顶流官宣导致服务器宕机?本文拆解 100 万 QPS 热点流量击穿 Redis 的真实面试场景,从为什么“加机器没用”讲起,逐步深入多级缓存架构、热 Key 动态发现与自适应防御等核心方案,文末附上面试思路模板,助你系统性地应对高并发缓存难题。
前两天一位朋友向我吐槽,他在新浪微博的二面中,被一道“吃瓜题”给问倒了。
面试官的问题是:“假设一个拥有千万级粉丝的顶流明星突然官宣婚讯,瞬间涌入 100 万 QPS 的并发流量查询这条动态。如果数据缓存在 Redis 里,你会如何应对?”
他心想这题简单,平时 Redis 的八股文背得挺熟,于是答道:“单机扛不住就上 Redis Cluster 集群,横向扩容,加个 10 台、20 台机器,别说 100 万 QPS,再来一倍也能扛住!”
面试官听后冷笑一声,接连抛出三个灵魂拷问:
- “你知道 Redis 集群的数据路由规则吗?同一个 Key 只会落在唯一一个节点上。这 100 万 QPS 全打在这一个节点,另外 19 台机器都在‘围观’。机器加得再多有什么用?”
- “退一步讲,单点 Redis 官方理论值也就 10 万 QPS 左右,真实业务带上大 Value,网卡早就被打爆了。单节点挂掉触发主从切换,这百万并发瞬间穿透到 MySQL,数据库直接熔断,这责任谁来背?”
- “最关键的是,你怎么在系统崩溃之前,提前发现并识别出这个‘热 Key’?”
他瞬间汗流浃背。其实,这道题考察的核心并非简单的缓存使用,而是 “超高并发场景下的热点缓存架构设计”。下面,我们来系统地拆解应对热 Key 的几种进阶方案。
一、为什么传统的“加机器扩容”会失效?
在高并发场景下,热点 Key(Hot Key)是系统的绝对杀手。100 万 QPS 读取同一个 Key,在 Redis Cluster 架构下,请求会通过 CRC16(key) % 16384 的哈希算法,精准地路由到集群中的唯一一个分片(Node)上。
很多人认为单机 Redis 能抗住 10 万 QPS,但那是在 Value 极小情况下的理想值。真实业务中,一个几 KB 的 Value 乘以几十万的 QPS,瞬间就会造成千兆网卡阻塞、CPU 飙升至 100%。
因此,面对单一热 Key,单纯地横向扩充Redis节点数量是无效的。我们必须转变思路,从 “流量拦截” 和 “数据打散” 两个维度入手。
二、核心架构:三种主流解决方案
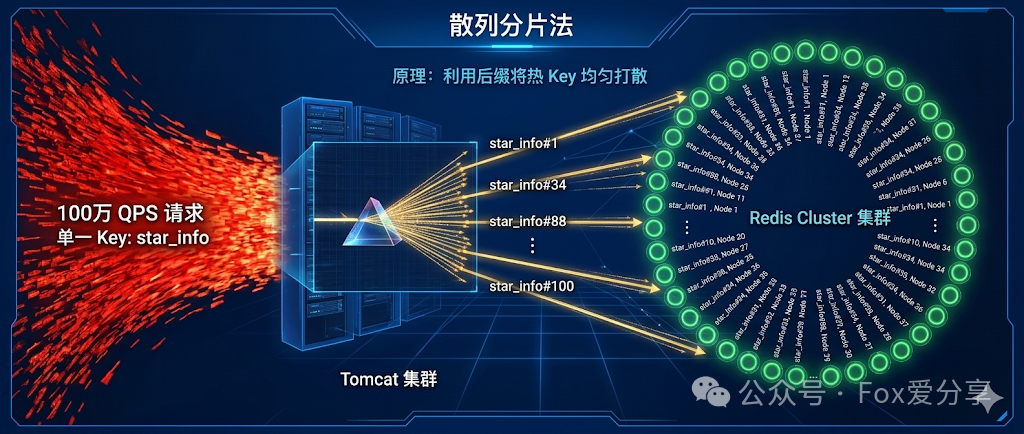
解法 1:散列分片法
既然一个 Key 只能落在一个节点上,那我们就把它“变成”多个 Key。
- 方案:给这个热 Key 加上随机后缀。例如,原始 Key 为
star_info,我们将其复制为 star_info#1 到 star_info#100,将同一份数据存放到集群的不同节点上。
- 效果:客户端请求时,在应用层生成一个 1~100 的随机数,拼接在 Key 后面再去查询。这样,100 万 QPS 的流量就被均匀地打散到了整个集群的各个节点。
- 局限性:这种方法治标不治本,严重浪费 Redis 内存。而且,一旦明星修改了动态,需要更新 100 个 Key,数据一致性的维护成本极高。
解法 2:多级缓存架构
这是大厂应对突发流量的标准配置,核心思想是:“让流量死在离用户最近的地方。”
- 方案:在应用层引入 JVM 本地缓存,例如 Caffeine 或 Guava Cache。
- 执行逻辑:
- 用户请求到达应用服务器(如 Tomcat)后,首先查询本地的 Caffeine 缓存,如果命中则直接返回。
- 如果本地缓存未命中,再去查询后端的 Redis 集群,获取到数据后,不仅返回给用户,同时写回本地缓存(通常会设置一个较短的过期时间,例如 3 秒)。
- 效果:假设有 100 台 Tomcat 应用服务器。100 万 QPS 的流量被分摊到这 100 台服务器上(每台约 1 万 QPS)。由于本地缓存的存在,绝大部分请求(例如 99%)在 Tomcat 的 JVM 内存中就被拦截并返回了。最终穿透到 Redis 的请求可能只剩下几千 QPS,压力骤减。

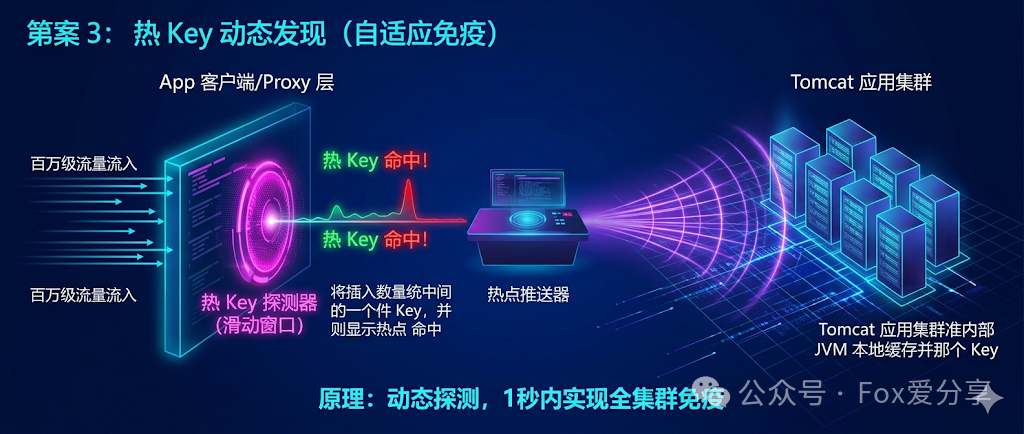
解法 3:热 Key 动态发现与自适应
面试官最喜欢追问细节:“你怎么知道哪个 Key 会变热?等你发现系统宕机了再去发版加本地缓存,早就被开除了。”
这就需要系统具备动态感知和自愈能力。
- 方案:搭建独立的热点探测框架,例如京东开源的
Jdhotkey。
- 原理:
- 探测器:在客户端或代理层(如 Nginx)基于滑动窗口进行访问统计。例如,设定规则为“某 Key 在 1 秒内被访问超过 1000 次”,则自动将其判定为热 Key。
- 推送器:探测到热 Key 后,立刻通过长连接或消息队列(如 Kafka)将热点信息推送到所有的业务集群节点。
- 自适应:业务节点接收到热点通知后,自动将该 Key 加载到本地的 JVM 缓存中。
- 效果:系统具备了 “自动免疫” 能力。在顶流爆雷的极短时间内(例如 1 秒),系统就能自动完成“探测-发现-推送-缓存”的完整防御闭环,实现自愈。
三、面试“防杠”指南与深入追问
当你清晰地阐述了多级缓存方案后,面试官很可能会追问一些极端场景,以考察你的方案是否周全。
Q1:加了本地缓存后,如果明星在这 3 秒的缓存有效期内又修改了文案,导致各台机器上的本地缓存数据不一致怎么办?
答:“在微博这类大流量的 C 端读场景下,我们必须拥抱最终一致性。首先,为本地缓存设置极短的 TTL(例如 3 秒),3 秒的数据延迟在这种场景下是完全可接受的。其次,如果业务对一致性要求更高,可以通过 Redis 的 Pub/Sub 功能或消息队列进行广播,在数据更新时主动通知所有业务节点,使其本地缓存失效。”
Q2:如果本地缓存和 Redis 缓存刚好在同一时刻失效,发生‘缓存击穿’,所有请求瞬间打向数据库怎么办?
答:“我会在重建缓存的代码逻辑中,加入互斥锁(Mutex Lock) 或者采用逻辑过期机制。确保同一时刻,针对同一个 Key,只有一个线程能去查询数据库并回写缓存,其他线程则短暂等待后重试缓存,或者直接返回一个预设的降级默认值。核心目的是保护数据库,防止其被瞬间洪峰击垮。”
四、面试标准答案思路(参考模板)
面对此类问题,可以遵循以下结构进行回答:
“面对百万级 QPS 的单 Key 突发高并发,单纯横向扩容 Redis 节点是无效的,因为哈希槽机制会导致请求集中,单机网卡和 CPU 极易过载。我的核心设计思路是 ‘主动探测 + 多级拦截 + 互斥兜底’ :
- 架构选型:采用 Caffeine(本地内存)+ Redis 的多级缓存架构,利用应用服务器集群将绝大部分读流量拦截在 JVM 内存层面。
- 动态防御:引入独立的热 Key 探测机制(如滑动窗口统计),在流量飙升的瞬间自动发现热点,并通过实时通道将热点数据动态推送到各节点的本地缓存,实现系统自愈。
- 一致性与兜底:通过为本地缓存设置短 TTL 来保证最终一致性,必要时可结合 MQ 广播实现缓存失效。同时,在缓存重建逻辑中加入互斥锁,防止缓存同时失效导致的数据库击穿。
- 终极防线:在整个链路配合限流熔断组件(如 Sentinel),设置全局 QPS 阈值,宁可优雅地拒绝部分非核心请求,也要确保核心链路和数据库不雪崩。”
写在最后
技术面试考察的从来不是你是否会启动几个 Redis 实例,而是你对分布式系统中资源分配、流量治理以及极端情况防御的深度思考。在百万 QPS 的洪峰面前,能够看透简单扩容的局限,并熟练运用多级缓存、热点探测等组合拳进行架构设计,这才是与普通开发者拉开差距的关键。
希望这篇来自真实面试场景的剖析能对你有所启发。在技术社区如云栈社区中,也常有关类似架构难题的深度讨论。最后留一个思考题:我们解决了高并发读的热点问题,但如果是突发的极高并发写操作(比如演唱会门票秒杀),多级缓存就失效了。在这种场景下,通常有哪些架构方案来抗住数据库的瞬间写压力?欢迎分享你的见解。
 发表于 2026-4-5 07:19:54
|
查看: 110|
回复: 0
发表于 2026-4-5 07:19:54
|
查看: 110|
回复: 0
