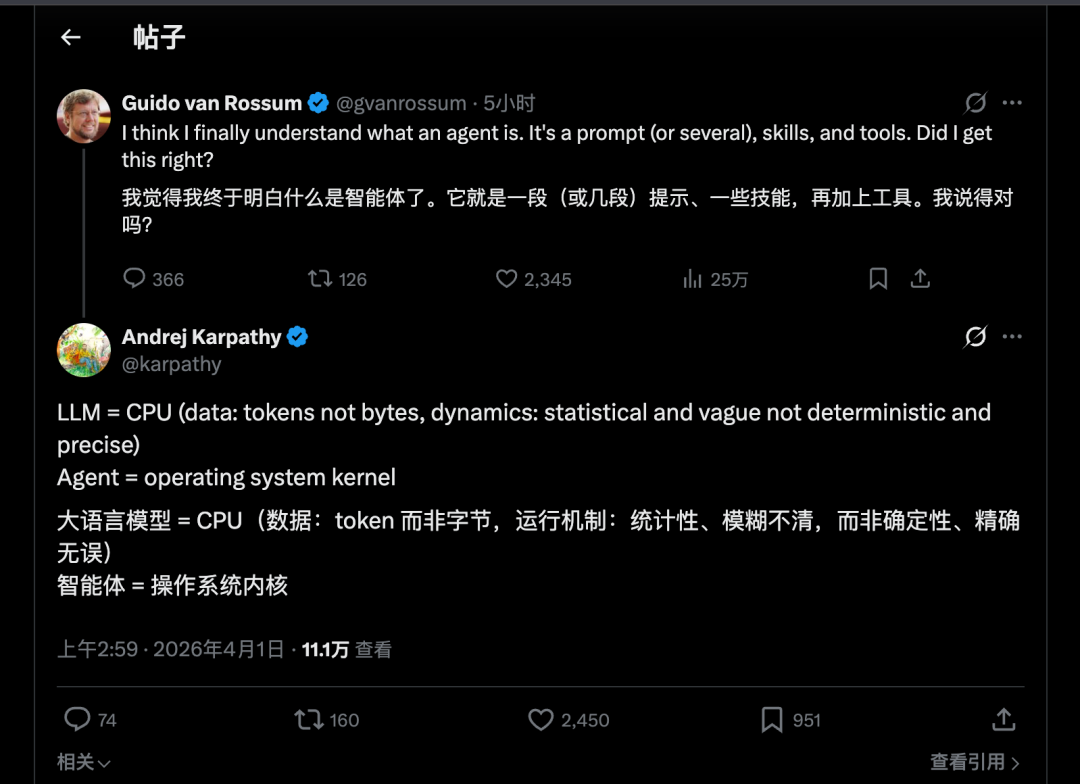
计算领域的基础单位正在经历一场深刻的变革。当Python之父Guido van Rossum在社交平台上探讨何为智能体时,Andrej Karpathy的回复不仅精辟,更指出了一个关键细节:LLM处理的数据单位不是字节,是token,并且其运行机制是统计性而非确定性的。
这并非简单的技术升级,而是一种底层计算的范式转移。
确定性字节 vs. 统计性Token
过去六十年,我们的数字世界坚实地构筑在“字节”之上。一个字符8个比特,精确、确定、绝不出错。你存入一个“1”,读取时必然得到“1”。整个互联网、所有软件与数据库,都依赖于这种绝对的确定性。
然而,大语言模型的到来打破了这一基石。它的基本单位是token——一个语义片段,可能是单词的一部分,也可能是一个完整的词。token是模糊的,同一个词在不同上下文中可能被拆分为不同数量的token。更重要的是,LLM的输出是概率性的,相同的输入运行两次,结果可能截然不同。
这仿佛是从经典牛顿力学踏入了量子力学的领域:精确让位于概率,确定让位于统计。
新计算架构的类比:LLM即CPU,Agent即OS内核
Karpathy将LLM比作CPU,将Agent比作操作系统内核,这个类比极具启发性。如果顺着这个思路推演:
- 传统计算机:CPU处理字节 → 内核调度进程 → 操作系统服务用户
- AI时代:LLM处理token → Agent编排任务 → AI OS服务用户
底层数据单位的改变,将引发上层建筑的全面重构。这意味着,为确定性字节世界设计的操作系统需要重写,运行其上的软件需要重做,甚至人与计算机的交互方式也需要重新设计。这并非迭代,而是一次彻底的轨道切换。
衡量标准的变迁:从DAU到TPM

在字节主导的时代,竞争优势往往体现为对数据(字节)的占有量。而在token主导的AI时代,核心竞争力则转向了对token的处理能力与效率。行业衡量标准也在悄然变化,从关注“日活跃用户数”转向关注“每分钟处理的token数”。
从BYTE ERA到TOKEN ERA,我们正站在一个新时代的起点。对于开发者而言,理解并适应这种从确定性到统计性的根本转变,是把握下一次技术浪潮的关键。如果你想深入探讨更多AI与基础计算的前沿话题,欢迎来云栈社区交流分享。 |  发表于 2026-4-9 05:34:08
|
查看: 140|
回复: 0
发表于 2026-4-9 05:34:08
|
查看: 140|
回复: 0
