在追求极致效率和精度的计算机视觉领域,YOLO系列模型长期占据着实时目标检测的霸主地位。但最近,一个名为 RF-DETR 的新模型正在挑战这一格局。这款由Roboflow开源、基于Transformer架构的模型,凭借其出色的精度与速度平衡,在MS COCO等基准测试中表现亮眼,为工业质检、自动驾驶等对延迟敏感的应用提供了新的强大选项。

什么是 RF-DETR?
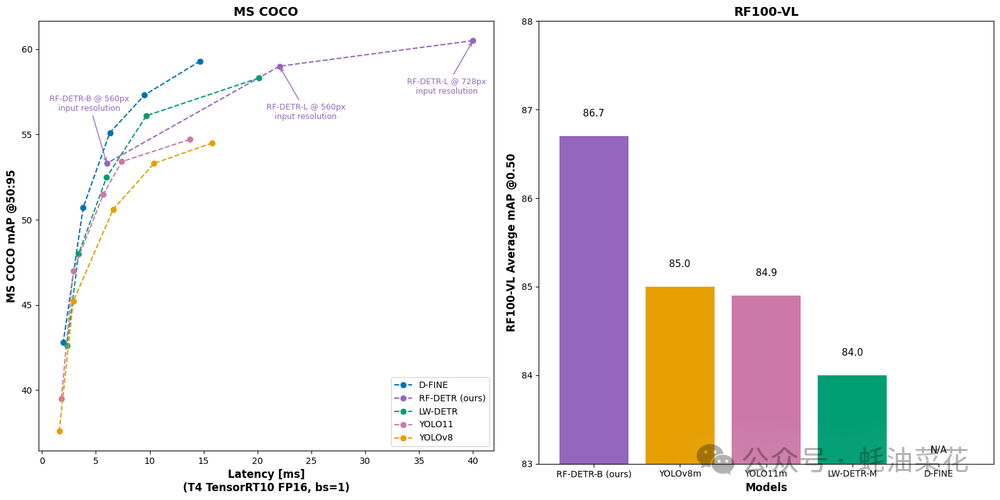
RF-DETR是Roboflow推出的新一代实时目标检测模型,属于DETR(Detection Transformer)家族。它首次在COCO数据集上实现了60+的平均精度均值(mAP),同时保持25帧/秒以上的实时性能,打破了传统CNN模型在精度与速度上的权衡困局。
该模型创新性地结合了轻量级Transformer架构与预训练的DINOv2视觉主干网络,通过单尺度特征提取和多分辨率训练策略,在工业检测、自动驾驶等高要求场景中展现出显著优势。开发者可直接使用其预训练检查点,快速适配自定义数据集。关于模型架构的更多深入分析,可以参考云栈社区的技术文档板块。
RF-DETR 的主要功能

- 高精度实时检测:在COCO数据集上达到60+ mAP,T4显卡推理延迟仅6ms。
- 领域自适应:通过DINOv2主干网络实现跨领域迁移,适用于航拍、工业等复杂场景。
- 动态分辨率:支持560-896px多分辨率切换,无需重训练即可调整精度/速度平衡。
- 便捷部署:提供PyTorch和ONNX格式模型,支持边缘设备部署。
RF-DETR 的技术原理
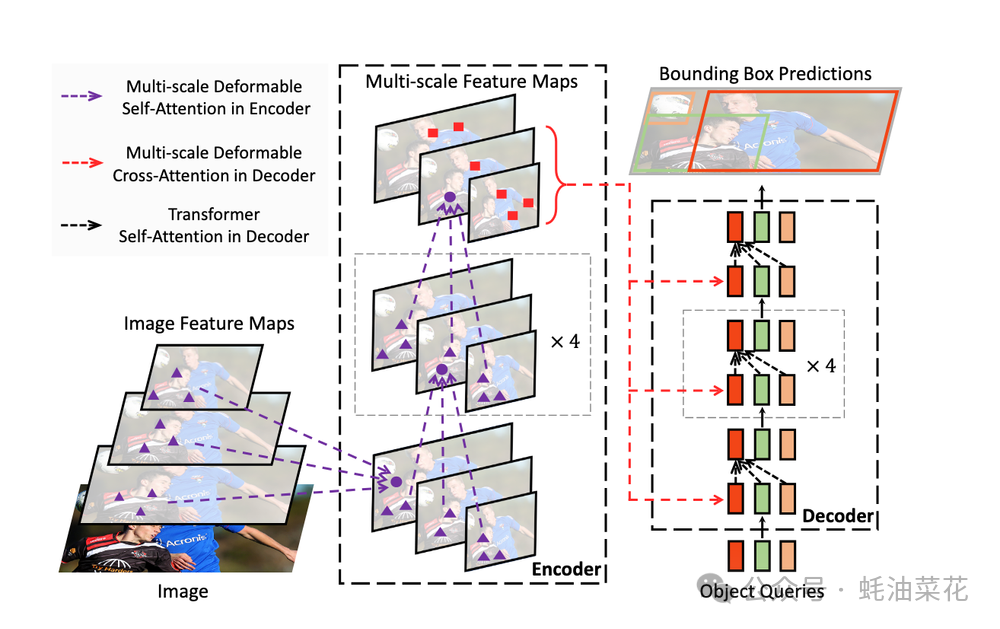
- Transformer架构:采用DETR的编码器-解码器结构,利用自注意力机制捕捉全局上下文。
- DINOv2主干网络:基于大规模自监督预训练的特征提取器,提升小样本适应能力。
- 单尺度优化:相比Deformable DETR的多尺度设计,简化特征图处理流程降低计算开销。
- 延迟优化:采用TensorRT加速,将NMS处理时间纳入总延迟评估体系。
快速体验 RF-DETR
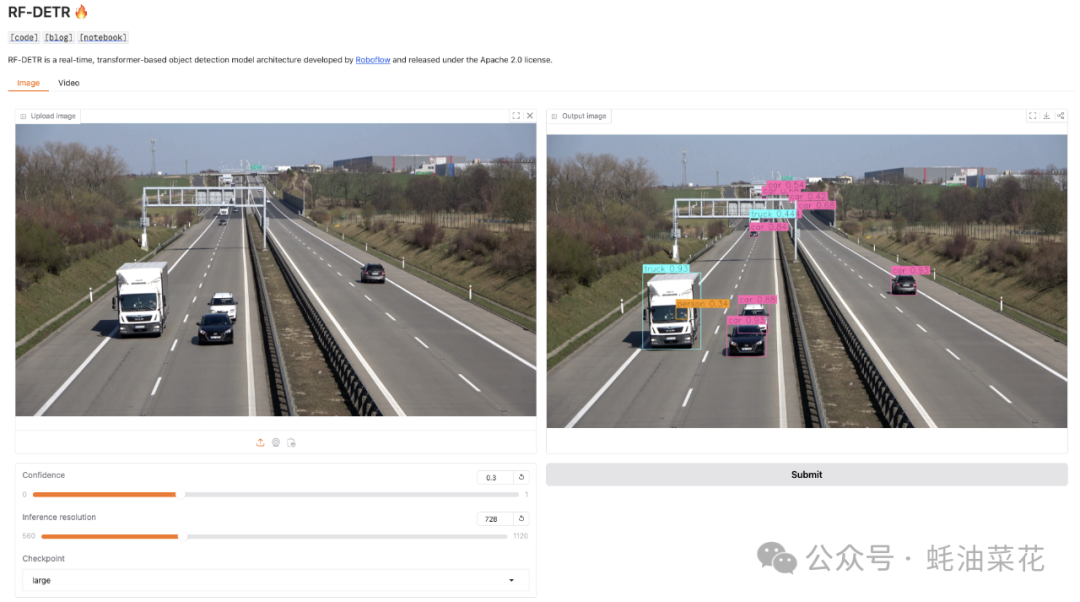
你可以在Hugging Face Spaces上直接体验RF-DETR的在线演示:https://huggingface.co/spaces/SkalskiP/RF-DETR
如何运行 RF-DETR
下面将指导你如何安装、运行和微调 RF-DETR 模型。
安装 RF-DETR
在使用 RF-DETR 之前,你需要安装 rfdetr 包。确保你的 Python 版本为 3.9 或更高版本。
pip install rfdetr
使用 RF-DETR 进行推理
RF-DETR 提供了预训练的 Microsoft COCO 数据集模型检查点,你可以直接加载并用于目标检测任务。
1. 单张图片推理
以下代码展示了如何使用 RF-DETR 对单张图片进行目标检测。
import io
import requests
import supervision as sv
from PIL import Image
from rfdetr import RFDETRBase
from rfdetr.util.coco_classes import COCO_CLASSES
# 加载 RF-DETR 模型
model = RFDETRBase()
# 从 URL 加载图片
url = "https://media.roboflow.com/notebooks/examples/dog-2.jpeg"
image = Image.open(io.BytesIO(requests.get(url).content))
# 进行目标检测
detections = model.predict(image, threshold=0.5)
# 生成标注标签
labels = [
f"{COCO_CLASSES[class_id]} {confidence:.2f}"
for class_id, confidence
in zip(detections.class_id, detections.confidence)
]
# 绘制边界框和标签
annotated_image = image.copy()
annotated_image = sv.BoxAnnotator().annotate(annotated_image, detections)
annotated_image = sv.LabelAnnotator().annotate(annotated_image, detections, labels)
# 显示结果
sv.plot_image(annotated_image)
2. 视频推理
如果需要对视频进行推理,可以使用以下代码。
import supervision as sv
from rfdetr import RFDETRBase
from rfdetr.util.coco_classes import COCO_CLASSES
# 加载 RF-DETR 模型
model = RFDETRBase()
def callback(frame, index):
# 对每一帧进行目标检测
detections = model.predict(frame, threshold=0.5)
# 生成标注标签
labels = [
f"{COCO_CLASSES[class_id]} {confidence:.2f}"
for class_id, confidence
in zip(detections.class_id, detections.confidence)
]
# 绘制边界框和标签
annotated_frame = frame.copy()
annotated_frame = sv.BoxAnnotator().annotate(annotated_frame, detections)
annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
return annotated_frame
# 处理视频文件
process_video(
source_path="input_video.mp4", # 输入视频路径
target_path="output_video.mp4", # 输出视频路径
callback=callback
)
3. 摄像头实时推理
你也可以通过摄像头实时进行目标检测。
import cv2
import supervision as sv
from rfdetr import RFDETRBase
from rfdetr.util.coco_classes import COCO_CLASSES
# 加载 RF-DETR 模型
model = RFDETRBase()
# 打开摄像头
cap = cv2.VideoCapture(0)
while True:
success, frame = cap.read()
if not success:
break
# 对每一帧进行目标检测
detections = model.predict(frame, threshold=0.5)
# 生成标注标签
labels = [
f"{COCO_CLASSES[class_id]} {confidence:.2f}"
for class_id, confidence
in zip(detections.class_id, detections.confidence)
]
# 绘制边界框和标签
annotated_frame = frame.copy()
annotated_frame = sv.BoxAnnotator().annotate(annotated_frame, detections)
annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
# 显示结果
cv2.imshow(“Webcam”, annotated_frame)
# 按下 ‘q’ 键退出
if cv2.waitKey(1) & 0xFF == ord(‘q’):
break
cap.release()
cv2.destroyAllWindows()
模型变体与输入分辨率
模型变体
RF-DETR 提供两个变体:
- RF-DETR-B (29M 参数):适合资源受限的场景。
- RF-DETR-L (128M 参数):适合更高精度的需求。
from rfdetr import RFDETRBase, RFDETRLarge
# 加载 RF-DETR-B 模型
model_base = RFDETRBase()
# 加载 RF-DETR-L 模型
model_large = RFDETRLarge()
输入分辨率
更高的分辨率通常会提高预测质量,但会减慢推理速度。你可以通过调整 resolution 参数来配置输入分辨率(值必须是 56 的倍数)。
model = RFDETRBase(resolution=560)
训练 RF-DETR 模型
数据集结构
RF-DETR 需要数据集以 COCO 格式组织,分为 train、valid 和 test 三个子目录,每个子目录包含图片和对应的标注文件 _annotations.coco.json。
dataset/
├── train/
│ ├── _annotations.coco.json
│ ├── image1.jpg
│ ├── image2.jpg
├── valid/
│ ├── _annotations.coco.json
│ ├── image1.jpg
│ ├── image2.jpg
└── test/
├── _annotations.coco.json
├── image1.jpg
├── image2.jpg
你可以使用 Roboflow 创建或转换数据集,并导出为 COCO 格式。
微调模型
你可以从预训练的 COCO 检查点微调 RF-DETR 模型。
from rfdetr import RFDETRBase
# 加载模型
model = RFDETRBase()
# 开始微调
model.train(
dataset_dir=“path/to/dataset”, # 数据集路径
epochs=10, # 训练轮数
batch_size=4, # 批量大小
grad_accum_steps=4, # 梯度累积步数
lr=1e-4 # 学习率
)
批量大小调整
不同的 GPU 拥有不同的显存容量,你可以通过调整 batch_size 和 grad_accum_steps 来适应你的硬件条件,确保两者的乘积为 16。
多 GPU 训练
使用 PyTorch 的 Distributed Data Parallel (DDP) 可以在多 GPU 上训练 RF-DETR。
python -m torch.distributed.launch \
--nproc_per_node=8 \
--use_env \
main.py
导出 ONNX 模型
RF-DETR 支持将模型导出为 ONNX 格式,以便在不同的推理框架中使用。
from rfdetr import RFDETRBase
# 加载模型
model = RFDETRBase()
# 导出 ONNX 模型
model.export()
导出的 ONNX 模型将保存在 output 目录中。
资源
RF-DETR的出现,为实时目标检测领域注入了新的活力。其优异的性能、灵活的部署选项和友好的开源协议,使其成为开发者应对高要求视觉任务时一个非常值得尝试的新工具。对于想要深入了解最新计算机视觉和开源项目动态的开发者,不妨持续关注其在各类实际场景中的应用与优化。
 发表于 2026-4-11 07:58:15
|
查看: 212|
回复: 0
发表于 2026-4-11 07:58:15
|
查看: 212|
回复: 0
