索引到底是什么?简单来说,它是帮助MySQL高效获取数据的排好序的数据结构。你可以把它想象成一本字典的目录,能让你快速定位到想要的内容,而无需一页一页翻阅整本书。

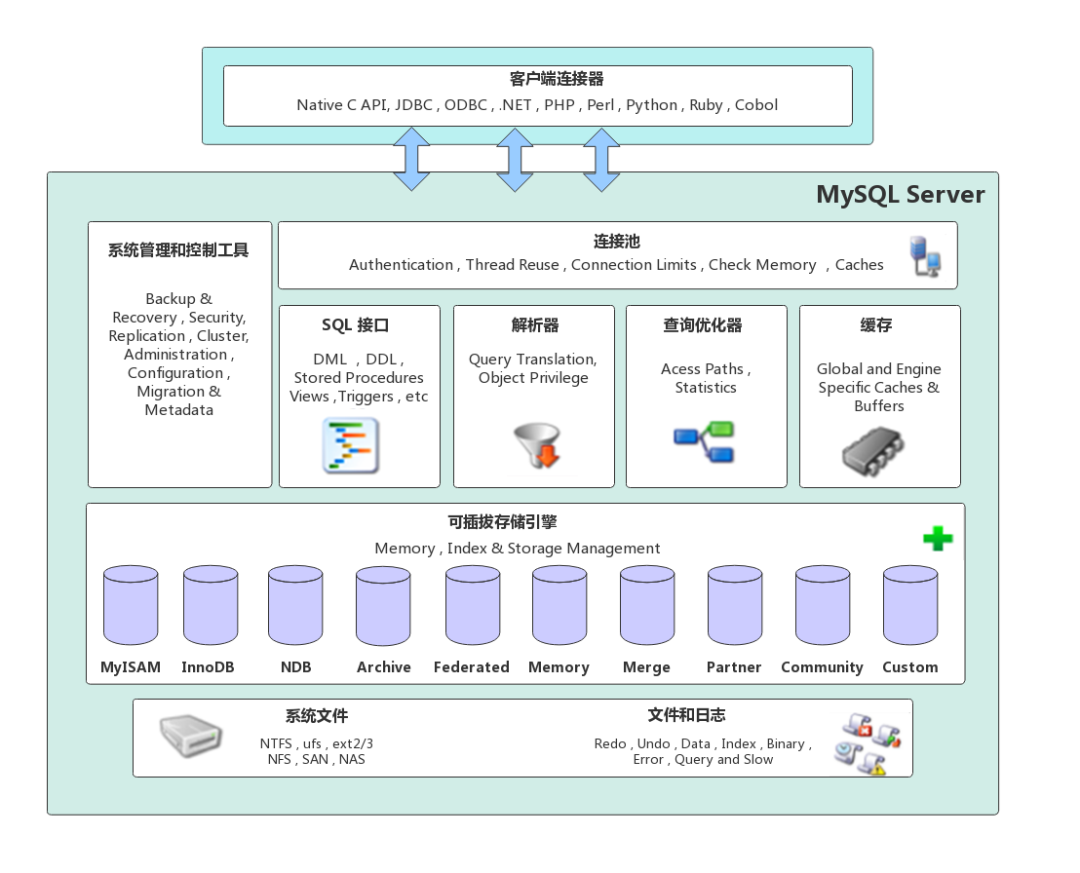
要深入理解索引如何工作,我们需要先俯瞰MySQL的系统架构。下图清晰地展示了MySQL Server的各个核心组件,从客户端连接器到可插拔的存储引擎(如InnoDB),帮助我们建立起全局认知。
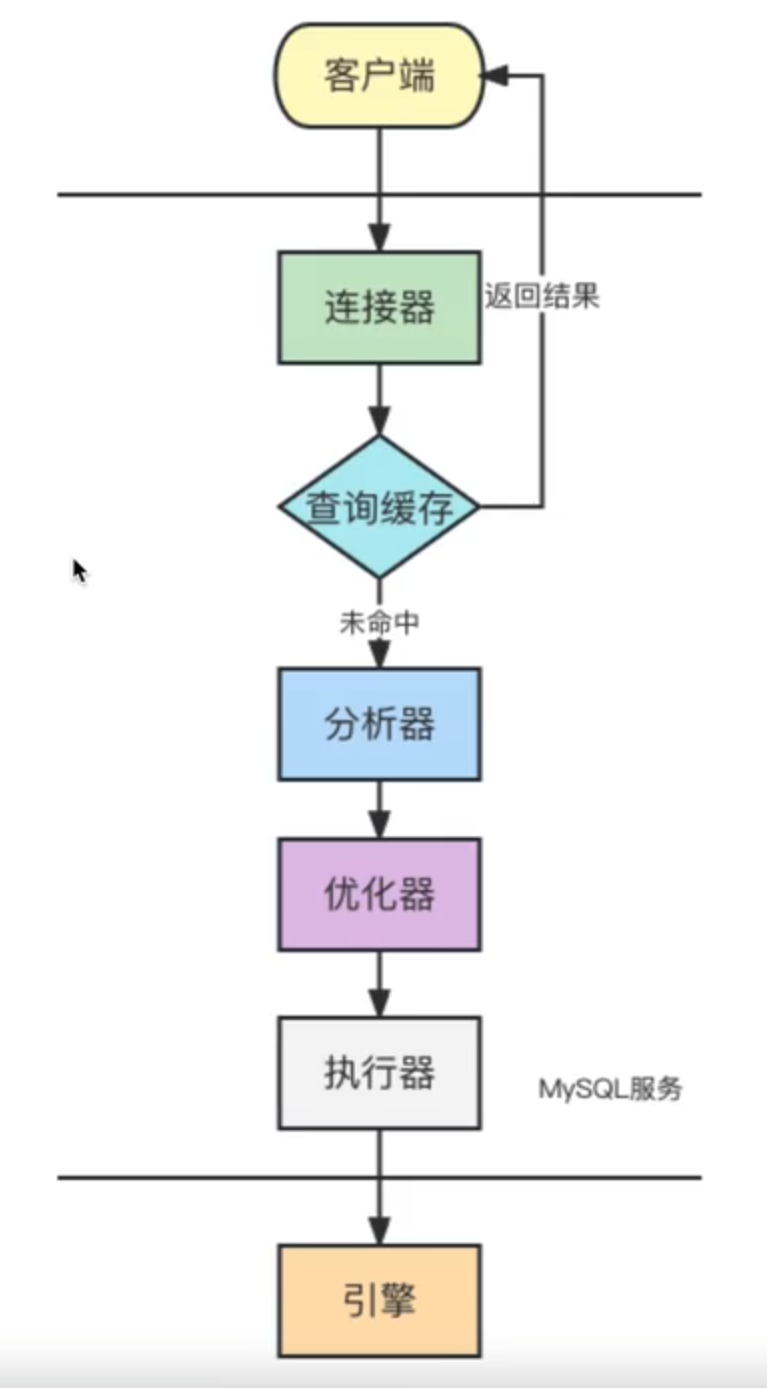
而一条SQL语句的具体执行过程,则遵循着一条清晰的流水线,索引正是在这个流程中发挥关键作用。
一、 索引性能剖析:EXPLAIN是关键
评估一个索引是否高效,最直接的工具就是SQL的执行计划。通过 EXPLAIN 命令,我们可以窥探MySQL优化器是如何处理你的查询的。执行计划中,type 字段是衡量查询访问数据方式的核心指标,其性能从最优到最差排序如下:
system > const > eq_ref > ref > range > index > ALL
下表详细解读了执行计划中各个字段的含义,是你进行数据库性能调优的必备知识。
| 列名 |
关键值类型 |
性能含义与优化方向 |
| id |
查询序列号 |
相同id按顺序执行,不同id值越大优先级越高(子查询执行顺序) |
| select_type |
SIMPLE/PRIMARY |
简单查询类型,无子查询或UNION |
|
SUBQUERY/DERIVED |
子查询或派生表,警惕性能问题 |
|
UNION/UNION RESULT |
UNION操作的后续SELECT |
| table |
表名或别名 |
<unionM,N> 表示UNION结果,<derivedN> 表示派生表 |
| partitions |
匹配的分区名 |
分区表优化关键,NULL表示未分区 |
| type 🔥 |
system(最优) |
系统表只有一行数据 |
|
const/eq_ref(优) |
主键/唯一索引查找(例:WHERE id = 1) |
|
ref(良) |
非唯一索引查找(例:WHERE index_col='value') |
|
range(中) |
索引范围扫描(例:WHERE id > 100) |
|
index(差) |
全索引扫描(扫描整棵索引树) |
|
ALL(最差) ⚠️ |
全表扫描,百万级表耗时可能>1秒 |
| possible_keys |
可能使用的索引列表 |
优化器考虑的索引,NULL表示无可用索引 |
| key 🔥 |
实际使用的索引名 |
显示 PRIMARY(主键)或自定义索引名,NULL表示未走索引 |
| key_len |
索引使用字节数 |
数值越大使用索引越完整(复合索引判断依据) |
| ref |
索引比较的列或常量 |
const(常量),func(函数),列名(关联查询) |
| rows 🔥 |
预估扫描行数 |
核心指标!值>1000需警惕,>10000必须优化 |
| filtered |
存储引擎过滤后的剩余比例(%) |
100%表示全返回,10%表示过滤掉90%行 |
| Extra 🔥 |
Using index(优) |
覆盖索引,无需回表 |
|
Using where(中) ⚠️ |
回表查询:索引过滤后需查主键获取完整行(核心瓶颈!) |
|
Using filesort(差) ⚠️ |
文件排序,内存/磁盘排序耗时 |
|
Using temporary(差) ⚠️ |
创建临时表,GROUP/ORDER未用索引 |
|
Using join buffer(中) ⚠️ |
关联缓存,大表关联可能耗时 |
执行耗时经验值参考(基于SSD磁盘)
为了让性能指标更直观,以下是在不同数据量下的耗时参考:
| 扫描方式 |
10万行表 |
100万行表 |
优化建议 |
| const(主键) |
0.1ms |
0.1ms |
最优方式 |
| ref(索引) |
1-5ms |
10-50ms |
保持即可 |
| range(范围) |
10-50ms |
100-500ms |
检查范围是否过大 |
| index(索引扫) |
50-100ms |
500ms-2s |
需优化WHERE条件 |
| ALL(全表扫) ⚠️ |
100ms-1s |
1s-10s+ |
必须添加索引! |
| filesort |
+1-50ms |
+100ms-2s |
添加ORDER字段索引 |
| 回表10万次 ⚠️ |
+20-200ms |
+0.2-2s |
覆盖索引优化 |
二、 索引背后的数据结构:为什么是B+Tree?
MySQL索引并非凭空产生,它建立在经典的数据结构之上。了解这些结构的演进,能让你真正明白B+Tree的优势所在。
- 二叉树:最基础的树结构,但无自平衡机制,数据有序插入时会退化为链表,查询效率骤降。
- 红黑树:一种自平衡二叉树,解决了退化问题,但树的高度在数据量大时依然很高,导致磁盘I/O次数多。
- Hash表:精确查询(
=, IN)极快,但致命缺陷是不支持范围查询。
- B-Tree:一棵“矮胖”的多路平衡查找树,每个节点可以存储多个key和数据,降低了树高。
- B+Tree(MySQL索引默认采用):B-Tree的优化版本,也是现代数据库索引的基石。其核心特点:
- 非叶子节点只存储索引键(不存数据),因此能容纳更多键值,进一步降低树高。
- 所有数据都存储在叶子节点,并且叶子节点间通过双向指针连接。
- 双向指针使得范围查询和全表顺序扫描异常高效。
B+树的层数通常控制在3层以内,最多不超过4层。 这是因为每多一层,查询时就可能多一次磁盘I/O。在实践中,3层的B+树已经能够支撑千万级别的数据量,体现了其卓越的设计。
三、 索引的主要类型
根据不同的组织和存储方式,索引可以分为以下几类:
-
聚簇索引(Clustered) vs 非聚簇索引(Non-clustered)
- 聚簇索引:在InnoDB中,表数据文件本身就是按主键顺序组织的一颗B+Tree,叶子节点包含了完整的数据行。一张表只有一个聚簇索引。
- 非聚簇索引(如MyISAM):索引文件和数据文件是分离的。索引树的叶子节点存储的是指向数据行物理地址的指针,查询时需要“回表”。
-
主键索引与二级索引
- 主键索引:即聚簇索引,基于主键构建。
- 二级索引:也称辅助索引。在InnoDB中,二级索引的叶子节点存储的是主键值。通过二级索引查找数据,需要先找到主键,再回表到聚簇索引中查找完整数据,这就是“回表查询”。
-
联合索引
由多个字段组合创建的索引。它遵循“最左前缀原则”,即查询条件必须从索引的最左列开始,才能有效利用索引。
四、 索引的实战应用与失效陷阱
理解了原理,我们来看看如何在实战中应用和规避陷阱。
索引执行与查看
索引的执行是查询过程的一部分。我们可以通过 EXPLAIN 来查看索引是否被使用以及如何使用。
EXPLAIN SELECT user_id, username, phone FROM users WHERE age = 30;
观察输出中的关键字段:
type: ref(二级索引查找)key: 使用的二级索引名(如 idx_age)key_len: 索引使用的长度Extra:
Using index: 使用了覆盖索引,性能最佳。Using where: 发生了回表查询或索引过滤后仍需额外条件判断。NULL (或无此提示): 通常也表示发生回表。
覆盖索引:性能加速器
如果查询所需要的所有列都包含在索引中(即索引“覆盖”了查询需求),MySQL可以直接从索引中取得数据,而无需回表。这能极大提升查询速度。
回表查询:主要性能瓶颈
当查询的字段不全部在索引中时,就需要根据索引找到的主键ID,回到聚簇索引中去获取完整的行数据。SELECT * 是引发回表的常见原因,应尽量避免。
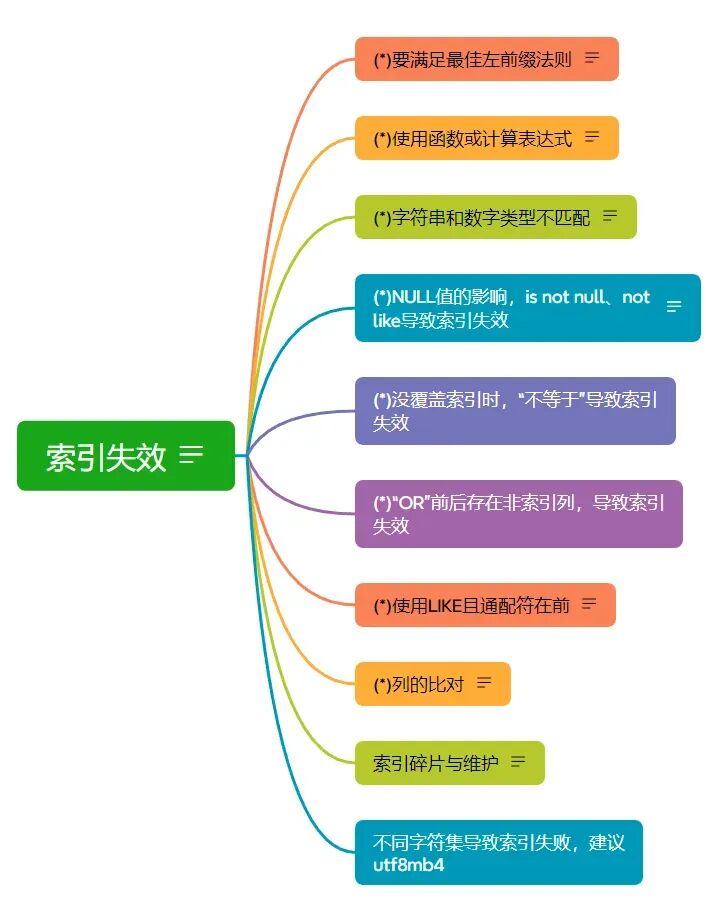
索引失效:你加了索引,为什么还慢?
这是最需要警惕的情况。创建了索引不等于查询一定会用上。下图总结了导致索引失效的常见原因:
五、 SQL执行计划分析与优化实战指南
🔍 执行计划分析核心要素
| 字段 |
关键值 |
优化意义 |
| type |
ALL(全表扫描) ⚠️ |
最需优化的类型,大表性能杀手 |
|
index(索引全扫描) |
需检查是否能用更高效的range扫描 |
|
range(索引范围扫描) ✓ |
较理想 |
|
ref/eq_ref(索引查找) ✓ |
最优类型之一 |
| key |
(具体索引名称) ✓ |
实际使用的索引 |
|
NULL ⚠️ |
未使用索引 |
| rows |
< 总行数1% ✓ |
扫描行数合理 |
|
> 总行数10% ⚠️ |
需优化索引或改写SQL |
| Extra |
Using where ⚠️ |
回表查询(常见性能瓶颈) |
|
Using filesort ⚠️ |
文件排序,需优化ORDER BY |
|
Using temporary ⚠️ |
临时表,GROUP/ORDER BY无索引 |
|
Using index ✓ |
覆盖索引,最佳性能 |
🚀 快速定位与优化慢SQL(实战步骤)
-
获取执行计划
EXPLAIN
-- 替换为你的慢SQL
SELECT * FROM orders WHERE user_id = 100 AND create_time > '2023-01-01';
-
| 诊断流程与优化手段 |
问题现象 |
原因 |
优化方案 |
| type = ALL |
全表扫描 |
1️⃣ 为WHERE条件字段添加组合索引
ALTER TABLE orders ADD INDEX idx_user_time(user_id,create_time) |
| key = NULL |
未使用索引 |
2️⃣ 检查索引有效性
SHOW INDEX FROM orders
重建失效索引 ANALYZE TABLE orders |
| rows > 10000 |
扫描行数过多 |
3️⃣ 优化查询条件:
- 避免 LIKE '%value%'
- 用BETWEEN代替 > + <
- 添加复合索引 |
| Extra: Using filesort |
文件排序 |
4️⃣ 为ORDER BY字段添加索引:
ALTER TABLE orders ADD INDEX idx_sort_field(sort_field) |
| Extra: Using temporary |
临时表 |
5️⃣ 优化GROUP BY:
- 确保GROUP BY字段有索引
- 减少SELECT列数避免内存溢出 |
| Extra: Using where |
回表查询 |
6️⃣ 使用覆盖索引:
SELECT user_id, create_time → 仅查询索引字段 |
-
高级分析工具
-- 查看详细执行耗时 (MySQL 8.0+)
EXPLAIN ANALYZE
SELECT ...;
-- 开启性能分析
SET profiling = 1;
SELECT ...;
SHOW PROFILES;
SHOW PROFILE FOR QUERY 1;
-- 强制使用索引测试
SELECT * FROM orders FORCE INDEX(idx_user) WHERE ...
📌 重点优化场景示例
🐢 场景1:全表扫描(type=ALL)
-- 原始SQL (无索引)
SELECT * FROM users WHERE phone = '13800138000';
-- 优化方案
ALTER TABLE users ADD INDEX idx_phone(phone);
🔄 场景2:回表查询(Using where)
-- 原始SQL
SELECT name, email FROM users WHERE city = 'Beijing';
-- 优化为覆盖索引
ALTER TABLE users ADD INDEX idx_city_name_email(city, name, email);
🗂️ 场景3:文件排序(Using filesort)
-- 原始SQL
SELECT * FROM orders ORDER BY amount DESC;
-- 优化方案
ALTER TABLE orders ADD INDEX idx_amount(amount);
SELECT * FROM orders ORDER BY amount DESC LIMIT 100; -- 增加LIMIT限制结果集
掌握索引的原理、学会分析执行计划、并能针对性地进行优化,是每一位后端开发者提升数据库应用性能的必修课。希望这篇整合了基础与实战的指南能为你带来帮助。如果你想深入探讨更多数据库或系统设计相关话题,欢迎访问云栈社区与更多开发者交流。

 发表于 2026-4-13 04:03:17
|
查看: 164|
回复: 0
发表于 2026-4-13 04:03:17
|
查看: 164|
回复: 0
