在构建面向AI的现代数据架构时,一个核心挑战是如何高效地管理和利用向量嵌入(Embeddings)。传统的数据湖仓库(Lakehouse)如 Apache Hudi、Apache Iceberg 和 Delta Lake 虽然在批处理和事务性数据管理上表现出色,但缺乏原生、低成本的向量生成与管理能力,导致企业需要为此引入额外的复杂基础设施。Onehouse 近期推出的 Vector Embeddings Generator 正是为了应对这一痛点而生。
产品定位:无缝集成向量化能力
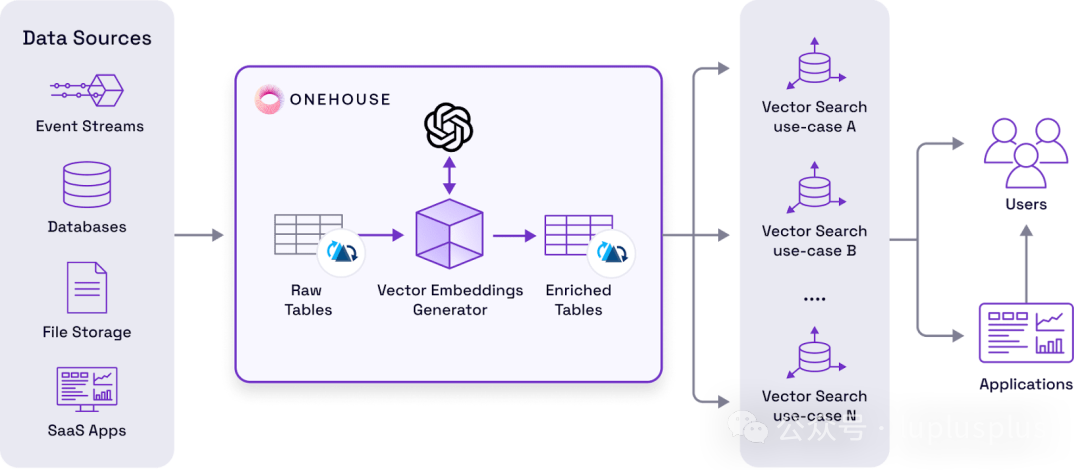
Onehouse Vector Embeddings Generator 的核心价值在于,它允许基于 Hudi、Iceberg 或 Delta Lake 构建的传统数据湖,在不改变现有架构、无需重构数据模型的前提下,自然获得“向量化能力”。它将向量视为一等公民数据,直接在数据层进行全生命周期管理。
企业可以在数据摄取(Ingest)或处理(ETL/ELT)阶段,自动为指定的文本、文档或日志列生成向量嵌入,并直接写入到 Lakehouse 表中。这尤其适用于拥有海量非结构化数据,并需要批量化或增量生成向量,以服务于 RAG(检索增强生成)、智能搜索、推荐系统或模型重训练等 人工智能 场景的企业。
核心功能一览
- 批流一体的向量自动生成:在数据摄取或ETL流水线中,直接为特定列生成向量嵌入,支持批量与流式处理。
- 灵活的模型配置:支持 OpenAI、Voyage AI 等主流嵌入模型,并允许用户轻松扩展接入自定义模型。
- 原生Lakehouse存储:生成的向量直接作为新增列或旁路列写入原数据表,享受与原始数据同等的事务一致性、版本控制和CDC能力。
- 增量更新保证新鲜度:当源数据发生变化时,支持仅对变更部分触发嵌入重计算,确保向量与原始数据实时同步。
- 向量数据库反向同步:可按需将Lakehouse中的向量数据同步到 Pinecone、Milvus 等在线向量数据库,用于低延迟检索。
- UI与Pipeline双配置通道:既提供直观的图形界面快速上手,也支持通过代码和配置文件实现工程化、自动化部署。
架构无侵入的设计哲学
传统的数据湖设计初衷是面向结构化数据的批处理存储,其表格式本身并不包含向量列的概念。Onehouse 的创新在于,它在数据摄取层或ETL处理层直接嵌入了一个向量生成流水线。该流水线将计算得到的向量以新增列或旁路列(Sidecar Columns)的形式写回原有的数据湖表中,整个过程无需:
- 将数据迁移至新的向量数据库。
- 重新设计表结构(Schema)。
- 引入一套独立的向量数据基础设施。
这使得任何现有的数据湖表都能瞬间具备向量化查询与分析的能力。
技术实现:将向量生成变为原生数据操作
Onehouse 所做的,是将“生成向量”这一过程,转变为数据湖体系内部的一个标准化的数据操作。通过下表可以清晰对比传统数据湖与集成Onehouse后的能力差异:
| 能力维度 |
传统数据湖 |
集成 Onehouse Vector Embeddings Generator 后 |
| Embedding 生成 |
不原生支持 |
支持批处理与增量流式自动生成 |
| 向量存储与管理 |
可以存储,但缺乏版本、事务等管控 |
事务级存储,具备完善的版本化与生命周期管理 |
| 模型调用与管理 |
无此能力,需自行封装 |
统一的模型管理层,支持OpenAI、Voyage及自定义模型 |
| 向量同步至在线库 |
需额外开发反向ETL任务 |
提供自动化的向量数据库反向ETL同步 |
| Embedding 数据新鲜度 |
需自建复杂的CDC管道保证 |
基于CDC与增量处理自动触发更新,仅计算变化部分 |
本质上,Onehouse 将向量嵌入变成了“数据流水线内原生的衍生列”,使向量成为一种“湖原生特性”(Lake-native Feature)。
这意味着:
- 任何下游的分析任务或AI流水线都可以直接读取并使用这些已生成的向量列。
- Lakehouse 成为了所有RAG应用和向量数据的 “唯一真相源”(Single Source of Truth)。
- 外部的向量数据库(如Pinecone)则退居为纯粹的 “加速服务层”(Serving Layer),用于优化在线检索性能,而非核心数据存储。
这是一种架构范式的转变。企业无需引入全新的数据库、不必重构现有系统架构、也无需工程团队重写大量数据流水线代码,即可让现有的 数据湖 基础设施平滑升级,具备强大的AI就绪(AI-ready)能力。 |  发表于 2025-12-11 03:10:51
|
查看: 244|
回复: 0
发表于 2025-12-11 03:10:51
|
查看: 244|
回复: 0
