对单库单表的MySQL数据进行搜索、全文检索、模糊匹配效率和性能都很差,对多库多表的数据进行搜索则更为复杂。因此,通常会采用Canal监听MySQL的binlog,并结合ElasticSearch(以下简称ES)建立索引的方案来实现高效搜索。
对于中小型项目的ES需求,基本由“自动补全、拼音纠错、全文检索、结构化搜索”等功能即可满足。
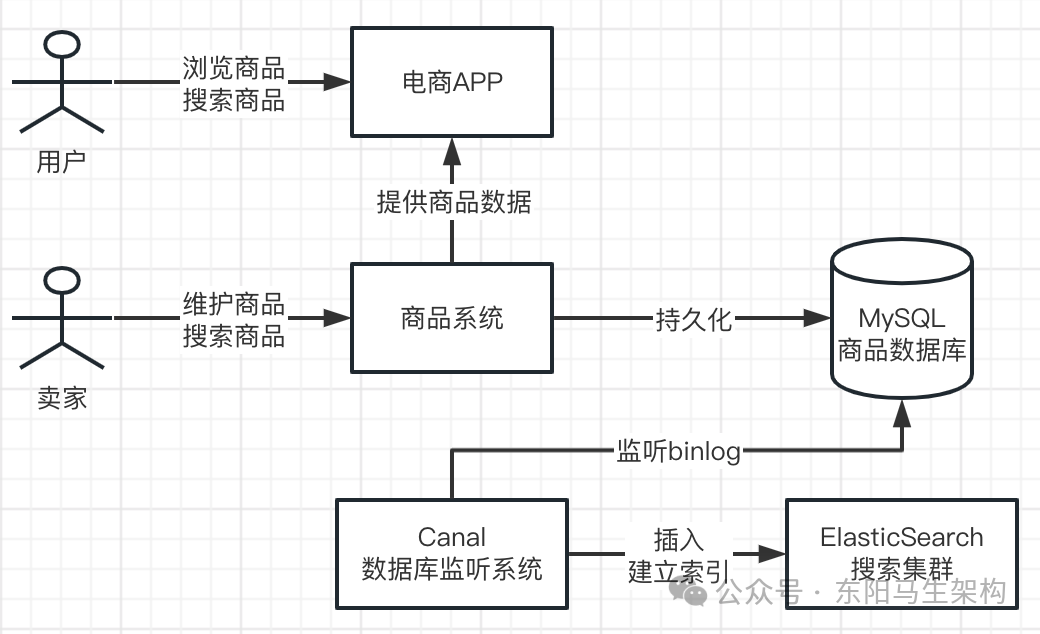
基于ES的商品B端搜索系统架构设计
当MySQL执行插入操作时,会产生对应的insert类型binlog日志。这些日志会被Canal系统监听并捕获,随后Canal会以HTTP方式调用商品B端搜索系统的指定接口。搜索系统则根据这条binlog日志对应的数据,提取出需要进行搜索的字段。
商品数据中可能需要搜索的字段包括:title(标题)、description(描述)、category(分类)等。搜索系统会将这些字段以及商品ID写入到Elasticsearch中,ES随即根据这些内容建立倒排索引。
当后续MySQL对这些商品数据进行修改时,会产生update类型的binlog日志。同样地,Canal会监听到这些变更,并通过搜索系统,依据修改后的内容更新Elasticsearch中的索引。
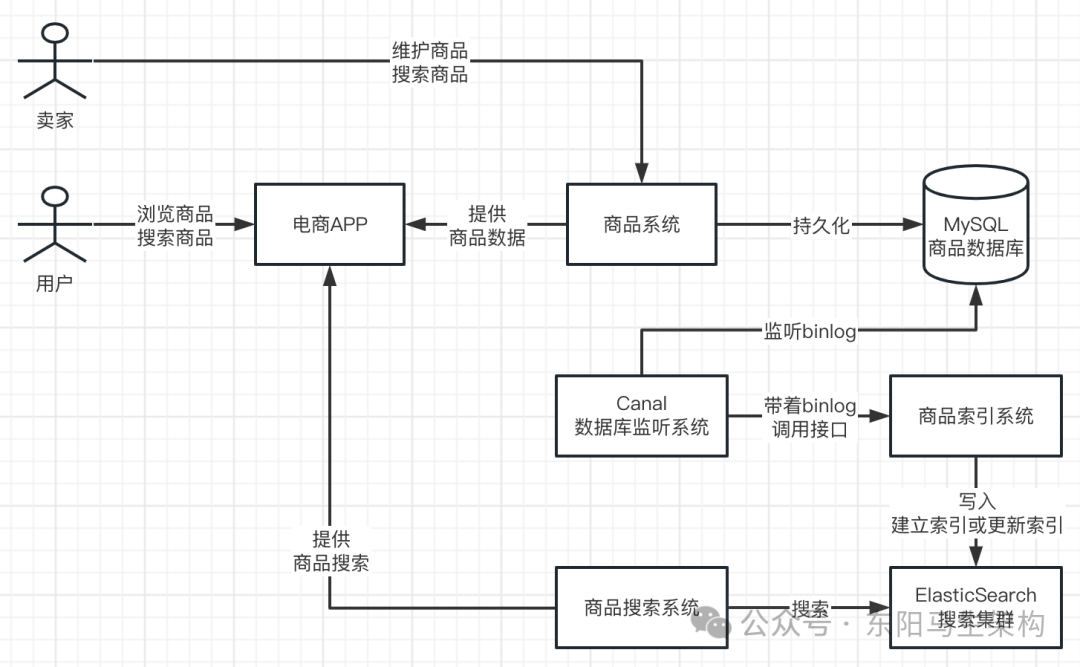
商品B端搜索系统实现步骤介绍
分词器的重要性
在ES中建立索引时,依赖于文本内容类型的字段。对于中文字段,必须使用中文分词器进行分词处理。因此,在落地搜索系统时,实现一个高效、可维护的中文分词器是至关重要且必须完成的基础工作。
实现关键步骤
- 步骤一:搭建和部署一套ES生产集群。
- 步骤二:为ES集群各节点安装部署自行开发改造的中文分词器。
- 步骤三:分析商品数据模型,设计ES中的索引数据结构。这包括创建商品核心索引、设计索引结构(索引中的指定字段必须使用我们的分词器),以及用于辅助用户实现搜索提示和自动纠错的suggest索引。
- 步骤四:实现数据写入ES建立索引的接口,以及基于ES索引进行搜索的接口。搜索功能需支持输入框的自动补全、自动纠错、自动推荐。搜索接口分为全文检索(根据关键词搜索)和结构化搜索(根据品牌、销售属性、颜色等固定字段条件搜索)。
- 步骤五:进行ES写入性能测试与优化、搜索接口的性能测试与优化。重点测试大量数据瞬时高并发写入的性能,以及海量数据搜索时的性能。
步骤一:ES生产集群部署
经典的ES生产集群配置通常采用:3个ES节点(8核16G配置)搭配1个用于可视化监控的Kibana节点(2核4G)。

ES生产集群部署不推荐使用低配置机器,而是选择配置较高的机器以承受亿级数据量下的高并发写入和搜索测试。本例使用了3台阿里云标准的8核16G机器部署ES生产集群。测试阶段硬盘容量几十GB即可满足需求,1亿数据量大约需要40GB磁盘空间。
通常,部署MySQL、RocketMQ、Redis、ES等中间件会使用8核16G或更高配置的机器,而普通业务系统可使用4核8G甚至2核4G的机器。
OS内核参数优化
需要对系统的进程数、文件句柄数和虚拟内存映射数进行调整。
# 编辑 limits.conf 文件
$ vi /etc/security/limits.conf
# 添加以下内容
* soft nofile 65535
* hard nofile 65535
* soft nproc 4096
* hard nproc 4096
# 退出当前用户重新登录后生效
# 编辑 sysctl.conf 文件
$ vi /etc/sysctl.conf
# 添加以下内容
vm.max_map_count=262144
# 使配置生效
$ sysctl -p
ES生产集群三节点配置
一、配置 elasticsearch.yml 文件
需要开启对ES节点的监控,以便后续将监控数据传输给ELK中的Kibana进行展示。
# 集群名称
cluster.name: escluster
# 节点名称
node.name: esnode1
# 节点角色
node.master: true
node.data: true
# 最大的节点数
node.max_local_storage_nodes: 3
# 绑定的ip地址
network.host: 0.0.0.0
# 对外的端口
http.port: 9300
# 节点之间通信的端口
transport.tcp.port: 9800
# 节点发现和集群选举
discovery.seed_hosts: ["172.19.16.132:9800","172.19.16.133:9800","172.19.16.134:9800"]
cluster.initial_master_nodes: ["esnode1", "esnode2","esnode3"]
# 数据目录和日志目录
path.data: /app/elasticsearch/data
path.logs: /app/elasticsearch/log
# 开启监控,以便Kibana收集堆栈监控数据
xpack.monitoring.enabled: true
xpack.monitoring.collection.enabled: true
二、配置 jvm.options 文件
JVM配置至关重要。通常将机器一半的内存分配给JVM,另一半留给OS Cache,这样可以让ES索引文件的数据尽可能多地驻留在OS Cache内存中,提升搜索性能(机器16G内存,分配8G给JVM,8G给OS Cache)。
-Xms8g
-Xmx8g
Kibana监控部署
部署Kibana的机器只需低配(2核4G即可),因其仅用于数据展示。Kibana同样以JVM进程方式运行。修改kibana.yml配置文件:
# kibana的端口
server.port: 9000
# 绑定的地址
server.host: "0.0.0.0"
# es的地址
elasticsearch.hosts: ["http://106.14.80.207:9300", "http://139.196.198.62:9300", "http://139.196.231.156:9300"]
# 显示的语言
i18n.locale: "zh-CN"
步骤二:IK分词器改造和部署
IK分词器词库热刷新机制介绍
原生开源的IK分词器通常难以直接满足生产需求,一般需要基于其源码进行二次开发和改造。
中文分词首先依赖于中文词库。例如,对“我特别喜欢在床上看书”进行分词,若词库中有“特别”、“喜欢”、“看书”,则分词结果为:我、特别、喜欢、在、床、上、看书。若词库中增加“床上”一词,则可将“床上”作为一个整体分出。
因此,使用IK分词器时,通常需要从数据库加载定义好的中文词库进行初始化,并开启一个后台线程定时从数据库加载最新的词库。这样,当我们需要更新词库时,可以在Web界面手工录入新词至数据库,或通过专门的词汇系统从外部网络环境自动爬取录入。
改造后的IK分词器代码会嵌入到ES的JVM进程中运行,从而能够不断热加载数据库里的最新词汇,实现线上ES搜索集群的词库热刷新。IK分词器本身是一个Java代码包,启动时会内嵌一个基础中文词库。此外,还有停用词词库(stop words),用于在分词时忽略无意义的词汇。

IK分词器源码改造流程步骤
- 在IK分词器源码的
pom.xml中添加MySQL依赖。
- 添加一个
DictLoader类,用于加载MySQL中的词库内容。
- 将
Dictionary类的私有方法getDictRoot()改为public,以便在DictLoader中调用。
- 在
Dictionary类中添加一个addStopWords方法。
- 在
Dictionary类的initial()方法中开启一个加载词库的线程。
- 重新打包IK分词器源码。
IK分词器定时加载词库实现
读取配置文件的最佳实践是:先获取配置文件的全路径名,根据全路径名构建输入流,加载到Java的Properties配置对象中,最后从该对象获取配置值。
打包后的IK分词器部署到各ES节点后,其代码会随ES JVM进程启动而运行,从而能够定时从MySQL中热刷新词库和停用词。
以下是DictLoader类的核心代码片段,展示了如何从MySQL加载扩展词:
public class DictLoader {
private static final DictLoader INSTANCE = new DictLoader();
private final String url;
private final String username;
private final String password;
private final AtomicBoolean extensionWordFistLoad = new AtomicBoolean(false);
private final AtomicReference<String> extensionWordLastLoadTimeRef = new AtomicReference<>(null);
// ... 停用词相关变量
private DictLoader() {
Properties mysqlConfig = new Properties();
Path configPath = PathUtils.get(Dictionary.getSingleton().getDictRoot(), "jdbc.properties");
try {
mysqlConfig.load(new FileInputStream(configPath.toFile()));
this.url = mysqlConfig.getProperty("jdbc.url");
this.username = mysqlConfig.getProperty("jdbc.username");
this.password = mysqlConfig.getProperty("jdbc.password");
} catch (IOException e) {
throw new IllegalStateException("加载jdbc.properties配置文件发生异常");
}
try {
Class.forName("com.mysql.cj.jdbc.Driver");
} catch (ClassNotFoundException e) {
throw new IllegalStateException("加载数据库驱动时发生异常");
}
}
public void loadMysqlExtensionWords() {
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
String sql;
// 首次加载查全量,后续按时间查增量
if (extensionWordFistLoad.compareAndSet(false, true)) {
sql = "SELECT word FROM extension_word";
} else {
sql = "SELECT word FROM extension_word WHERE update_time >= '" + extensionWordLastLoadTimeRef.get() + "'";
}
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String nowString = dateFormat.format(new Date());
extensionWordLastLoadTimeRef.set(nowString);
try {
connection = DriverManager.getConnection(url, username, password);
statement = connection.createStatement();
resultSet = statement.executeQuery(sql);
LOGGER.info("从MySQL加载extensionWord, sql={}", sql);
Set<String> extensionWords = new HashSet<>();
while (resultSet.next()) {
String word = resultSet.getString("word");
if (word != null) {
extensionWords.add(word);
LOGGER.info("从MySQL加载extensionWord, word={}", word);
}
}
// 将加载的词添加到字典中
Dictionary.getSingleton().addWords(extensionWords);
} catch (Exception e) {
LOGGER.error("从MySQL加载extensionWord发生异常", e);
} finally {
// 释放资源:resultSet, statement, connection
// ... (资源释放代码)
}
}
// ... loadMysqlStopWords() 方法类似
}
在ES生产集群中安装IK分词器
- 下载对应版本(如7.9.3)的
elasticsearch-analysis-ik发行版。
- 在ES节点机器的ES插件目录
plugins下创建ik目录。
- 将
elasticsearch-analysis-ik-7.9.3.zip上传至ik目录并解压。
- 用自行打包的
elasticsearch-analysis-ik-7.9.3.jar替换解压得到的同名jar包。
- 将
mysql-connector-java-8.0.20.jar驱动包也上传到ik目录。
- 在
ik/config目录中添加jdbc.properties配置文件(包含数据库连接信息)。
完成一个节点的安装后,重启ES集群的所有节点:
$ ps -ef | grep elasticsearch
$ kill 2989 # 替换为实际的ES进程ID
$ echo '' > /app/elasticsearch/log/escluster.log # 清空日志(可选)
$ /app/elasticsearch/elasticsearch-7.9.3/bin/elasticsearch -d
$ tail -f /app/elasticsearch/log/escluster.log
在ES生产集群中安装拼音分词器
拼音分词器与IK分词器配合使用,可实现更好的中文搜索体验(例如用户输入拼音也能返回对应结果)。
- 下载对应版本(如7.9.3)的
elasticsearch-analysis-pinyin发行版。
- 在ES节点机器的ES插件目录
plugins下创建pinyin目录。
- 将
elasticsearch-analysis-pinyin-7.9.3.zip上传至pinyin目录并解压。
- 重启ES集群的各个节点。
步骤三:为商品数据设计和创建索引
索引包括:商品核心索引 + suggest索引。
商品核心数据模型分析
商品数据中用于搜索的核心字段如下:
- skuName(商品名称):字符串类型,需要进行全文检索。
- skuId(商品ID):通常为long类型数字。
- category(商品分类):字符串类型,进行精准匹配,而非全文检索。
- basePrice(商品价格) / vipPrice(会员价格) / saleCount(销量) / commentCount(评论数):均为数字类型字段。
- skuImgUrl(商品图片URL):图片地址,不进行搜索和索引。
- createTime / updateTime(创建/修改时间):时间类型字段。
生产项目中的搜索分词器方案
一、IK分词器的算法类型
- ik_max_word:细粒度分词,尽可能多地拆分词汇,使其可匹配的搜索词尽可能多。
- ik_smart:粗粒度分词,尽可能精准地拆分词汇,使其可匹配的搜索词尽可能少但精准。
二、IK分词器的算法使用方案
生产中,会根据不同场景使用这两种分词算法:
- 场景一(写入数据):使用
ik_max_word建立索引,产生精细化的词汇,为后续搜索词匹配提供更多选择。
- 场景二(搜索字段):对用户输入的搜索词使用
ik_smart进行分词,以实现更精准的匹配。
具体实现体现在索引映射(mapping)中:
"skuName": {
"type": "text",
"analyzer": "ik_max_word", // 写入时使用
"search_analyzer": "ik_smart" // 搜索时使用
}
商品和suggest索引的设计与创建
一、创建商品索引的mappings
索引名示例:demo_plan_sku_index_15(序号用于区分不同测试索引)。设置分片数为3(参考3节点集群),副本数为1。
PUT /demo_plan_sku_index_15
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"skuId": { "type": "keyword" },
"skuName": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"category": { "type": "keyword" },
"basePrice": { "type": "integer" },
"vipPrice": { "type": "integer" },
"saleCount": { "type": "integer" },
"commentCount": { "type": "integer" },
"skuImgUrl": { "type": "keyword", "index": false },
"createTime": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss" },
"updateTime": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss" }
}
}
}
skuName字段用于全文检索;分类、价格、销量、评论数、时间等字段用于结构化搜索(即根据固定条件进行搜索,如指定分类、价格范围等)。
二、创建suggest索引
suggest索引用于实现用户输入的自动补全、拼写纠错以及搜索结果为空时的推荐。它包含两个字段:word1用于自动补全(使用completion类型),word2用于拼写纠错和搜索推荐(使用text类型)。
在创建索引时,我们自定义了一个分析器ik_and_pinyin_analyzer,它同时使用了IK分词器和拼音分词器,使得用户输入汉字或拼音都能进行自动补全。
PUT /demo_plan_sku_suggest_15
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"ik_and_pinyin_analyzer": {
"type": "custom",
"tokenizer": "ik_smart",
"filter": "my_pinyin"
}
},
"filter": {
"my_pinyin": {
"type": "pinyin",
"keep_first_letter": true,
"keep_full_pinyin": true,
"keep_original": true,
"remove_duplicated_term": true
}
}
}
},
"mappings": {
"properties": {
"word1": {
"type": "completion",
"analyzer": "ik_and_pinyin_analyzer"
},
"word2": { "type": "text" }
}
}
}
步骤四:为商品数据生成索引
模拟数据写入简介
通过MockDataController接口触发模拟数据写入。该接口会先从文件中加载10万条商品数据到内存,然后基于ES的API进行批量写入。
单线程模式Bulk批量写入
此方法主要用于与后续多线程写入进行性能对比。核心流程是:计算批次->遍历每个批次构建BulkRequest->通过RestHighLevelClient执行写入。
@PostMapping("/mockData1")
public JsonResult mockData1(@RequestBody MockData1Dto request) throws IOException {
// ... 参数校验
List<Map<String, Object>> skuList = loadSkusFromTxt(); // 加载10万数据
long startTime = System.currentTimeMillis();
for (int i = 0; i < batchTimes; i++) {
BulkRequest bulkRequest = buildSkuBulkRequest(indexName, batchSize, skuList);
restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT); // 单线程写入
}
long endTime = System.currentTimeMillis();
// ... 统计耗时和性能
}
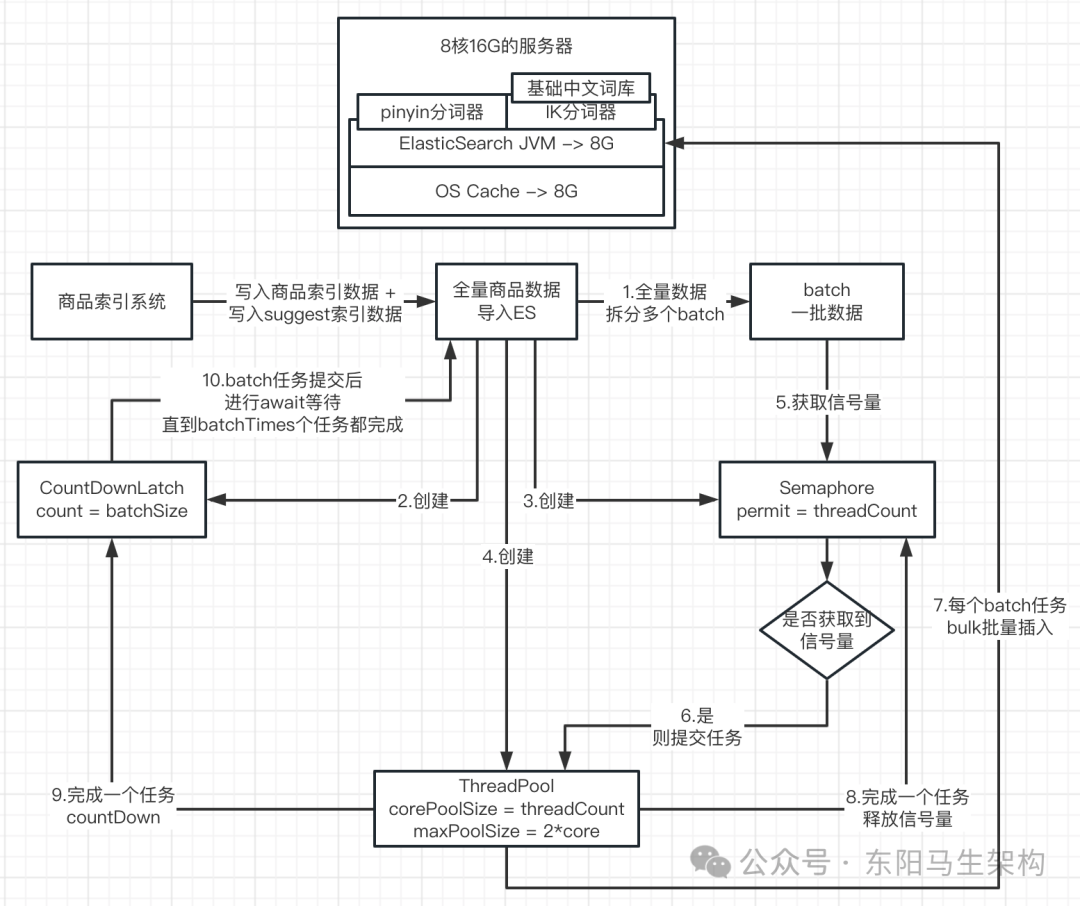
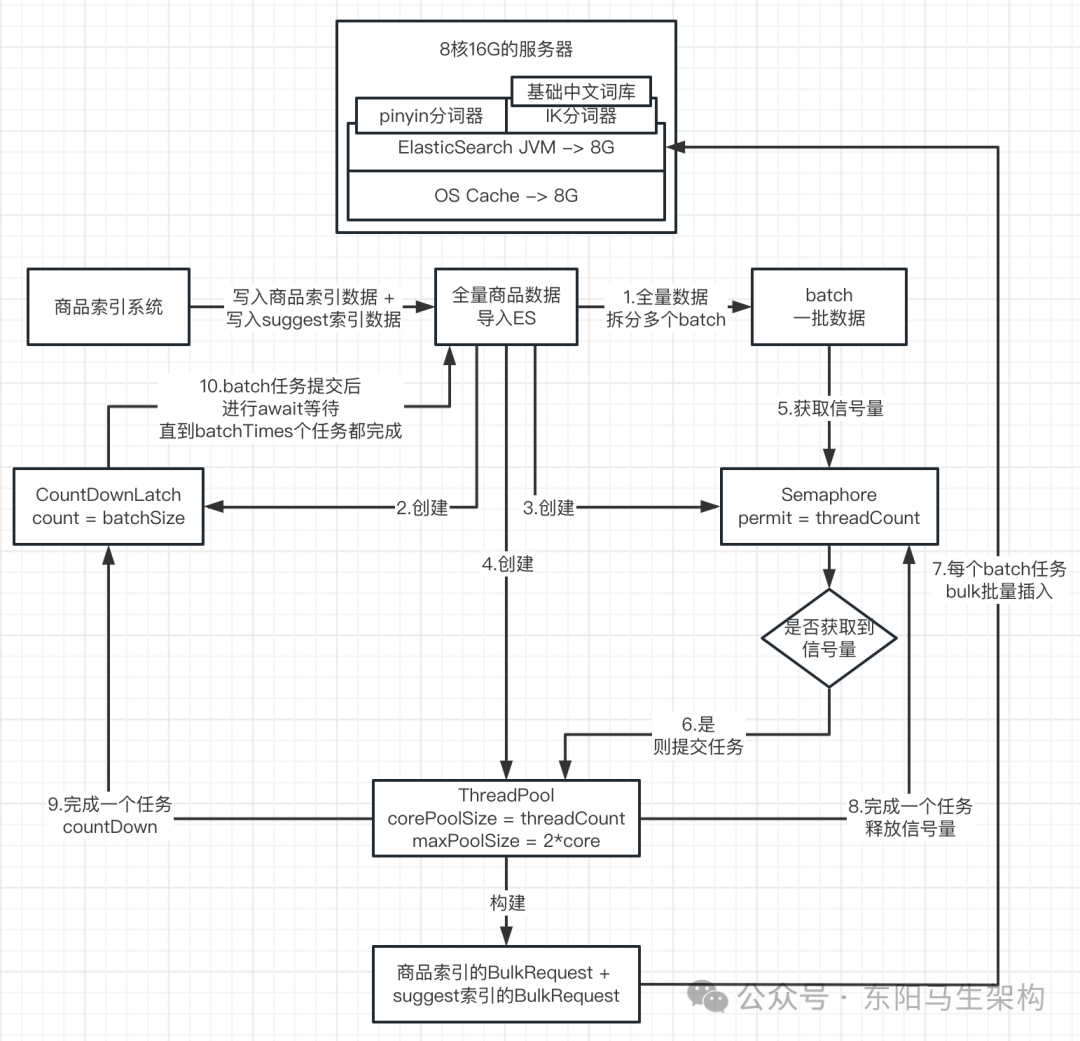
多线程并发大批量写入
这是生产环境更常用的方式。核心思想是:将批量写入任务提交到线程池并发执行,使用CountDownLatch等待所有任务完成,使用Semaphore控制同时执行的最大任务数。
@PostMapping("/mockData2")
public JsonResult mockData2(@RequestBody MockData2Dto request) throws IOException, InterruptedException {
// ... 参数校验和数据加载
CountDownLatch countDownLatch = new CountDownLatch(batchTimes);
Semaphore semaphore = new Semaphore(threadCount);
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
threadCount, threadCount * 2, 60, TimeUnit.SECONDS, new SynchronousQueue<>()
);
for (int i = 0; i < batchTimes; i++) {
semaphore.acquireUninterruptibly(); // 控制并发数
threadPoolExecutor.submit(() -> {
try {
BulkRequest bulkRequest = buildSkuBulkRequest(indexName, batchSize, skuList);
restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
} finally {
semaphore.release();
countDownLatch.countDown();
}
});
}
countDownLatch.await(); // 等待所有任务完成
threadPoolExecutor.shutdown();
// ... 统计耗时和性能
}
代码执行流程示意图:
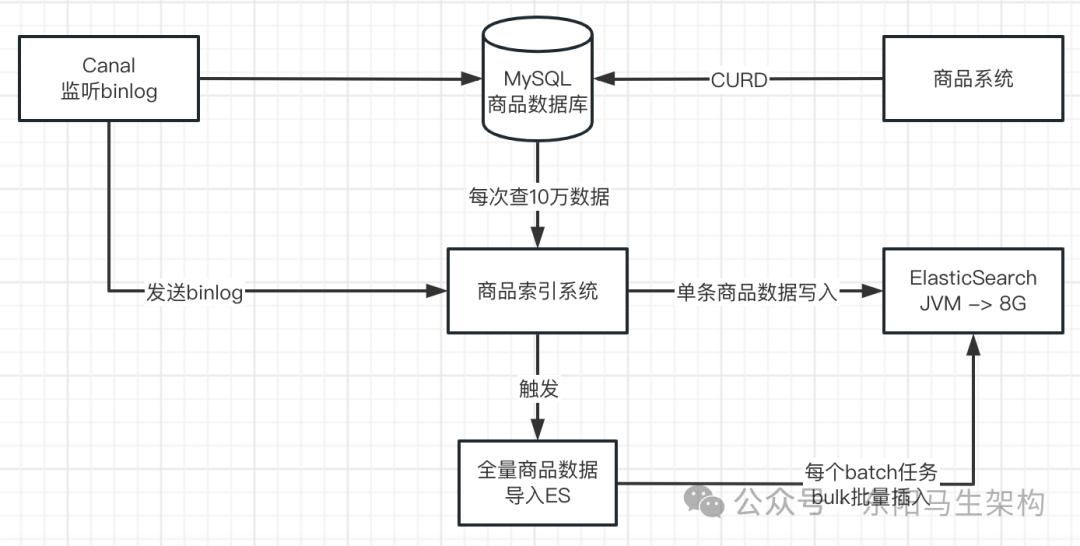
全量与增量商品数据导入ES生产方案
全量导入(如1000万数据):
- 分批次查询:每次从数据库查询10万条(约几十MB),共100次。
- 分Bulk写入:将每批10万条数据拆分为多个Bulk请求(遵循ES官方建议,每个Bulk不超过15MB,例如10MB)。
- 并发控制:使用线程池(如5个线程)并发执行这些Bulk写入任务。
增量导入:通过Canal监听MySQL的binlog,实时捕获增删改操作。商品索引系统提取binlog中的相关字段,构建单个BulkRequest并写入ES。
双索引(商品+suggest)同步写入实现
在生产代码中,每个写入线程可以同时构建商品索引和suggest索引的BulkRequest,并一次性提交。
 关键代码片段:
关键代码片段:
private BulkRequest buildProductIndexBulkRequest(List<Map<String, Object>> bulkList) {
BulkRequest bulkRequest = new BulkRequest("product_index");
for (Map<String, Object> productDataMap : bulkList) {
// ... 构建IndexRequest
bulkRequest.add(indexRequest);
}
return bulkRequest;
}
private BulkRequest buildSuggestIndexBulkRequest(List<String> skuNameBulkList) {
BulkRequest bulkRequest = new BulkRequest("suggest_index");
for (String skuName : skuNameBulkList) {
IndexRequest indexRequest = new IndexRequest().source(XContentType.JSON, "word1", skuName, "word2", skuName);
bulkRequest.add(indexRequest);
}
return bulkRequest;
}
步骤四:基于索引实现搜索功能
基于suggest索引的自动补全实现
原理:将搜索词与suggest索引word1字段(使用IK+拼音分析器)的倒排索引中的词条前缀进行匹配和评分,返回分数最高的建议词。
@Service
public class CommonSearchServiceImpl implements CommonSearchService {
@Autowired
private RestHighLevelClient restHighLevelClient;
@Override
public List<String> autoComplete(AutoCompleteRequest request) throws IOException {
// 1. 构建CompletionSuggestion条件
CompletionSuggestionBuilder suggestionBuilder = SuggestBuilders.completionSuggestion(request.getFieldName())
.prefix(request.getText()).skipDuplicates(true).size(request.getCount());
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().suggest(new SuggestBuilder().addSuggestion("my_suggest", suggestionBuilder));
// 2. 封装并执行搜索请求
SearchRequest searchRequest = new SearchRequest(request.getIndexName()).source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 3. 解析结果
CompletionSuggestion suggestion = response.getSuggest().getSuggestion("my_suggest");
List<String> result = new ArrayList<>();
for (CompletionSuggestion.Entry.Option option : suggestion.getEntries().get(0).getOptions()) {
result.add(option.getText().string());
}
return result;
}
}
输入框中的拼写纠错实现
原理:对输入的有拼写错误的搜索词进行自动纠错,然后与suggest索引word2字段进行匹配,返回最可能的正确词汇。
@Override
public String spellingCorrection(SpellingCorrectionRequest request) throws IOException {
// 1. 构建PhraseSuggestion条件
PhraseSuggestionBuilder phraseSuggestionBuilder = new PhraseSuggestionBuilder(request.getFieldName())
.text(request.getText()).size(1);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().suggest(new SuggestBuilder().addSuggestion("my_suggest", phraseSuggestionBuilder));
// 2. 封装并执行搜索请求
SearchRequest searchRequest = new SearchRequest(request.getIndexName()).source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 3. 解析结果
PhraseSuggestion suggestion = response.getSuggest().getSuggestion("my_suggest");
List<PhraseSuggestion.Entry.Option> options = suggestion.getEntries().get(0).getOptions();
return Optional.ofNullable(options).filter(e -> !e.isEmpty()).map(e -> e.get(0).getText().string()).orElse("");
}
商品B端的商品搜索实现
搜索流程通常为:输入搜索词 -> 拼写纠错 -> 自动补全 -> 全文检索。
全文检索核心代码实现:
@Service
public class ProductServiceImpl implements ProductService {
@Autowired
private RestHighLevelClient restHighLevelClient;
@Override
public SearchResponse fullTextSearch(FullTextSearchRequest request) throws IOException {
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().trackTotalHits(true);
// 1. 构建match查询条件
request.getQueryTexts().forEach((field, text) -> {
sourceBuilder.query(QueryBuilders.matchQuery(field, text));
});
// 2. 设置高亮(可选,移动端可能不常用)
HighlightBuilder highlightBuilder = new HighlightBuilder().field(request.getHighLightField())
.preTags("<span style='color:red'>").postTags("</span>").numOfFragments(0);
sourceBuilder.highlighter(highlightBuilder);
// 3. 设置分页
int from = (request.getPageNum() - 1) * request.getPageSize();
sourceBuilder.from(from).size(request.getPageSize());
// 4. 封装并执行请求
SearchRequest searchRequest = new SearchRequest(request.getIndexName()).source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 5. 处理高亮结果
for (SearchHit hit : response.getHits()) {
HighlightField highlightField = hit.getHighlightFields().get(request.getHighLightField());
if (highlightField != null) {
StringBuilder builder = new StringBuilder();
for (Text fragment : highlightField.fragments()) {
builder.append(fragment.string());
}
hit.getSourceAsMap().put(request.getHighLightField(), builder.toString());
}
}
return response;
}
}
搜索结果为空时的自动推荐实现
当全文检索结果为空时,可调用此接口进行相似词推荐。流程扩展为:输入搜索词->纠错->补全->全文检索->自动推荐。
@Override
public String recommendWhenMissing(RecommendWhenMissingRequest request) throws IOException {
// 1. 构建TermSuggestion条件
TermSuggestionBuilder termSuggestionBuilder = new TermSuggestionBuilder(request.getFieldName())
.text(request.getText()).analyzer("ik_smart").minWordLength(2)
.stringDistance(TermSuggestionBuilder.StringDistanceImpl.NGRAM);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().suggest(new SuggestBuilder().addSuggestion("my_suggest", termSuggestionBuilder));
// 2. 封装并执行搜索请求
SearchRequest searchRequest = new SearchRequest(request.getIndexName()).source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 3. 解析结果
TermSuggestion suggestion = response.getSuggest().getSuggestion("my_suggest");
List<TermSuggestion.Entry.Option> options = suggestion.getEntries().get(0).getOptions();
return Optional.ofNullable(options).map(e -> e.get(0)).map(e -> e.getText().string()).orElse("");
}
基于多条件的商品结构化搜索
此接口通过接收前端拼接好的Query DSL(ES查询语法JSON)来执行高度灵活的搜索,支持各种过滤、排序组合。
@Override
public SearchResponse structuredSearch(StructuredSearchRequest request) throws IOException {
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().trackTotalHits(true);
// 1. 解析前端传入的Query DSL
String queryDsl = JSON.toJSONString(request.getQueryDsl());
SearchModule searchModule = new SearchModule(Settings.EMPTY, false, Collections.emptyList());
NamedXContentRegistry registry = new NamedXContentRegistry(searchModule.getNamedXContents());
XContentParser parser = XContentFactory.xContent(XContentType.JSON).createParser(registry, LoggingDeprecationHandler.INSTANCE, queryDsl);
sourceBuilder.parseXContent(parser); // 将DSL解析为查询条件
// 2. 设置分页
int from = (request.getPageNum() - 1) * request.getPageSize();
sourceBuilder.from(from).size(request.getPageSize());
// 3. 封装并执行请求
SearchRequest searchRequest = new SearchRequest(request.getIndexName()).source(sourceBuilder);
return restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
}
步骤五:大数据量写入ES和搜索性能的调优
性能测试对比
单线程写入百万数据:测试写入demo_plan_sku_index_01索引,每次批量1000条,执行1000次。结果:耗时62秒,每秒写入约1.6万条,平均每个Bulk请求(1000条)耗时约60ms。
多线程写入百万数据:
- 使用30个线程:耗时11秒,每秒写入约9万条,每个线程每秒写入约3000条(约3个Bulk请求)。
- 使用60个线程:耗时10秒,每秒写入约10万条。
结论:多线程+Bulk写入可大幅提升写入性能(10秒完成百万级写入),但存在最佳线程数临界点,并非线程越多越好,过多线程会导致CPU上下文切换开销增大,反而可能降低单个线程的吞吐量。
数据写入ES的存储原理与性能影响因素
写入流程简析:数据先写入JVM的index buffer -> 定时(默认1秒)refresh到OS Page Cache(此时可被搜索)-> 后续flush到磁盘文件。同时,为保证不丢失,数据会写入内存translog并定期(默认5秒)刷盘。
性能影响因素:
- refresh间隔:频繁refresh影响写入速度。
- 副本复制:复制过程影响写入速度。
- index buffer大小:缓冲区大小影响刷盘频率。
- translog刷盘策略:同步刷盘影响延迟。
全量数据写入ES的性能调优方案
以下优化主要针对全量数据导入场景,导入完成后应恢复原配置。
- 调整
refresh_interval(可动态配置):全量写入对“写入后立即可搜”要求不高,可调大至120秒,减少频繁refresh和Lucene段合并。
PUT /your_index/_settings
{
"index.refresh_interval": "120s"
}
- 调整
number_of_replicas(可动态配置):写入时先将副本数设为0,缩短写入链路;导入完成后再恢复。
PUT /your_index/_settings
{
"index.number_of_replicas": 0
}
- 调整
index_buffer_size(需重启):在elasticsearch.yml中调大JVM缓冲区,减少刷盘频率。
indices.memory.index_buffer_size: 30%
indices.memory.min_index_buffer_size: 128m
- 调整
translog参数(可动态配置):改为异步刷盘,并增大刷盘间隔和阈值。
PUT /your_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "120s",
"index.translog.flush_threshold_size": "2048mb"
}
调优效果:经过上述参数调优后,百万数据写入性能可提升一倍以上。
ES搜索性能测试与优化方案
性能测试结果:
- 全文搜索(如搜索“华为手机”):在上亿商品数据中,耗时通常在几百毫秒以内,性能优秀。
- 结构化搜索(如按分类+价格区间搜索并排序):首次查询可能较慢(几秒),因为涉及大量数据排序的磁盘IO;后续查询因数据已缓存,速度会加快。
搜索性能优化方案分析:
- 预留充足OS Cache内存:这是最关键的一点。确保机器内存足够大(如32G机器,16G给JVM,16G给OS Cache),并尽量控制每个节点上主分片的数据量与OS Cache内存量相当,使搜索尽可能在内存中进行,避免磁盘IO。
- 硬件选择:普通搜索瓶颈常在磁盘IO;计算密集型搜索(如复杂聚合)瓶颈可能在CPU。
- 预索引(Pre-Index):适用于数字字段和频繁的范围查询场景,例如将数字字段转为
keyword类型,把range查询转为terms查询。
- 字段类型优化:对没有范围查询需求的ID类字段,使用
keyword类型而非long类型。
- 合并只读索引:对不再写入的只读索引进行强制段合并(
forcemerge),减少搜索时需要打开的文件数量。
总结:ES在合理配置下性能已很出色。优化的核心在于利用大内存机器和合理的分片策略,让数据尽可能驻留在OS Cache中。遇到具体瓶颈时,再根据业务场景从上述方案中选择针对性优化点。
 发表于 2025-12-11 06:06:05
|
查看: 225|
回复: 0
发表于 2025-12-11 06:06:05
|
查看: 225|
回复: 0
