最近在抖音上,总能看到一类直播间,标题清一色是“1分钟教你本地部署DeepSeek满血版”。内容也高度雷同,基本都在讲如何部署Ollama、ChatBox这些工具。老实说,除了耽误你看小姐姐跳舞的时间外,这些内容真的用处不大。
为什么这么说?听完下面的分析,你大概就能明白,与其花时间看这些直播,不如把精力花在真正该关注的技术点上。作为技术人,我们更应该关注诸如人工智能模型部署背后的核心逻辑与实践细节。
部署前必须评估的算力:你的GPU够用吗?
运行大模型的核心是算力,通常由GPU提供。在动手之前,你必须先想清楚两个问题:
我的电脑能不能跑起来大模型?能跑起来多大参数量的模型?
如果你的电脑没有独立GPU或者只有核显,那么部署个1.5B左右的模型尝尝鲜就行了,纯CPU推理速度勉强可以接受。但如果你想运行7B以上的模型,没有GPU的支持,CPU推理的生成速度会非常“感人”。
那么,模型参数量和性能到底怎么关联?通常,参数规模越大,模型的推理准确性和泛化能力越强,但同时对显存的需求也呈指数级增长,推理时间也可能更长。
显存需求计算:不止是模型参数
计算推理所需的显存,不能只看模型基础参数占用的部分,还必须考虑KV cache、激活值以及其他系统开销。
很多简化教程只给了基础显存的估算公式:
模型基础显存 (GB) = (P × Q) / 8
其中:
P 是模型参数量(单位是亿)Q 是加载模型使用的位数(如BF16是16,FP32是32)
以 DeepSeek-R1-Distill-Qwen-7B 为例,其参数规模为7B(即70亿),若以BF16精度加载,基础显存需求为:
(70 × 16) / 8 = 140 GB? 等等,这个计算显然有问题。
实际上,7B模型的参数量是7,000,000,000个。每个BF16参数占用2字节。因此基础显存占用约为:
7,000,000,000 × 2 bytes ≈ 14,000,000,000 bytes ≈ 13.04 GB。
这意味着,仅加载这个模型,就至少需要13GB以上的空闲显存。
显存刺客:上下文长度
抛开上下文长度谈显存就是耍流氓。上下文越长,KV cache占用的显存就越大。我们可以用工具直观感受不同上下文长度下的显存占用差异:
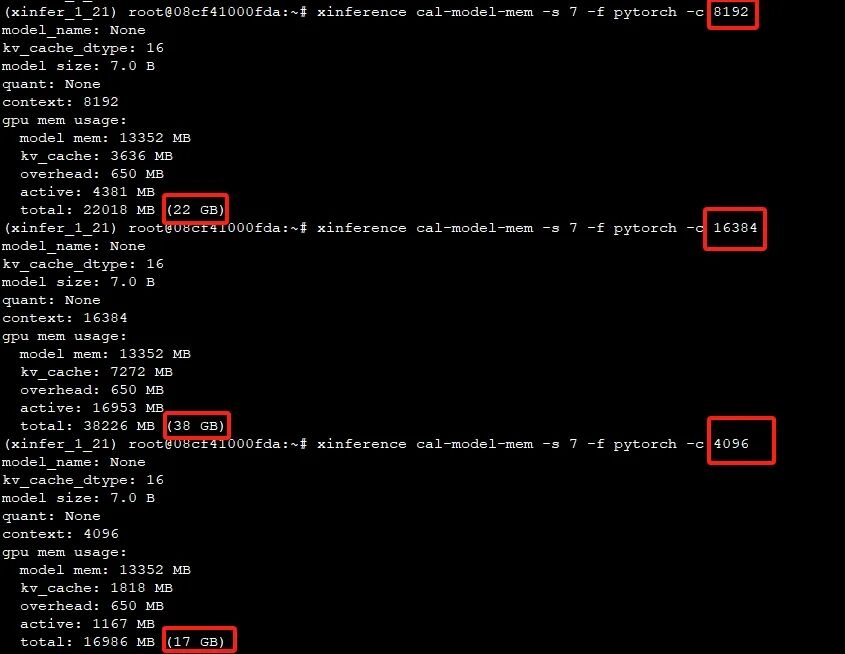
从上图可以看出,上下文长度从4K翻倍到8K,总显存需求从约17GB增加到22GB;再翻倍到16K,则需要惊人的38GB。因此,在显存有限的情况下,必须严格控制上下文长度。
下图更清晰地展示了DeepSeek-R1系列模型在稳定运行时的显存需求,这比那些直播里简单估算的表格要严谨得多:
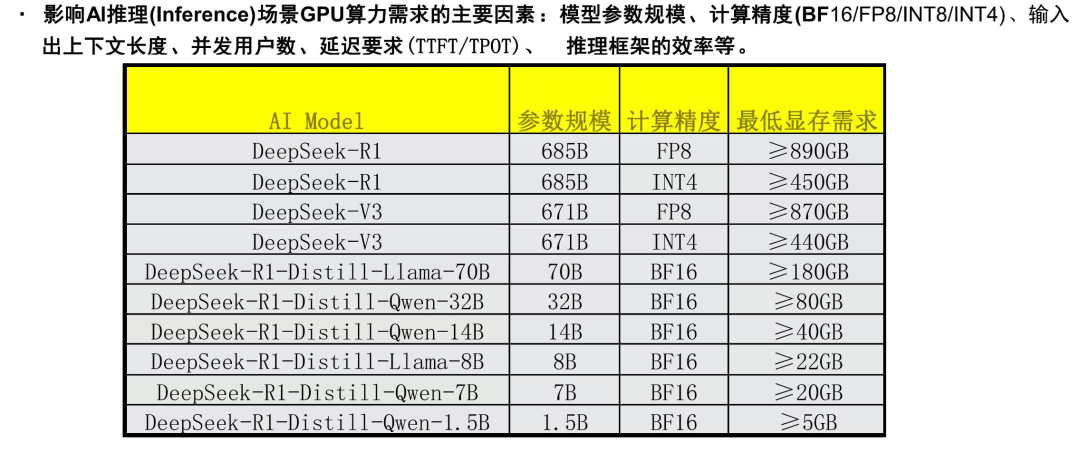
注意,上表中R1的参数量为685B(包含了14B的MTP模块参数),并且列出的显存需求已经是经过FP8或INT4量化后的结果。如果以BF16原生精度运行,所需的显存会更高,可能需要双节点8卡H100这样的集群才能部署。
所以,如果你的GPU配置不足,与其折腾本地部署,不如直接使用SiliconFlow等平台提供的免费API来调用1.5B、7B等蒸馏模型,岂不更香?
推理框架选择:Ollama 还是 vLLM?
另一个常见的误区是过度依赖Ollama。它的优点是安装简单,上手容易。但说句实在话,Ollama更像一个“玩具”,很难用于生产环境。其最致命的问题是并发处理能力有限。
相比之下,vLLM 是一个高性能的推理引擎。它通过 Paged Attention 技术高效管理KV缓存,实现了比原生Transformers高14-24倍的吞吐量。因此,在选择推理框架时,是否支持vLLM是一个重要考量。
我个人更推荐使用 Xinference 来替代Ollama。它支持的推理后端非常丰富,包括 transformers、vLLM、Llama.cpp、SGLang等,并且支持多卡、多副本部署,在实用性和性能上远超Ollama,部署起来也并不复杂。深入理解不同推理框架的优劣,是进行技术文档级部署的必要功课。
认清现实:你部署的到底是什么?
最后,我们需要清醒地认识到,本地部署的小规模模型能力是有限的。例如,7B模型有时会出现中英文混杂的输出,对Function Call的支持也不够好。最重要的是,我们部署的本质上并非DeepSeek-R1本体。
看看官方在HuggingFace上发布的模型列表,关键词是 “DeepSeek-R1-Distill Models”。
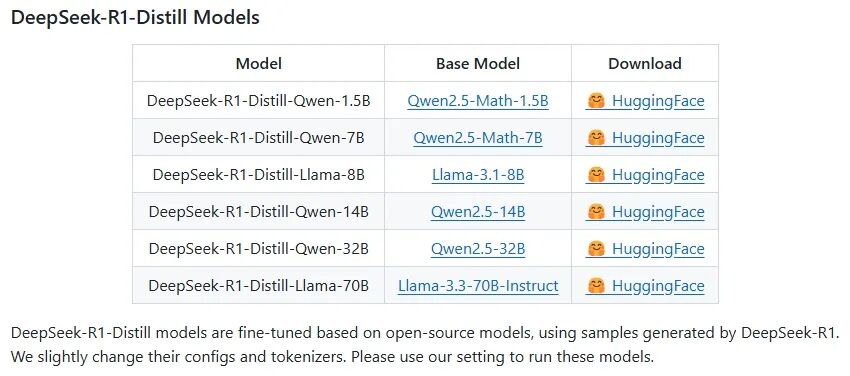
Distill,意为“蒸馏”。从1.5B到70B的这些模型,都是通过知识蒸馏技术,将庞大R1模型的推理能力迁移到小规模开源模型(如Qwen、Llama)上的产物。
以 DeepSeek-R1-Distill-Qwen-7B 为例,它基于 Qwen2.5-Math-7B 蒸馏而来。这个过程虽然验证了大模型能力迁移的可能性,但蒸馏模型与原始“满血版”在性能上必然存在差距,且在实际应用中可能还需要大量的适配和调试工作。
总结:技术祛魅比盲目追新更重要
在这个技术快速迭代的时代,保持清醒的认知远比盲目追随热点重要。当屏幕上充斥着各种“一键部署”的诱人教程时,我们更应该关注其背后真正的技术逻辑、资源需求和实用性。
省下被无效信息消耗的时间,去钻研真正的核心技术,或者,就像开头说的,多看几个小姐姐跳舞也不错。如果你在部署过程中遇到了更深层次的技术问题,或想了解更多开源实战经验,不妨来云栈社区和大家一起交流探讨。
 发表于 2026-4-7 06:46:02
|
查看: 151|
回复: 0
发表于 2026-4-7 06:46:02
|
查看: 151|
回复: 0
