最近,我基于现有的知识库文档,搭建了一套智能问答系统。最初的动机很直接:能不能让已有的文档,以“问答”这种更便捷的方式被使用起来?
在实现过程中,既有收获,也踩了不少坑。有些环节效果不错,有些地方则还有很大的优化空间。这篇文章算是对整个实现过程的一次复盘梳理,如果你也在探索RAG相关的应用,或许能带来一些参考。
🧩 整体思路:一个简单的 RAG 流程拆解
整个系统的核心是使用 Spring AI Alibaba ReactAgent 进行智能体(Agent)的流程编排,向量检索部分则选择了 Qdrant。
从流程上看,可以清晰地拆解为四个主要阶段:
文档处理 → 索引增强 → 检索 → 问答生成
对应到具体实现,分别是:
- 文档处理:语雀 / Markdown → 清洗 → 切块
- 索引增强:提取标题、关键词、摘要
- 检索:向量检索 + BM25 + 融合排序
- 问答:Query Rewrite + Agent 多次检索 + 生成答案
这几个环节串联起来,就构成了一条相对完整的 RAG 链路。
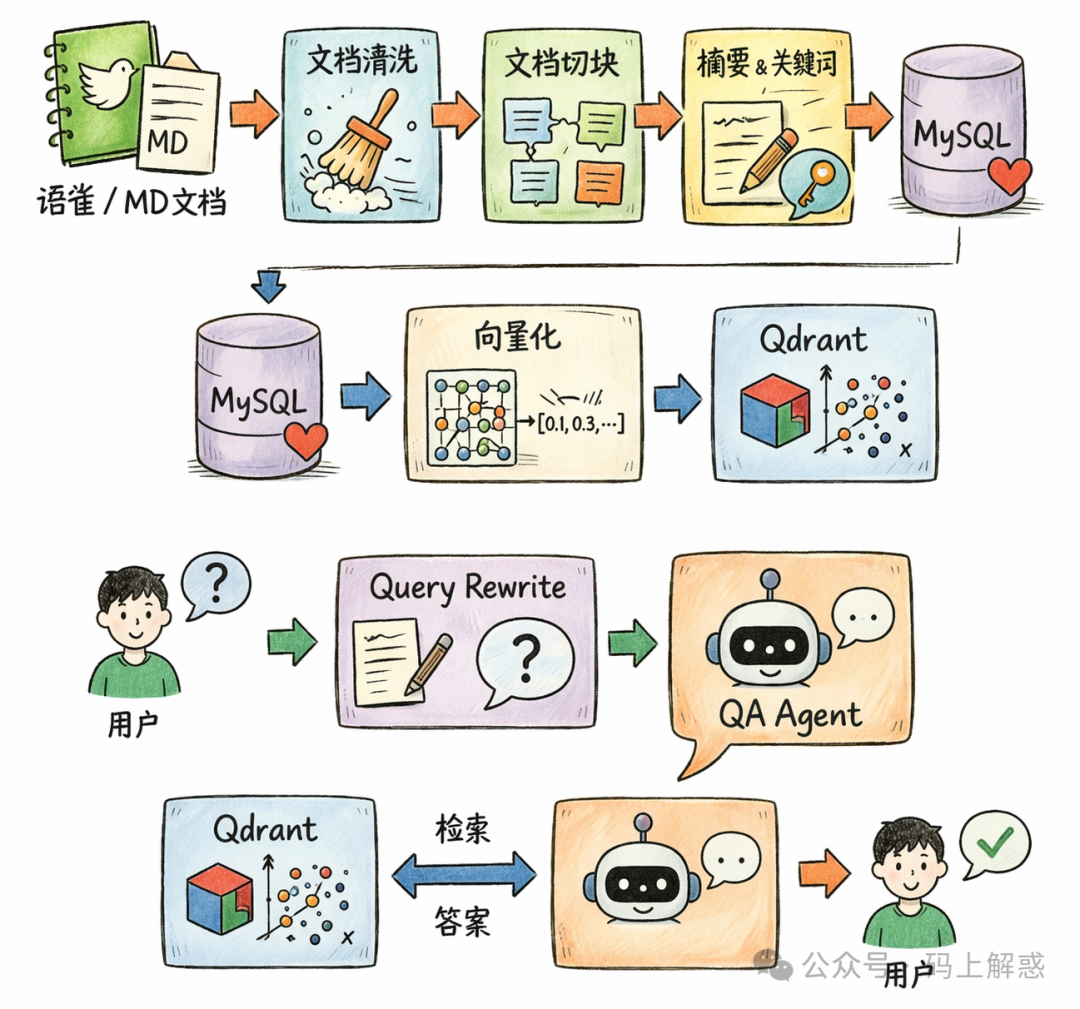
📌 第一步:先解决“文档从哪里来”
我的知识源主要来自两类:
这里有一个关键处理:不仅要提取文档正文,还要把目录结构一并保留下来。因为在后续的切块步骤中,目录信息是天然的、有价值的上下文。
⚙️ 第二步:文档清洗(基础但必要)
获取文档后,并非直接进行向量化,而是先做一轮清洗:
- 移除无关的图片
- 清理注释等杂质
- 保留代码块
- 统一转换为纯净的 Markdown 文本
这一步逻辑不复杂,但如果不做,后续环节的问题会被放大。
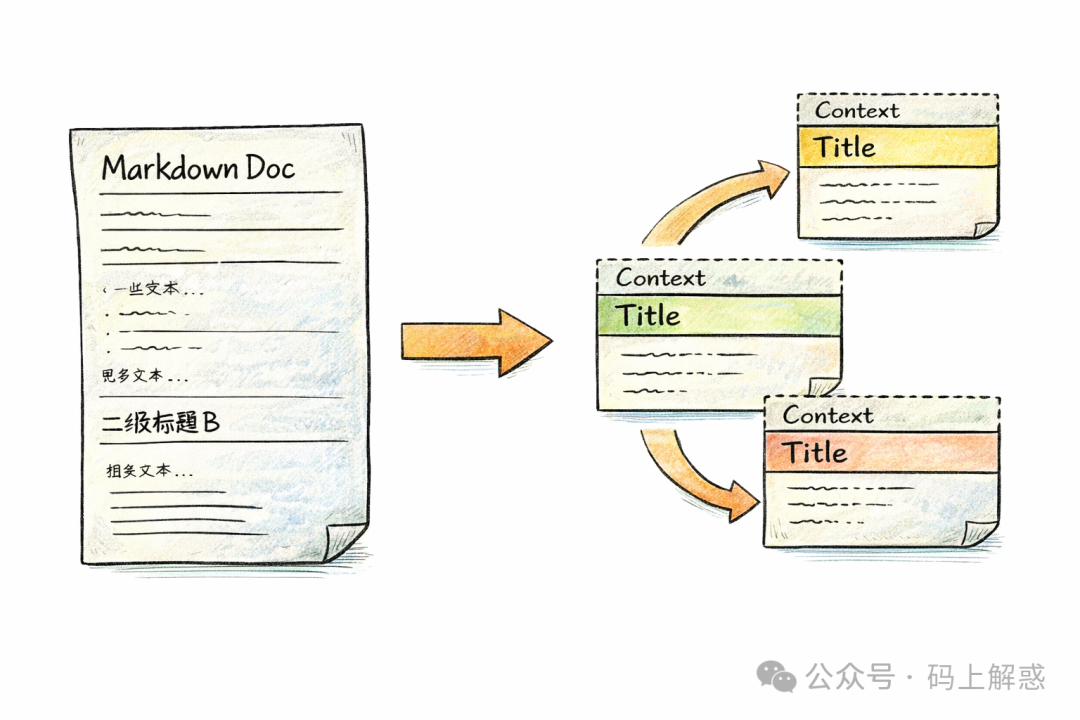
✂️ 第三步:切块(Chunking 比想象中更重要)
RAG 中一个容易被轻视的环节是:文档究竟该怎么切?
很多常见的做法是:
但这很容易导致一个核心问题:语义上下文被生硬切断。
我的策略是:结合目录结构进行分级字数控制。
大致规则如下:
- 内容不长 → 整体作为一个块
- 内容较长 → 按一级标题切分
- 仍然很长 → 按二级标题切分
- 过长 → 再按段落切分
核心逻辑代码示例如下:
List<MarkdownUtils.ChunkResult> chunks = MarkdownUtils.splitWithContext(content, docContext);
for (MarkdownUtils.ChunkResult chunk : chunks) {
FeaturePoint point = extractFromChunk(chunk);
}
我特别在意一点:每个 chunk 都必须拥有一个“能够清晰承接上下文的标题”。这并非为了美观,而是为了明确表达:
- 这个片段来自哪篇文档?
- 它属于哪个章节?
- 当前具体在讲述什么内容?
可以这样理解:每个 chunk 都应该是一个 “最小语义单元”,而非一段随机的文本片段。
🧠 第四步:索引增强(不是只存正文)
完成切块后,并非直接将原始内容存入向量库,而是增加了一步 “信息补充”:提取关键词和摘要。
这里我经历了一个小调整:最初尝试使用 Agent 来提取关键词,但实践后发现,将其改为基于规则的代码实现更为合适。原因很实际:
- 关键词提取更偏向规则型任务
- 代码实现更稳定、可控
- 后续调整和优化的成本也更低
至于摘要生成,若有更高要求,仍可考虑用大模型辅助。
最终,这些增强信息会与正文一同存储:
QaPair pair = QaPair.builder()
.featureTitle(point.title())
.featureKeyword(point.keywords())
.featureSummary(point.summary())
.featureContent(point.content())
.build();
一个直观的体会是:并非所有环节都适合使用 Agent。在规则明确的地方,传统的工程逻辑往往更高效可靠。
🚀 第五步:向量化(拼的不只是内容)
在进行向量化时,我没有仅仅对正文做 Embedding,而是将多种信息拼接起来:
标题 + 关键词 + 摘要 + 正文
然后再写入 Qdrant 向量数据库。
为什么要这样做?因为在企业级应用场景中,许多关键信息(如菜单名、字段名、功能名)恰恰蕴含在标题和关键词里。如果只对正文进行向量化,这些重要线索反而容易丢失。
简单来说,目标不是存储“内容本身”,而是存储 “更容易被检索到的内容表达”。
🔍 第六步:检索(向量 + BM25 的混合策略)
在检索层,我没有只依赖向量检索。纯向量检索在实际应用中可能存在一些问题:
- 对精确术语不敏感
- 有时会召回语义相关但内容并不精准的结果
因此,我实现了一层混合检索:
- 向量检索:负责语义层面的宽泛召回
- BM25:负责关键词的精确命中
- RRF (Reciprocal Rank Fusion):对多路检索结果进行融合与重排序
核心逻辑类似这样:
List<Document> vectorResults = performVectorSearch(query, vectorTopK, similarityThreshold);
List<Document> keywordResults = performKeywordSearch(query, bm25TopK);
List<Document> mergedResults = mergeWithRRF(vectorResults, keywordResults, finalTopK);
经过这样处理,在我的测试场景中,检索命中效果变得更加稳定,尤其对于包含“精确名称”类的问题,表现更好。
🔄 第七步:Query Rewrite(多轮对话的关键)
为了支持流畅的多轮对话,我增加了一层 Query Rewrite(查询改写)。用户的当前问题不会直接用于检索,而是会结合最近几轮的对话历史,被改写为一个更完整、更独立的问题。
例如,用户可能连续提问:
如果直接将“为什么不行?”拿去检索,基本无法命中任何内容。经过 Query Rewrite 后,这个问题可能会被补充上下文,改写成“为什么在配置 X 功能时会出现 Y 错误?”,然后再进行检索。
本质上,这一步是在做 Query Reformulation(查询重构),用以解决多轮对话中普遍存在的上下文缺失问题。
💬 第八步:让 Agent 参与“检索过程”
最后才进入问答生成阶段。这里我没有采用简单的“检索一次,直接生成答案”的模式,而是设计为:让 ReactAgent 具备多次调用检索工具的能力。
例如,Agent 可以:
- 根据初步结果,变换关键词再次检索
- 进行多轮、递进式的检索以收集更全面的信息
- 最后再组织和生成最终答案
核心的 Agent 构建方式如下:
return ReactAgent.builder()
.name("QA-Chat-Agent")
.model(chatModel)
.methodTools(vectorSearchTool)
.build();
这种方式更接近于人类“查阅资料”的过程,而非简单地“直接编造答案”。
📊 一些实践中的体会(仅供参考)
这部分不算正式结论,只是我在这次实现过程中的几点感受:
- 文档质量是天花板:原始文档的质量,直接决定了最终问答效果的上限。
- 切块方式影响巨大:不同的切块策略,对检索召回率的影响非常显著。
- 标题是检索的一部分:标题不仅仅是装饰,它本身是重要的检索信号。
- Query Rewrite 很有必要:对于多轮对话场景,查询改写几乎是必选项。
- Agent 分工要清晰:并非 Agent 用得越多越好,明确其职责边界更重要。
如果用一句话总结:在 RAG 系统中,模型能力固然重要,但数据和检索环节的设计往往更为关键。
🌐 开源 & 体验
我将这套实现进行了整理,并开源了一个版本:
项目 README 包含了完整的流程说明,涵盖:
- 文档处理与切块策略
- 向量化与 Qdrant 存储
- 混合检索实现
- Query Rewrite 逻辑
- Agent 调用链路
如果你正在开发类似的 RAG 应用,欢迎参考或基于此进行改造。
同时,我也部署了一个在线体验环境:
🧾 最后
这套系统仍在持续迭代和打磨中。后续可能优化的方向包括 Prompt 的精细调整、知识库的持续治理等。
如果你也在探索 RAG 或 Agent 的落地,欢迎在技术社区进行交流,例如 云栈社区 就聚集了许多关注此类实践的开发者。我也仍在不断学习和实践中。
扩展阅读:
 发表于 2026-4-17 01:15:38
|
查看: 185|
回复: 0
发表于 2026-4-17 01:15:38
|
查看: 185|
回复: 0
