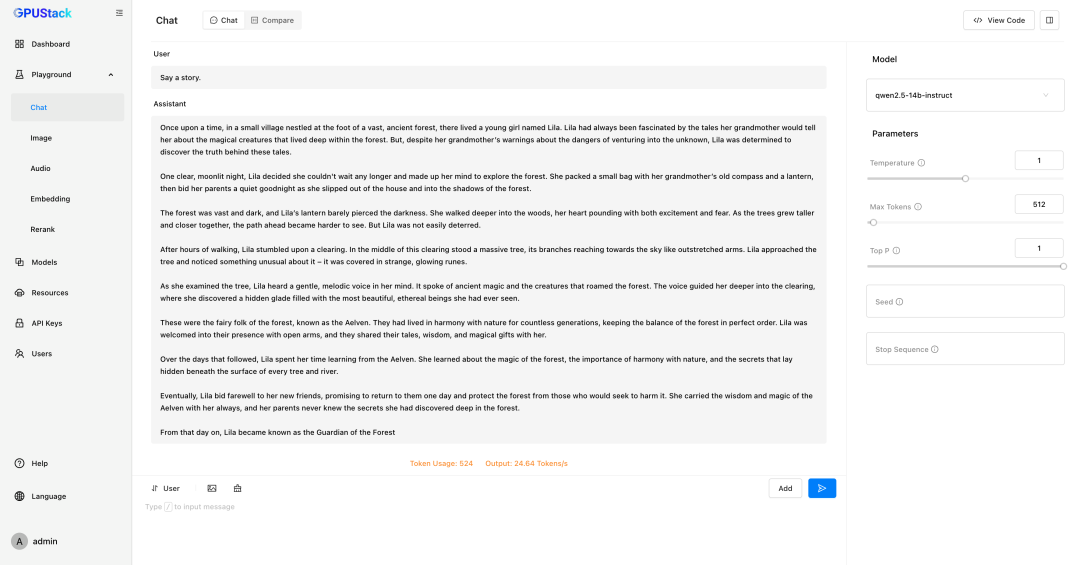
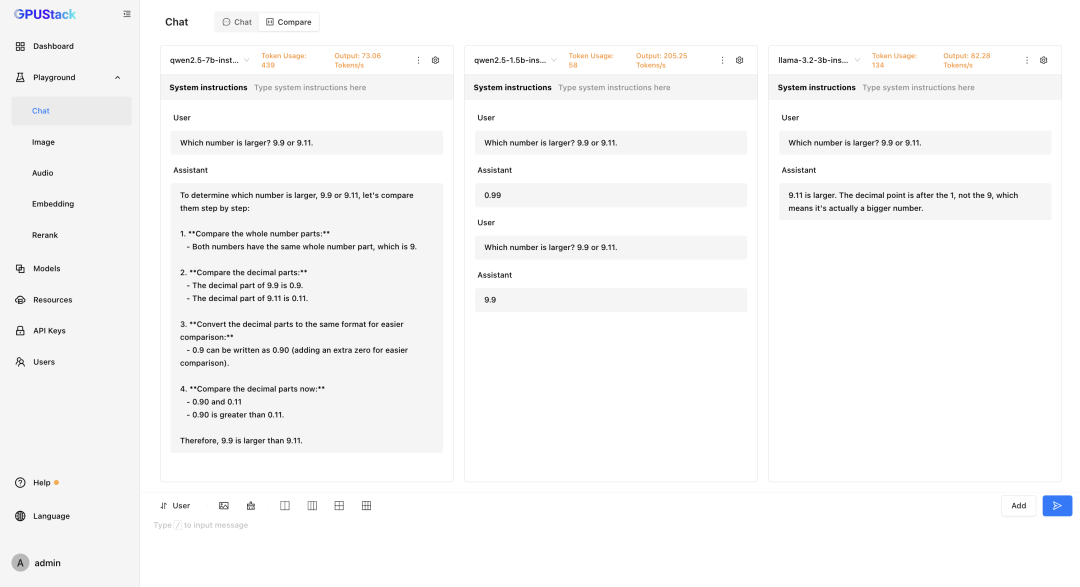
GPUStack 支持在各类 GPU/NPU 上运行 LLM。通过 vLLM 和 llama-box 后端,它能全面覆盖从研发测试到生产应用,从数据中心到桌面边缘的各种环境。其 Playground 不仅提供了模型调测功能,还支持多模型对比视图,方便用户同时对比多个模型在问答内容、性能数据等方面的表现。
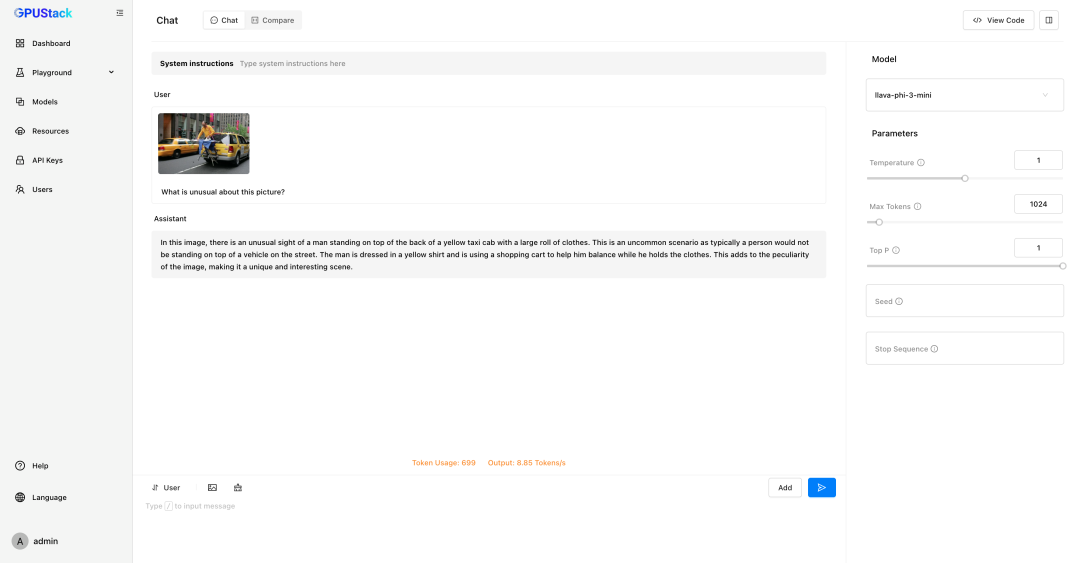
- 多模态模型 (VLM)
GPUStack 可以部署 Llama3.2-Vision、Pixtral、Qwen2-VL、LLaVA、InternVL2 等多模态模型,用于图像识别等任务,用户可在 Playground 中验证模型效果。
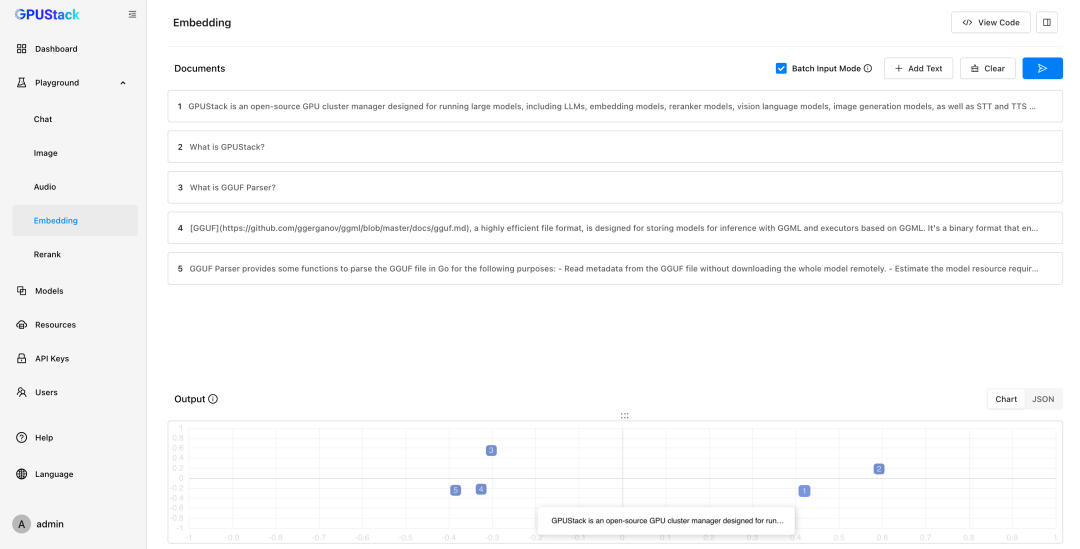
- Embedding 文本嵌入模型
在 RAG 系统中,Embedding 模型负责将文本转化为向量。GPUStack 支持在多平台上部署此类模型,其 Playground 还提供了可视化分析功能,通过 PCA 降维帮助用户直观判断文本间的向量距离和相似度。
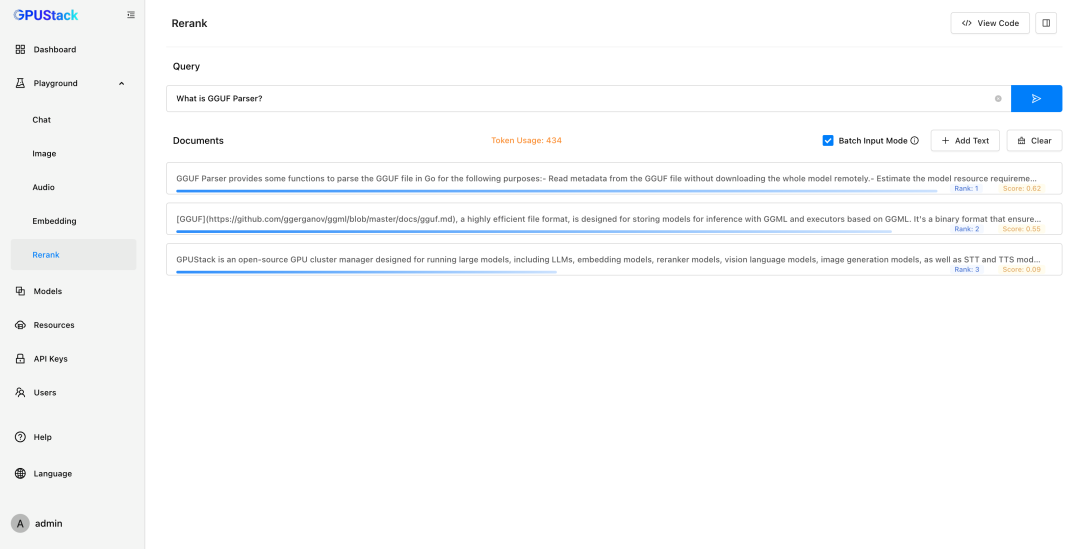
- Rerank 重排模型
Rerank 模型用于对向量检索召回的结果进行重排序,以提升 RAG 系统回答的准确性。GPUStack 支持部署此类模型,并在 Playground 中提供直观的重排结果展示。
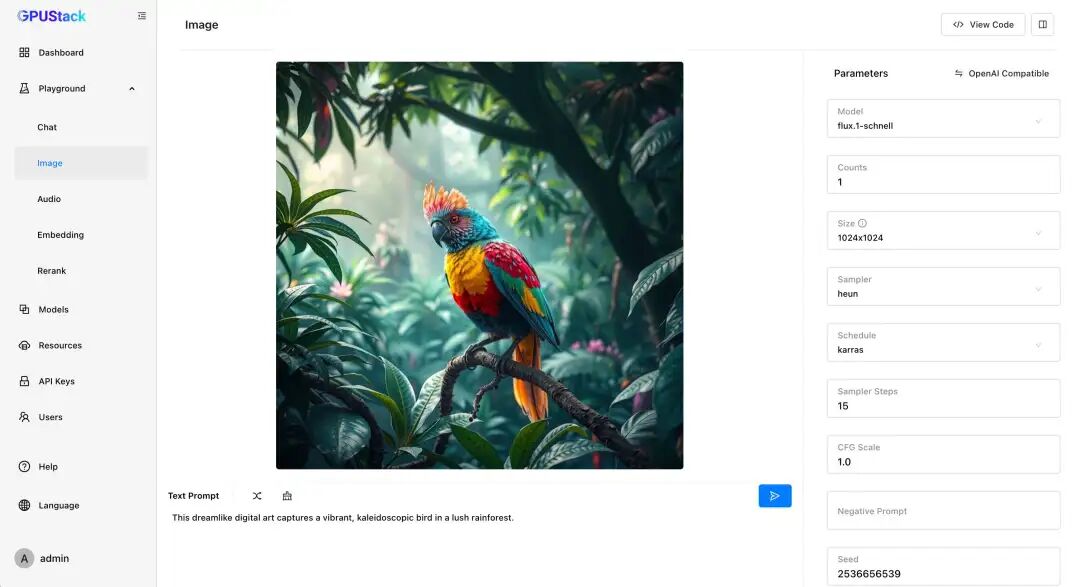
- 文生图模型
GPUStack 开箱即用地支持部署 Stable Diffusion 和 FLUX 等文生图模型,支持在多种 GPU/NPU 上运行,并提供了 Playground 供开发者调测参数。
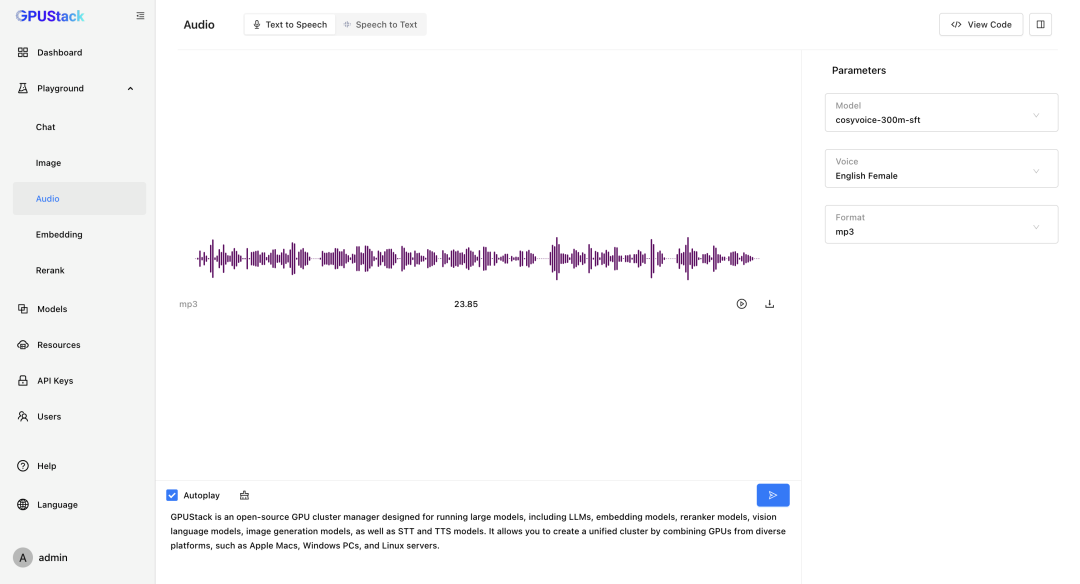
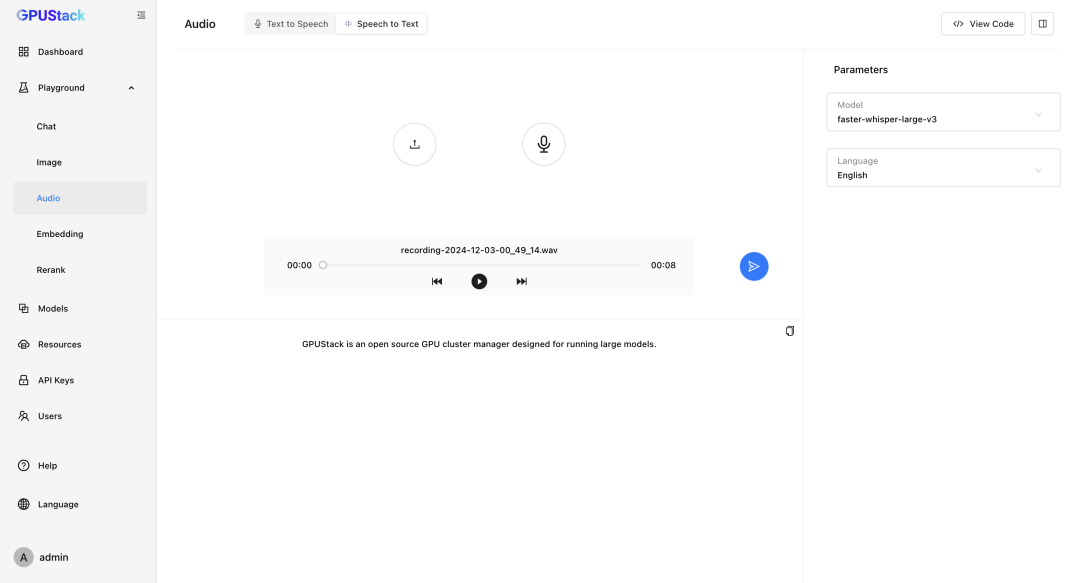
- TTS / STT 语音模型
GPUStack 支持在 NVIDIA GPU 或 CPU 上部署 TTS(文本转语音)和 STT(语音转文本)模型,并提供了相应的 Playground 进行效果调测。
4. 强大的集成对接能力
GPUStack 提供标准的 OpenAI 兼容 API,支持与 LangChain、LlamaIndex、Dify、FastGPT、Open WebUI 等各种 LLM 应用框架、RAG 应用和 AI Agent 应用无缝对接。企业可以快速将现有应用迁移至私有模型服务,并灵活构建定制化解决方案。
5. 完善的企业级管理能力
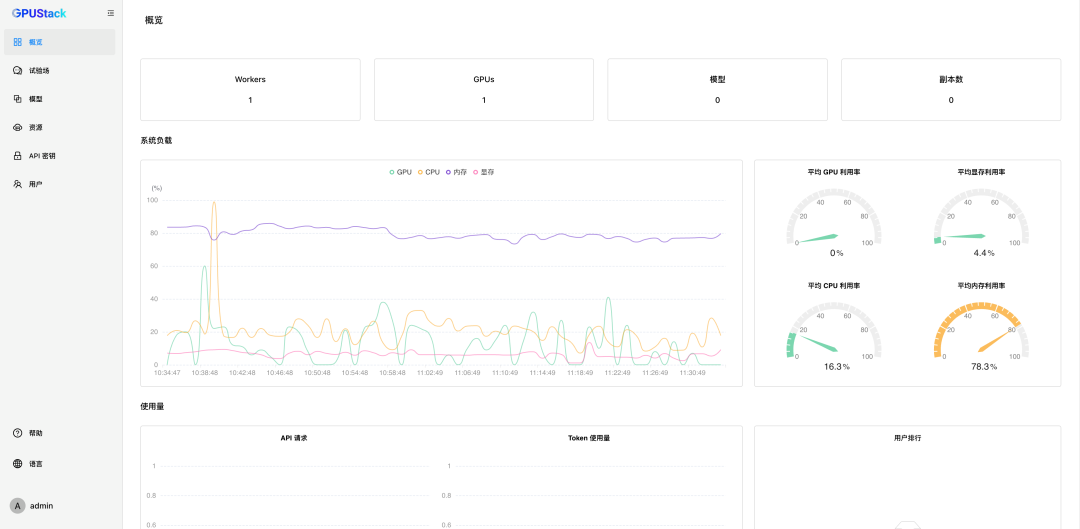
作为面向企业的解决方案,GPUStack 提供了国产化支持、就地升级、负载均衡高可用、用户与 API 密钥管理、全方位的监控仪表板、离线部署等运维管理能力,大幅降低了大语言模型私有化部署和管理的复杂度。
安装 GPUStack
系统要求:Python 3.10 ~ 3.12
在 Linux 或 macOS 上,使用以下命令安装(使用国内源加速):
curl -sfL https://get.gpustack.ai | INSTALL_INDEX_URL=https://pypi.tuna.tsinghua.edu.cn/simple sh -s - --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
在 Windows 上,以管理员身份运行 Powershell,执行以下命令(使用国内源加速):
$env:INSTALL_INDEX_URL = "https://pypi.tuna.tsinghua.edu.cn/simple"
Invoke-Expression "& { $((Invoke-WebRequest -Uri 'https://get.gpustack.ai' -UseBasicParsing).Content) } -- --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
当看到以下输出时,说明 GPUStack 已成功部署并启动:
[INFO] GPUStack service is running.
[INFO] Install complete.
GPUStack UI is available at http://localhost.
Default username is 'admin'.
To get the default password, run 'cat /var/lib/gpustack/initial_admin_password'.
CLI "gpustack" is available from the command line. (You may need to open a new terminal or re-login for the PATH changes to take effect.)
根据脚本输出指引,获取登录 GPUStack 的初始密码。
随后在浏览器中访问 GPUStack UI (默认为 http://localhost),使用用户名 admin 和上面获取的密码登录,并按提示重新设置密码。
纳管 GPU 资源
GPUStack 可以纳管不同操作系统设备上的 GPU 资源。其他节点需要通过认证 Token 加入集群。
首先,在 GPUStack Server 节点上获取 Token:
然后,在其他节点上运行以下命令,将其添加为 Worker 并纳管其 GPU 资源(请将 http://YOUR_IP_ADDRESS 替换为你的 GPUStack 服务器地址,将 YOUR_TOKEN 替换为上一步获取的 Token):
- 在 Linux 或 macOS 上:
curl -sfL https://get.gpustack.ai | INSTALL_INDEX_URL=https://pypi.tuna.tsinghua.edu.cn/simple sh -s - --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
- 在 Windows 上:
$env:INSTALL_INDEX_URL = "https://pypi.tuna.tsinghua.edu.cn/simple"
Invoke-Expression "& { $((Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content) } -- --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
完成以上步骤后,一个由 GPUStack 管理的异构 GPU 集群就搭建好了,你可以开始体验前面介绍的各项功能。
体验总结
实际体验下来,GPUStack 确实是一个低门槛、易上手、开箱即用的大模型服务平台。它的各项功能设计直观,能够帮助企业快速整合并利用起手头各种异构的 GPU 资源,在短时间内搭建起一个功能完备的企业级私有大模型服务。
GPUStack 背后是一支拥有全球顶级开源实战项目经验的研发团队,从项目功能设计到文档的完整性都做得相当出色。项目从一开始就面向全球开发者,目前用户已遍布海内外。如果你正在寻找一个能简化大模型私有部署复杂性的工具,GPUStack 无疑是一个值得深入研究和尝试的优秀选择。
再次附上 GitHub 仓库地址,感兴趣的朋友可以去了解更多详情或贡献代码:https://github.com/gpustack/gpustack
我们也会在 云栈社区 持续关注和分享类似 GPUStack 这样的优秀开源项目和技术实践,欢迎对云计算和人工智能感兴趣的朋友一起来交流探讨。
 发表于 2026-4-4 11:19:23
|
查看: 163|
回复: 0
发表于 2026-4-4 11:19:23
|
查看: 163|
回复: 0
