在视觉场景中识别并分割任意物体的能力,是推动多模态人工智能发展的关键基石,其应用场景广泛覆盖机器人、内容创作、增强现实与数据标注等诸多领域。由 Meta 于 2023 年发布的 SAM(Segment Anything Model)模型,定义了通用的可提示分割任务,支持通过点、框或掩码提示来分割图像或视频中的单个目标。
此前推出的 SAM 与 SAM 2 模型在图像分割领域取得了显著成果,但尚未实现根据输入概念自动寻找并分割所有实例的功能。为了突破这一局限,Meta 正式推出了最新迭代版本——SAM 3。新版模型不仅在可提示视觉分割(PVS)性能上大幅超越前代,更首次为可提示概念分割(PCS)任务设立了新的性能标杆。
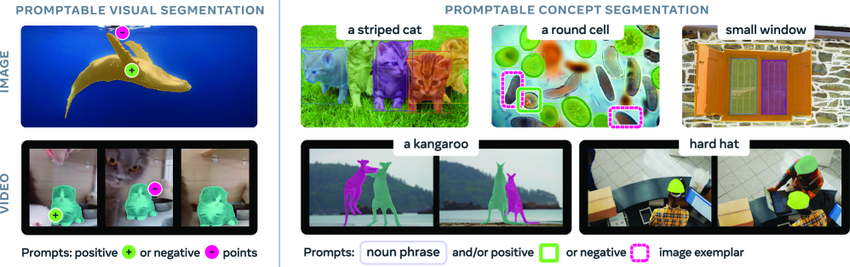 SAM 3 在点击提示的视觉分割方面(左图)超越了 SAM 2,并引入了新的可提示概念分割功能(右图)
SAM 3 在点击提示的视觉分割方面(左图)超越了 SAM 2,并引入了新的可提示概念分割功能(右图)
SAM 3 的架构设计包含一个检测器(detector)与一个跟踪器(tracker),二者共享同一个视觉编码器。检测器基于 DETR 框架构建,能够接收文本、几何信息或示例图像作为条件输入。为应对开放词汇概念检测的复杂性,研究团队创新性地引入了一个独立的「存在头(presence head)」,以此将识别与定位过程进行解耦。
跟踪器部分则延续了 SAM 2 所采用的 Transformer 编码器-解码器架构,继续支持视频分割与交互式优化任务。这种将检测与跟踪分离的设计思路,有效避免了任务间的潜在冲突:检测器需保持身份无关性,而跟踪器的核心使命正是在视频序列中区分并维持不同对象的身份标识。
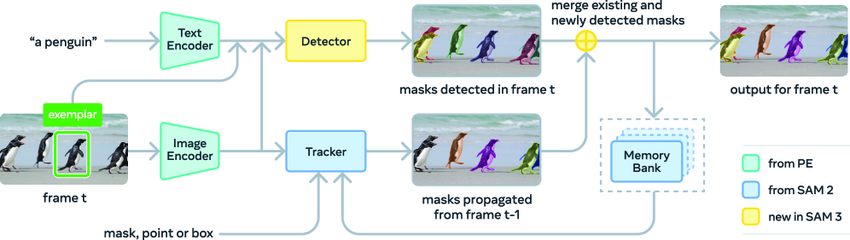 SAM 3 架构图
SAM 3 架构图
在基准测试 SA-Co 的图像与视频 PCS 任务中,SAM 3 均取得了当前最优(SOTA)的结果,其性能达到前代系统的 2 倍。在 H200 GPU 上,处理包含超过 100 个检测对象的单张图像仅需 30 毫秒,展现出极高的效率。该模型的能力还可扩展至 3D 重建领域,为家装预览、创意视频编辑和科学研究等多样化应用场景提供强大支持,持续赋能计算机视觉的未来发展。
Demo 运行指南
教程链接:
https://g***o.hyper.ai/Ab*yCq**
论文地址:
https://hyper.ai/papers/2511.16719
-
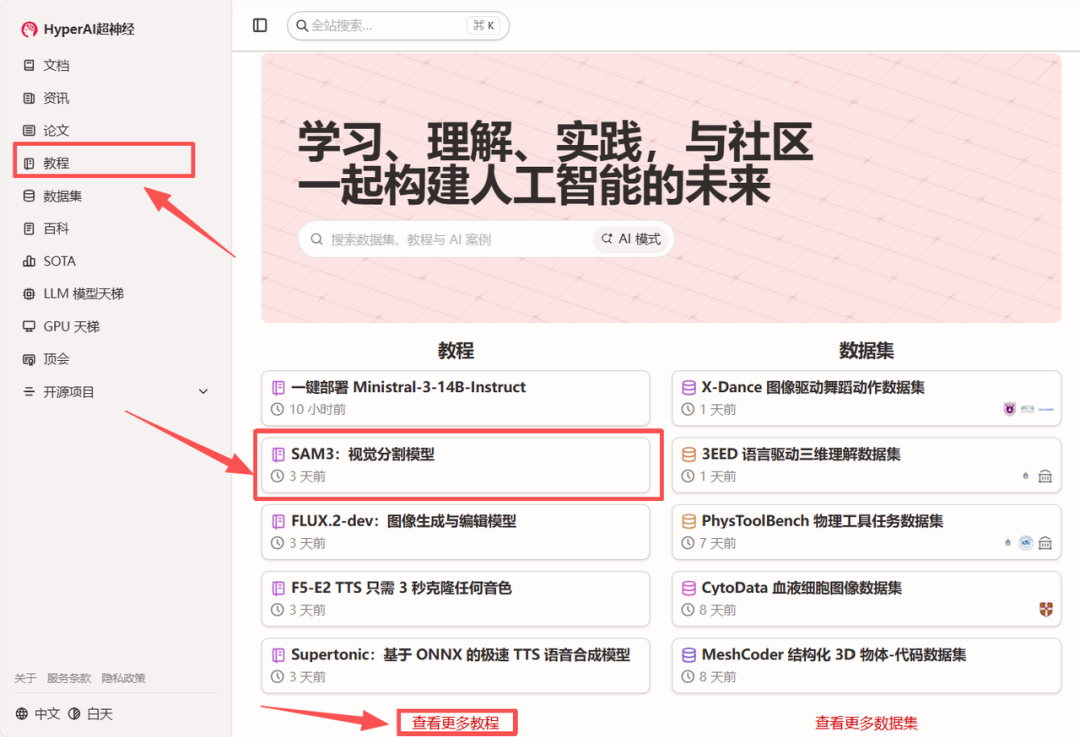
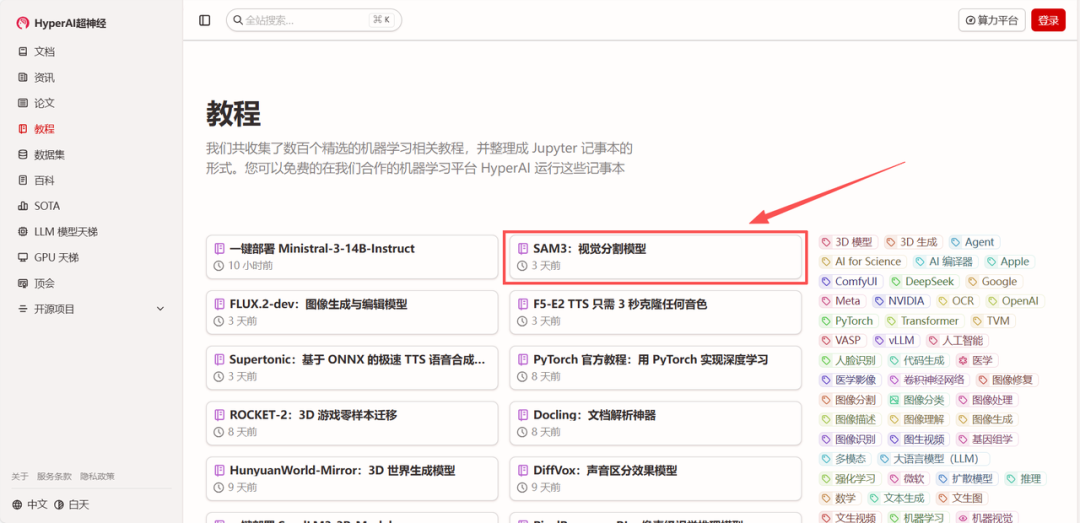
访问教程:进入 hyper.ai 首页,选择「SAM3:视觉分割模型」,或进入「教程」页面进行选择。进入后点击「在线运行此教程」。
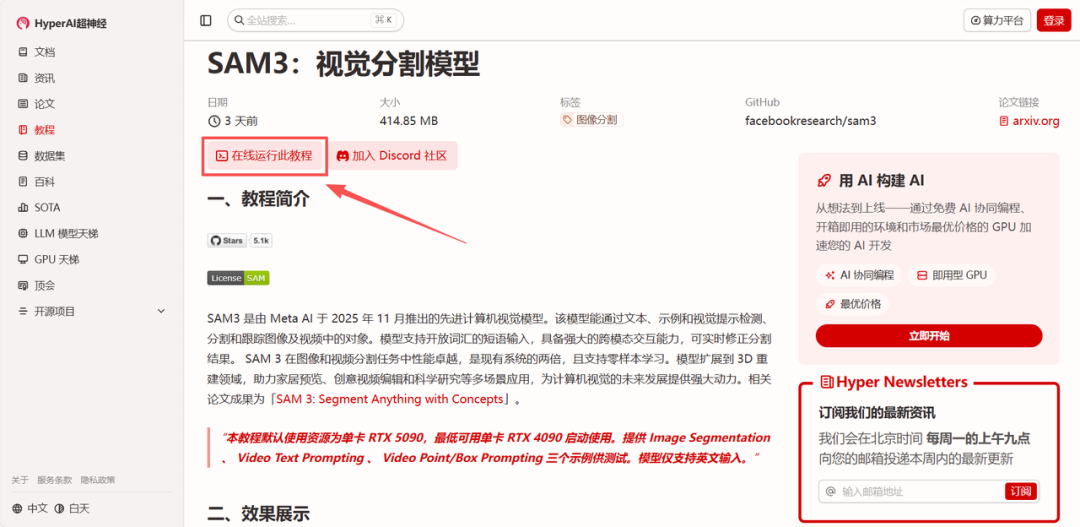
-
克隆项目:页面跳转后,点击右上角「Clone」按钮,将该教程克隆至自己的容器中。
注:页面右上角支持切换语言,目前提供中文及英文两种语言,本教程步骤以英文界面为例。
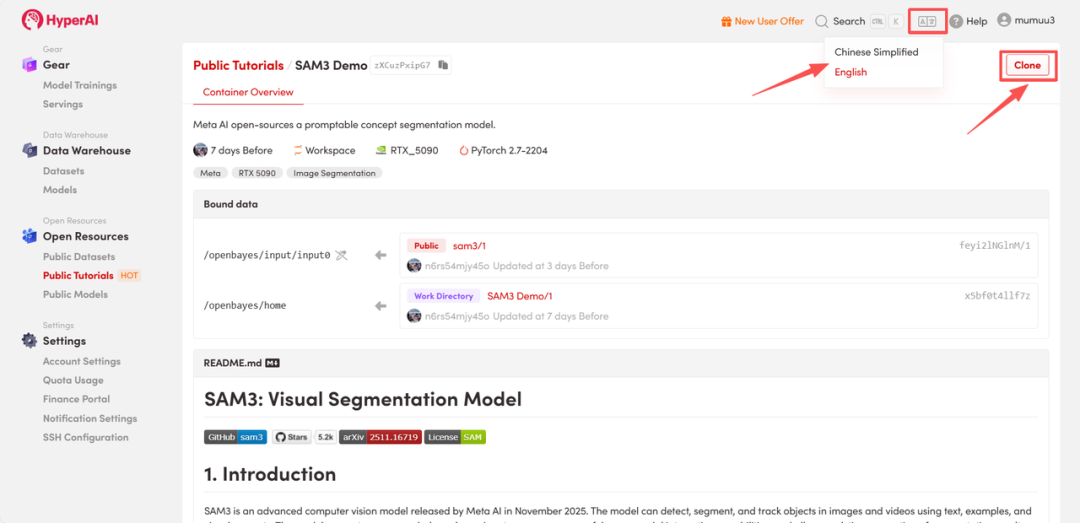
-
配置环境:选择「NVIDIA GeForce RTX 5090」显卡以及「PyTorch」镜像,根据需求选择「Pay As You Go(按量付费)」或包日/周/月计划,点击「Continue job execution(继续执行)」。

HyperAI 为新用户提供注册福利,仅需 $1 即可获得 5 小时 RTX 5090 算力(原价$2.45),资源永久有效。
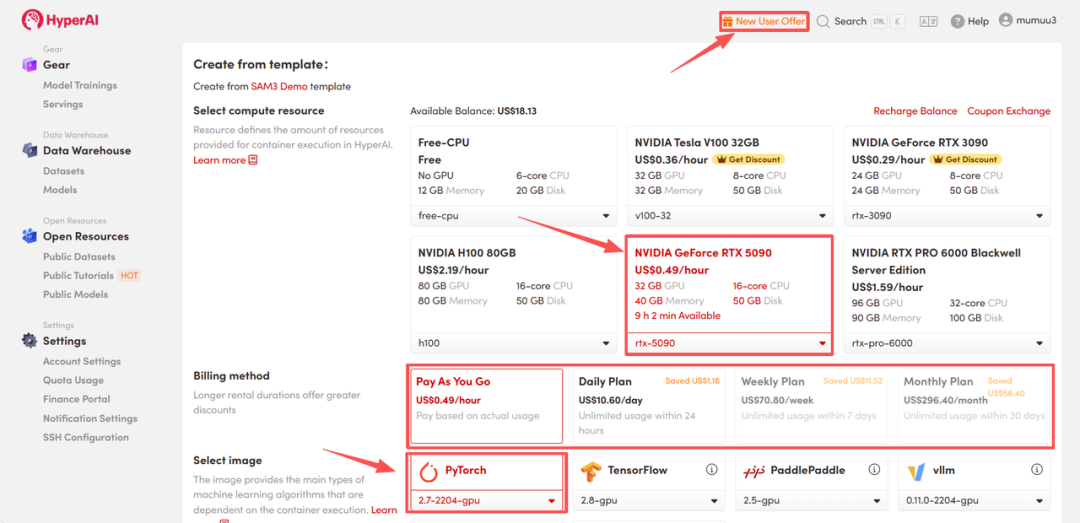
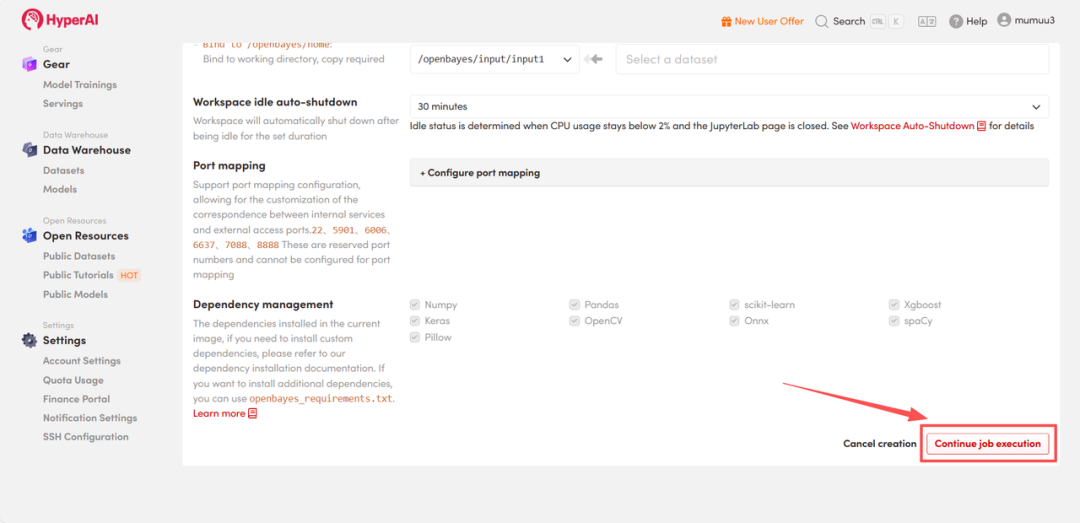
-
启动Demo:等待资源分配,首次克隆通常需要约 3 分钟。当容器状态变为「Running(运行中)」后,点击「API address」旁的跳转箭头,即可进入 Demo 交互页面。这种在云端快速配置并运行复杂人工智能模型的方式,极大地提升了开发与实验效率。
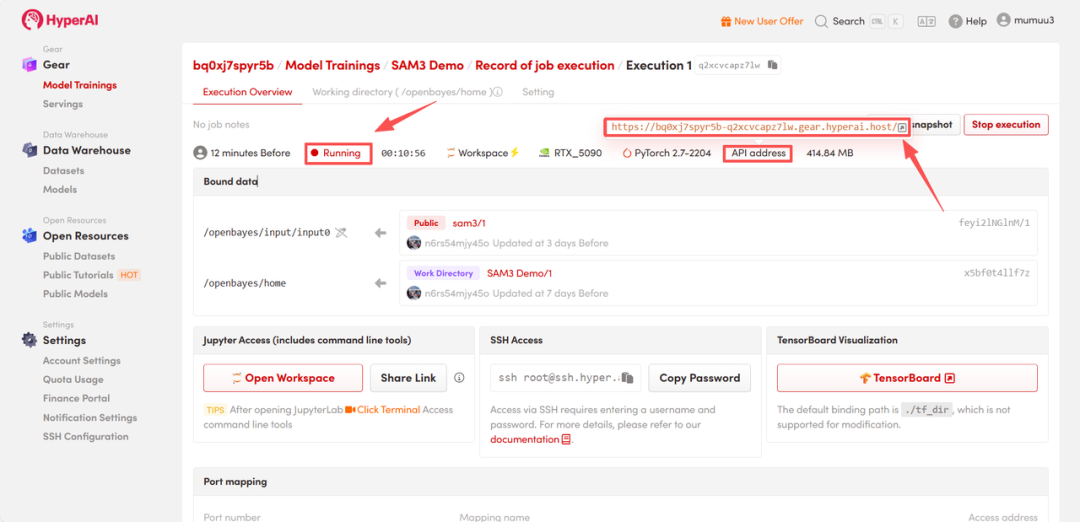
效果演示
Demo 页面提供了 Image Segmentation、Video Text Prompting、Video Point/Box Prompting 三大功能模块,目前仅支持英文输入。以下以 Video Text Prompting(视频文本提示)功能为例进行演示。
上传测试视频后,在「Text Prompt(s)」输入框中填入需要识别分割的名词短语,依次点击「Apply Text Prompt(s)」、「Propagate across video」以应用提示词并跨帧传播,最后点击「Render MP4 for smooth playback」即可生成目标被高亮识别的结果视频。这个过程涉及复杂的视频帧数据处理与模型推理。

以下是使用《疯狂动物城2》预告片片段进行测试的效果展示:
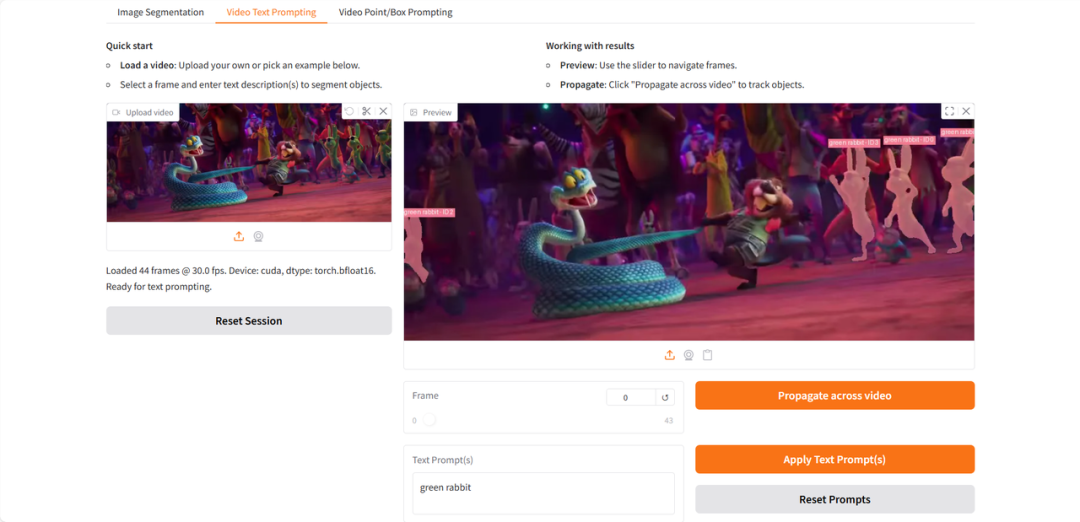 (视频内容:展示了SAM 3在视频片段中成功分割并跟踪指定角色)
(视频内容:展示了SAM 3在视频片段中成功分割并跟踪指定角色)
通过上述教程,您可以快速体验 SAM 3 在可提示概念分割方面的强大能力。 |  发表于 2025-12-11 05:31:51
|
查看: 247|
回复: 0
发表于 2025-12-11 05:31:51
|
查看: 247|
回复: 0
