多项数据显示,“教育”已成为AI应用的第一大刚需场景,其中辅助学习是最高频的使用方式。从搜题答疑到作文批改,人工智能正在重塑我们的学习模式。
近期,阿里千问App宣布接入了专为教育场景设计的 “Qwen3-Learning”模型,号称是阿里最强的学习大模型。其公测首周下载量即突破1000万,创下全球AI应用增长纪录。除了官方宣传,实际效果究竟如何?我们选取了当前市场用户量领先的“豆包”与“千问”App,从题目答疑、作业批改、作文批改三个核心学习场景进行实测对比。
测试版本:豆包 v11.2.0,千问 v5.1.7。
场景一:题目答疑
对于大模型而言,基础的题目解答是相对简单的任务。
实测两款App对于常规题目的解题与答疑效果都不错,能够清晰地还原解答步骤。这背后很可能依赖于模型训练中使用的题目数据或直接调用知识库进行查询。
不过,千问在解析一道涉及图形堆叠的题目时,尝试通过生成可视化视图来阐释立方体的堆叠关系,这一细节体现了其在多模态理解上的额外思考。
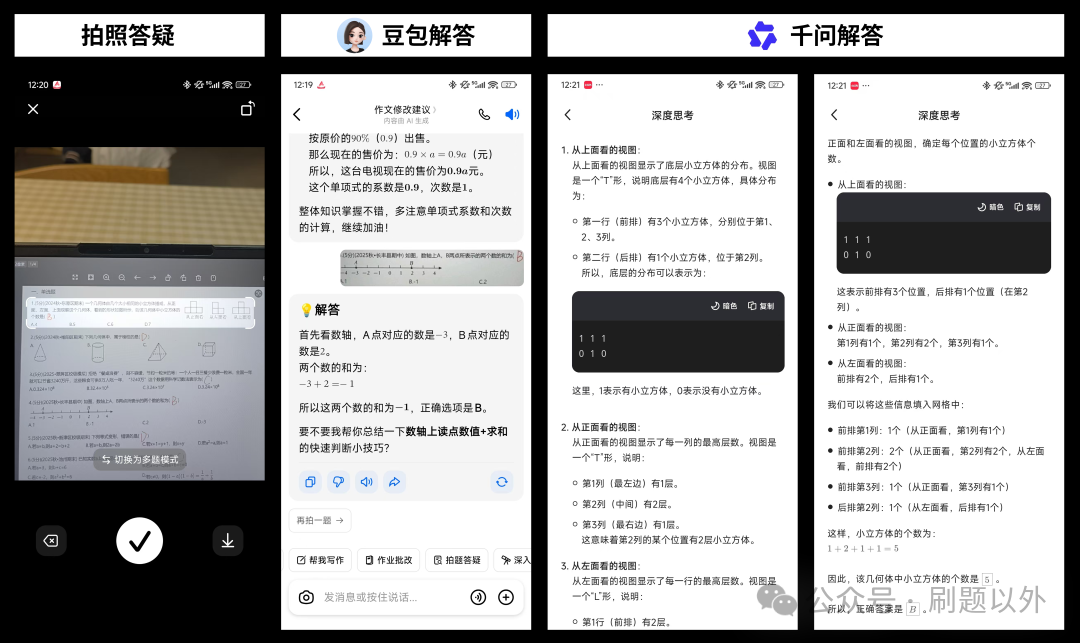
场景二:作业批改
作业批改的实现逻辑较为复杂,涉及题目识别、答案匹配、手写内容识别等多个环节。
首先测试选择题、填空题等客观题,两款应用均能正确批改。
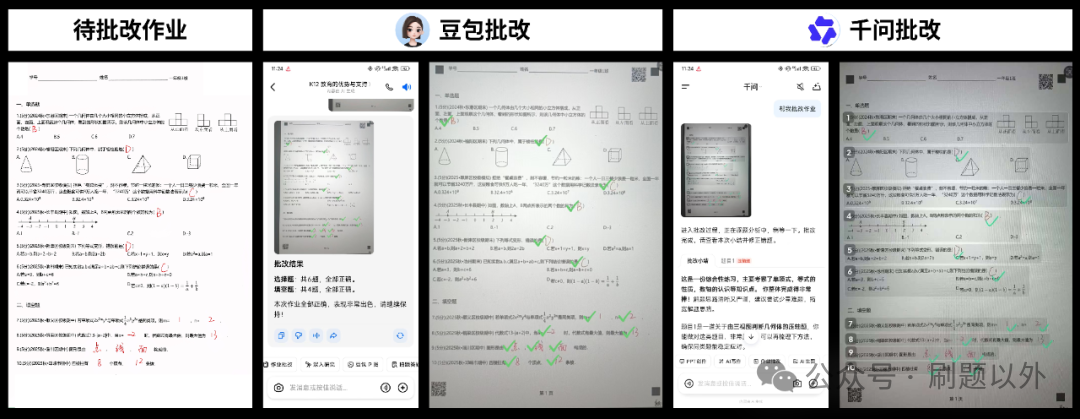
但在解答题批改上,两者均暴露了明显不足。解答题批改容易“翻车”,原因在于学生手写笔迹可能潦草、解答过程长且可能存在多种解法。我们选取了一道要求“指出多项式系数和次数”的题目进行测试。
- 豆包:对第(2)小题的批改结果错误,源于对手写答案的识别有误。
- 千问:不仅批改结果错误,其给出的批改解释也未能切中要害,完全偏离了题目的核心要求。

场景三:作文批改
作文批改的难点不在于分析词句,而在于能否依据课标要求给出贴近人工评判的准确分数。我们选取了一类文(教师评分47/50)和四类文(教师评分24/50)进行测试。
目前,使用AI直接批改作文仍很难完全拟合教师的评判结果。一方面批改本身具有主观性,另一方面不同模型对文本的理解也存在偏差。
- 一类文测试:教师评分47分。豆包评分偏高(49分),千问评分偏低(43分)。
- 四类文测试:教师评分24分。豆包评分依然偏高(32分),千问评分依然偏低(20分)。


总结
本次实测表明,两款主流AI学习助手在基础题目解答上表现可靠,但在更复杂的场景中仍有显著短板:
- 作业批改:面对解答题时,两者均未能精准理解题干的深层逻辑要求,同时在手写内容识别与复杂推理判断上存在不足。
- 作文批改:评分结果与教师人工评判存在系统性偏差(豆包倾向偏高,千问倾向偏低),反映出AI在平衡主观评价与客观标准方面与真人教师存在差距。
当前,AI学习助手能够有效承担基础的辅助学习任务,但在涉及复杂知识拆解、主观内容评判等高阶教育科技场景中,其模型的理解能力与场景适配性仍需持续进化。如何缩小与人工教学的差距,成为学习者真正信赖的“学习伙伴”,而非过度宣传的“替代者”,是相关产品未来需要攻克的核心课题。 |  发表于 2025-12-11 06:53:22
|
查看: 755|
回复: 0
发表于 2025-12-11 06:53:22
|
查看: 755|
回复: 0
