最近维护内部自动化测试平台时,面临一个挑战:随着开发同学“vibe coding”效率提升,产出的功能更多,测试同学的压力也随之增大。为此,我的一个主要工作方向就是为平台接入 AI 能力,以减轻测试负担。
期间,我主要实现了两个功能:
- 接入飞书 MCP,让系统能够读取飞书文档中的需求,自动生成测试用例。
- 录制系统的网络请求日志(HAR文件),由系统进行 AI 分析,自动产出 API 自动化测试工作流。
今天,我想重点聊聊第二个功能——“产出自动化测试工作流” 的实现。这听起来是个复杂的需求,但我找到了一种“偷懒”的方式,让整个开发过程变得异常“顺滑”,且最终效果稳定可靠。
需求与初始设计:为何需要AI?
首先,明确一下什么是 HAR 文件。
HAR (HTTP Archive):由浏览器或抓包工具记录的一次完整网络请求日志,本质上是 JSON 格式。
我们的目标,就是让测试同学录制的 HAR 文件能一键导入,并转化为结构化的自动化测试工作流。即:HTTP 请求日志 -> 自动化测试工作流。
然而,直接导入 HAR 文件存在两个核心问题:
- 节点语义缺失:从 HAR 中只能提取 URL、请求体等信息,无法直观理解每个接口(节点)的实际业务作用。
- 节点关系混乱:虽然可以按请求时间串联节点,但实际场景中存在大量并发请求,简单按时间排序生成的工作流与真实业务逻辑相差甚远。
因此,解决方案是引入 AI,让它结合系统源码来分析 HAR 文件,从而合理地编排节点顺序,并为每个节点填充准确、易懂的业务名称。
第一套方案:自研AI Agent的复杂性与放弃
最初,我们计划通过 OpenAI 兼容的接口,接入公司现有的各类大模型(如 GLM、MiniMax、DeepSeek 等),让模型直接分析“源码 + HAR 初步转换的 JSON”来生成最终的工作流。
但尝试后发现问题巨大:源码量通常很大,不可能通过一次 LLM 调用来完成全部分析。这就需要设计一个多轮调用、结合代码检索的复杂 Agent 系统。随之而来的,是必须处理工具调度、模型调用兼容性、任务队列、重试恢复、状态轮询、结果回写等一系列繁琐的工程问题。
我们的测试系统后端采用 Golang 编写。虽然 Go 生态中有类似 LangChain 的框架(如 LangChainGo)可以减轻部分工作量,但整体工程量依然庞大。这几乎等同于要实现一个简化版的 Claude Code 或 Codex。综合考虑开发成本、效果稳定性和项目进度后,这个方案很快就被我们 Pass 掉了。
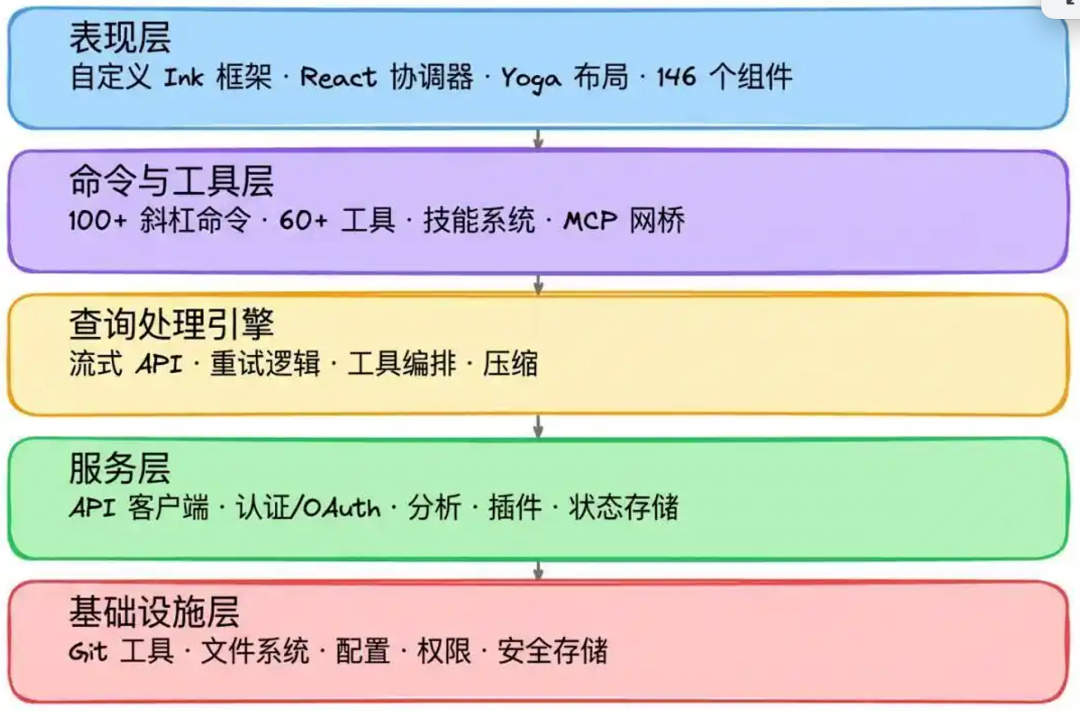
(图为近期 Claude 源码泄露后,分析出的其多层级架构设计,实现类似系统复杂度很高)
最终方案:系统集成 Codex CLI
最终,我们选择了一条更快捷的路径:直接在 Docker 容器中部署 Codex CLI。当需要进行 AI 增强时,系统直接调用这个现成的 Codex 程序来完成分析工作。
你可能会问,为什么不选能力可能更强的 Claude Code?原因很简单:Claude Code 当前封号严重,缺乏稳定可靠的使用渠道。
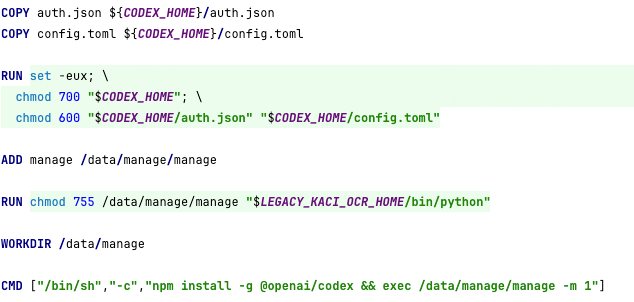
1. 部署安装
部署非常简单,只需在项目的 Dockerfile 中增加安装 Codex 的步骤,并将配置好的 auth.json 和 config.toml 文件复制到容器中即可。容器启动时,Codex 环境就自动就绪了。
2. 功能实现流程
下图清晰地展示了从 HAR 导入到 AI 增强的完整流程:
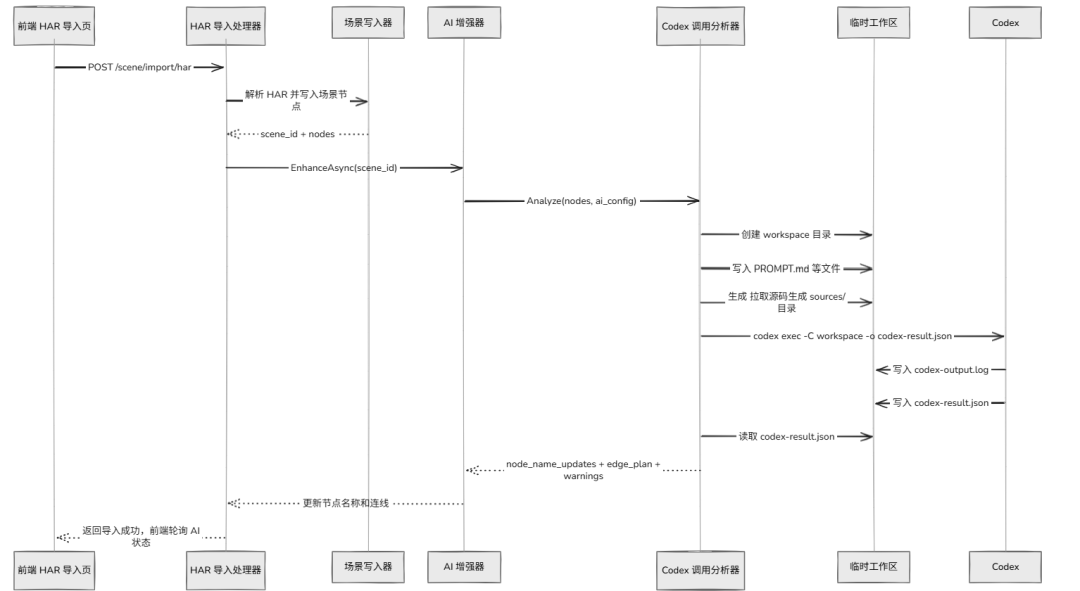
简单来说,当 HAR 被初步解析后,系统会创建一个临时工作目录。目录中包含了待分析的源码、精心设计的提示词(PROMPT)、以及从 HAR 初步转换来的原始工作流数据。然后,系统将这一整套“资料”喂给 Codex,由它结合源码分析,输出最终优化后的测试工作流。
工作目录中的关键文件及其作用如下:
| 文件或目录 |
生成阶段 |
作用 |
flow.raw.json |
工作区初始化 |
保存 HAR 文件解析后生成的原始 flow 数据 |
flow.semantic.json |
工作区初始化 |
提供精简后的语义视图,便于 AI 推断命名和依赖 |
FLOW_GLOSSARY.md |
工作区初始化 |
解释关键字段和分析约束 |
sources/ |
源码工件落盘 |
存放下载或解压后的前后端源码 |
source_manifest.json |
源码工件落盘后 |
记录每个源码工件的来源、状态、路径和大小 |
codex-schema.json |
执行前 |
约束 Codex 输出 JSON 结构(符合我们系统的数据模型) |
PROMPT.md |
执行前 |
规定 Codex 的读取顺序、任务目标和硬约束 |
codex-output.log |
首次执行时 |
保存首次执行的 stdout/stderr 日志 |
codex-output-fallback.log |
回退执行时 |
保存降级到无沙箱模式后的日志 |
codex-result.json |
执行完成后 |
保存最终的结构化分析结果 |
整个流程可以通俗地理解为:
-
下达明确指令:PROMPT.md 是“总指挥”,它告诉 Codex 需要按顺序读取哪些文件,并明确两大任务:① 为节点填充简洁的中文业务标签;② 提出最佳的节点间连线(依赖)方案。同时,它还设定了一系列“强约束”,防止 AI 自由发挥导致输出不可用,例如严禁增删节点、严禁创建循环依赖等。
你正在分析一个 HAR 导入工作区。
在回答前,请先读取以下工作区文件:
- PROMPT.md
- FLOW_GLOSSARY.md
- flow.semantic.json
- flow.raw.json
- source_manifest.json
- sources/ 下的相关文件
任务:
1. 将节点名称替换为简洁的中文业务标签。
2. 为现有节点提出最佳的有向边连线方案。
强约束:
- 只能重命名现有节点,并且只能在现有节点之间建议连线。
- 严禁虚构、删除、合并、拆分或重排节点。
- 严禁修改 node_id 的值。
- 严禁建议 source sequence >= target sequence 的边。
- 严禁创建环、反向边或自环。
- 严禁修改任何 RunnerGo 数据模型或返回结构。
- 若某条边的置信度较低,宁可省略,也不要猜测。
- 若节点名称语义不清晰,请保持接近“业务动作 - METHOD /path”的格式。
- 避免使用“接口、请求、节点、步骤、API”这类过于泛化的名称。
-
提供业务上下文:FLOW_GLOSSARY.md 是“术语表”,它向 Codex 解释工作流数据模型中各个字段的含义(如 sequence, dependency_references 等),帮助 AI 更好地理解数据结构与业务逻辑。
HAR导入流程术语表
- 每个节点代表一个转化为API节点的HAR请求。
- 序列是不可变的导入顺序。任何建议的边必须保持源序列 < 目标序列。
- current_prev_ids和current_next_ids是当前持久化的回退链接。它们是有效的数据模型链接,但可能仅反映HAR的顺序。
- response_extractors 列出了已从节点响应中提取的变量。
- dependency_references 列出了已在请求头、查询参数或正文字段中使用的 {{variable}} 占位符。
- 利用源代码、路由处理程序、API客户端、服务、用户旅程转换以及现有的依赖线索来改进名称和边。
- 切勿添加或删除节点。仅可重命名现有节点,并建议在现有节点ID之间添加边。
- 准备分析材料:
flow.raw.json 是原始的、待优化的测试工作流数据;source_manifest.json 则记录了本次分析所关联的系统源码位置(源码会根据测试场景动态下载)。
- 执行分析与约束输出:系统通过 Golang 的
os.exec 在沙盒中异步启动 Codex 进程。关键的执行命令如下:
cat PROMPT.md | codex exec - \
--skip-git-repo-check \
--ephemeral \
--color never \
-C 工作目录 \
--output-schema codex-schema.json \
-o codex-result.json \
--sandbox <sandbox>
这里有两个重要文件:
codex-schema.json:这是我们系统定义的、标准的测试工作流 JSON Schema,用于严格约束 Codex 的输出格式。codex-result.json:Codex 增强后输出的最终结果文件。
- 结果回写:当 Codex 执行成功并生成
codex-result.json 后,系统会用这个优化后的 JSON 文件替换掉最初由 HAR 直接转换的原始工作流数据。至此,一个经由 AI 分析增强的、节点命名清晰、依赖关系合理的自动化测试工作流就生成了。
总结与适用场景探讨
选择直接集成 Codex CLI,让整个 AI 增强功能的实现过程变得异常平滑,效果也足够稳定。如果完全自研一个具备类似能力的 Agent,需要考虑的边界条件和异常情况太多,很难一次性调整到位,且最终效果很可能不如直接使用成熟的 Codex。
当然,这种模式并非万能。它不适合 C 端需要高频、实时交互的智能体场景,因为单次分析耗时较长,且每个 Codex 进程都会占用可观的服务器资源。
然而,在某些特定场景下,这却是一个高效的选择:
✅ 适合场景:
- 内部系统或 B 端产品:对响应时间相对宽容。
- 低频高价值任务:如测试用例生成、代码审查、设计稿转代码等,不要求毫秒级响应。
- 可异步处理的任务:用户提交任务后,可以轮询结果或等待通知。
- 有明确输入输出约束的任务:可以通过 Schema 和详细 Prompt 严格控制 AI 输出范围。
❌ 不适合场景:
- C 端高频实时交互(如聊天机器人)。
- 强 SLA(服务等级协议)要求的实时接口。
- 多租户且对资源隔离要求极高的场景。
- 对成本极其敏感,需要精细控制每次调用的场景。
在 人工智能 技术落地过程中,尤其是在企业内部系统或 B 端产品中,当面临一些可异步执行的复杂分析任务时,不妨先看看市场上是否有像 Claude Code、Codex、OpenClaw 这样的成熟智能体可以直接集成。“不重复造轮子”,利用其稳定、成熟的特性能让我们快速验证想法、实现功能,这本身就是一种高效的技术决策。我们后端采用 Golang 开发,其简洁高效的特点与这种“集成即用”的思路相得益彰,共同促成了项目的快速落地。关于更多 Go 语言在高效后端开发中的实践,你可以在 Go 板块找到丰富的讨论和资源。
 发表于 2026-4-8 02:50:50
|
查看: 149|
回复: 0
发表于 2026-4-8 02:50:50
|
查看: 149|
回复: 0
