这是一台前端开发者也能轻松上手的轻量级 AI 主机。
这几年 人工智能(AI)和大模型技术发展迅猛,企业对 AI 的需求水涨船高,但现实情况往往充满挑战:
- 云端模型成本高昂:API 调用费用随着业务量指数级增长。
- 数据安全顾虑:敏感业务数据无法上传至公有云。
- 传统硬件门槛高:企业级 GPU 服务器动辄十几万,噪音大、功耗高,且需要专业机房。
- 技术人才短缺:业务部门人员通常不懂模型训练,甚至不会编写复杂的 数据库 SQL 语句。
- 场地限制:缺乏独立机房空间。
但业务创新必须推进。既要利用 AI 辅助代码开发,又要探索如何将 AI 能力应用于企业内部数据。于是,寻找一台能在本地流畅运行大模型、成本可控的机器成为了关键。
最终,我选择了 Minisforum 铭凡。本文将基于我的实际体验、测试数据及对比分析,为你整理一份完整的实战分享。
📦 外观与工艺:体积虽小,内有乾坤
初次上手,其紧凑的体积令人印象深刻:

整机体积仅 3.3L,略大于常见的路由器,但做工极其扎实:

- 全金属外壳:质感出色,兼顾被动散热。
- 大面积散热孔:确保高负载下的空气流通。
- 接口布局合理:前置接口集中排列,便于插拔。
- 商务风格设计:外观低调沉稳,无多余光效。
它不仅仅是一台迷你主机,更像是一台专业的 边缘计算设备。无论是放置在办公工位还是部署在机柜中,都非常合适。
🧠 核心配置:非“顶配电脑”,却是“大模型神器”
官方配置参数如下,我们重点关注其 AI 相关的核心指标:

- CPU:16 核 32 线程,多任务处理能力强。
- GPU:RDNA3.5 架构,图形处理与计算性能均衡。
- NPU:搭载新版 NPU,专为 AI 加速设计。
- 算力:整机算力高达 126 TOPS。
- 内存:最高支持 128GB LPDDR5x(UMA 架构)。
对于大模型应用而言,最关键的优势在于:
它能直接加载 70B、120B、190B 甚至 235B 参数量的大模型,并且能够稳定输出,而非仅仅是“勉强运行”。

这得益于 UMA(统一内存架构) —— CPU、GPU 和 NPU 共享内存池。相比于传统显卡受限于 24GB 显存的瓶颈,UMA 架构允许模型调用高达 128GB 的系统内存,从而轻松运行更大参数的模型。
🛠️ 本地 AI 环境搭建:10 分钟极速部署
环境搭建的简便程度超乎想象,即使是前端开发者也能在 Linux 或 Windows 环境下快速搞定:
① 系统准备
下载官方系统镜像写入 U 盘,进行常规安装,使用默认配置即可。
② 安装 Ollama
访问 Ollama 官网下载安装包:https://ollama.com/
下载并运行 OllamaSetup.exe,按照指引点击 "Next" 和 "Install" 完成安装。程序会自动配置系统路径并设置为开机自启。
验证安装是否成功,可打开命令提示符(Win + R 输入 cmd)执行:
ollama --version
③ 拉取模型
在终端中直接运行以下命令拉取 DeepSeek 模型:
ollama run deepseek-v3.1
Ollama 会自动检测本地是否存在该模型,若不存在则自动从服务器下载。更多模型可通过 https://ollama.com/search 查询。
④ 启动服务
ollama serve
服务启动后,即可通过 VSCode 配合 Continue 插件连接本地推理服务。
配置好服务地址后,无论是 AI 代码重构、生成还是解释,响应都非常迅速。
实测速度表现优异:
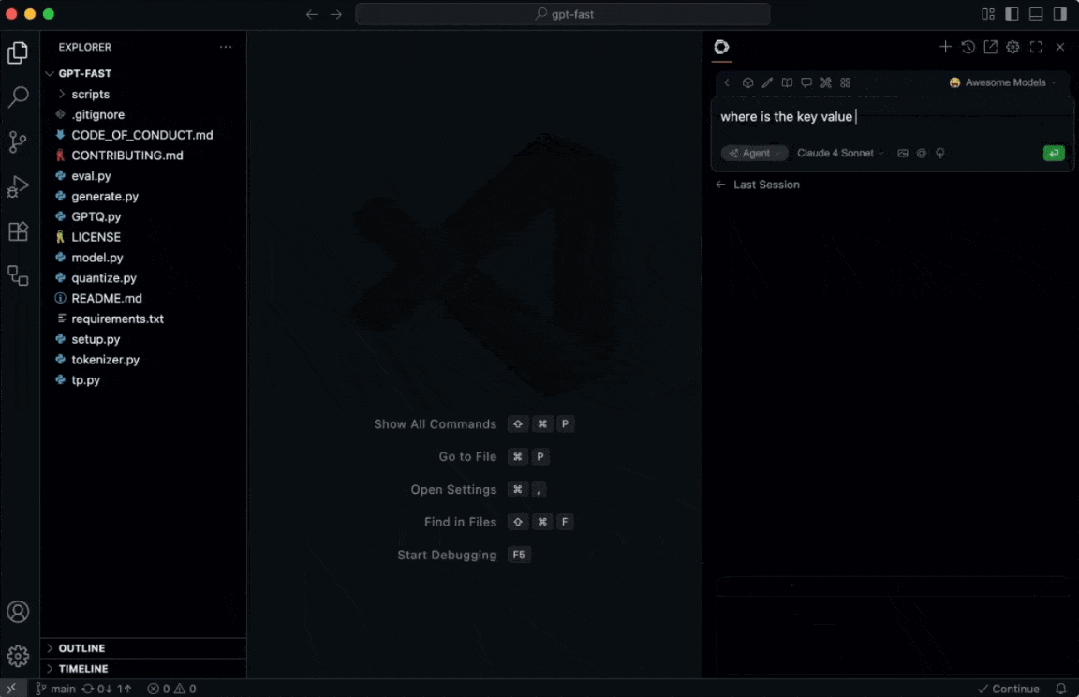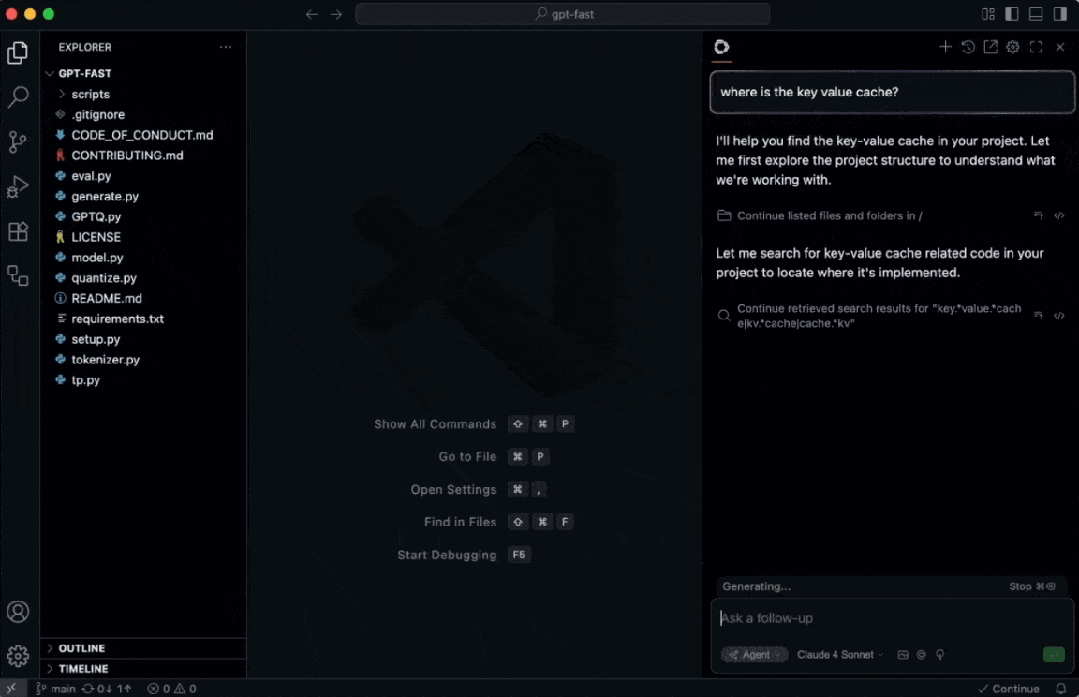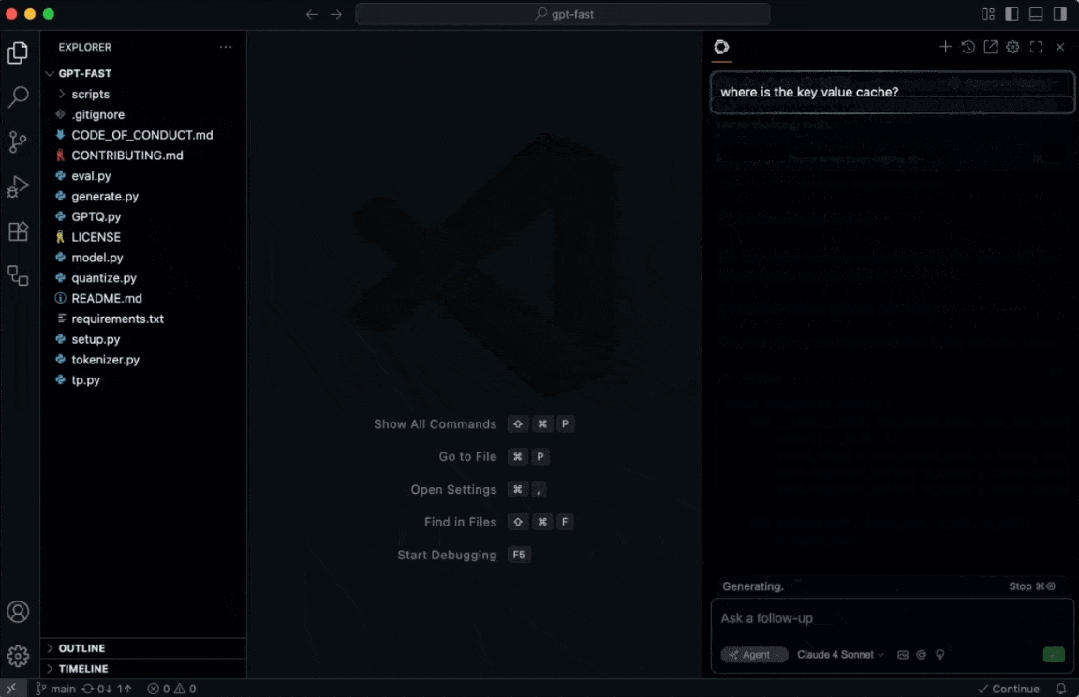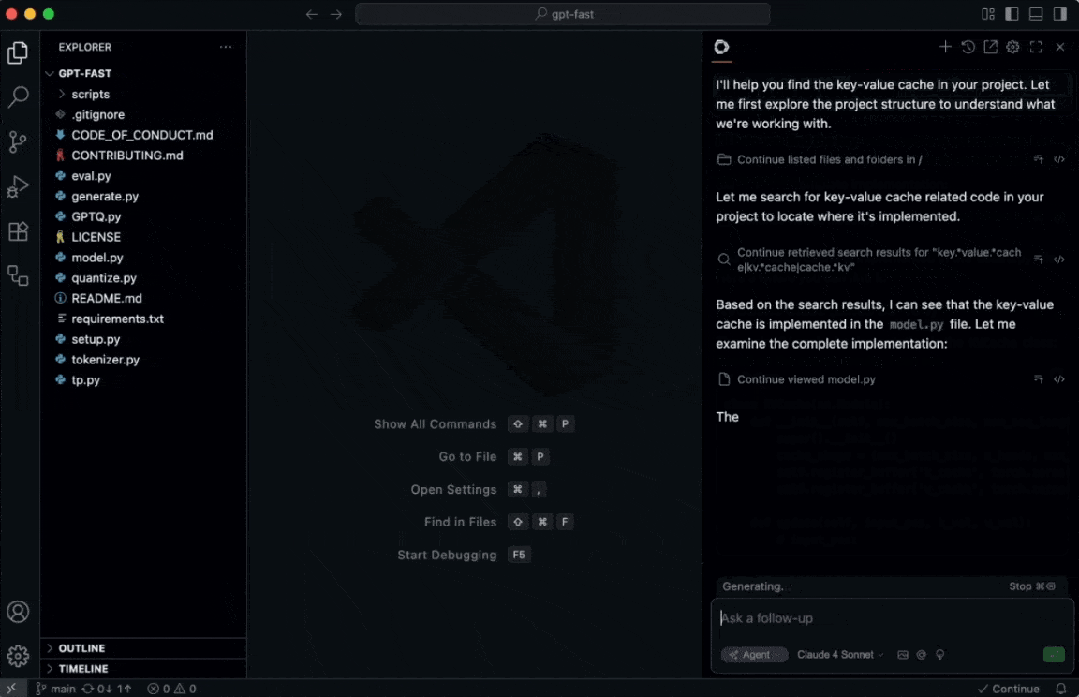
800 tokens 大概仅需 1.2 秒
🏭 企业应用场景:解决痛点的本地化方案
企业需要本地 AI 主机,本质上是为了解决云端服务的不确定性和传统服务器的高成本问题。
1. 数据孤岛与分析门槛
业务数据分散在 ERP、CRM 和 Excel 中,运营和销售团队通常不具备 SQL 编写能力。本地 AI 可以通过自然语言交互,自动生成 SQL、执行查询并生成图表,大大降低数据分析门槛。
2. 数据隐私安全
供应链、财务和定价策略等核心数据严禁上传公有云。本地部署确保数据全程不出局域网,彻底消除泄露风险。
3. 成本效益
传统 GPU 服务器采购成本高昂,且维护复杂。而“桌面级 AI 主机”能够以极低的成本实现类似的功能。
例如,运营人员只需输入:“帮我算华东地区近 30 天客单价环比”,本地模型即可自动完成 SQL 生成、数据提取、图表绘制和结论输出。
🎓 高校教学场景:人手一机的实践平台
传统 GPU 服务器在高校教学中面临贵、吵、资源抢占严重等问题。MS-S1 MAX 体积小、功耗低,完全可以实现每人一台的配置。
学生可以真正动手实践:
- 模型微调
- 图像识别
- RAG(检索增强生成)应用开发
- 本地推理优化
这才是高效的 AI 教学模式。
🧊 散热与噪音:出乎意料的稳定性

拆解后发现,其散热系统设计非常考究:
- 纯铜冷板配合六根热管,导热效率高。
- 双涡轮风扇提供强劲风压。
- 铝合金外壳辅助散热,风道贯穿前后。
实测显示,机器能长时间稳定在 130W 功耗下运行,短时间爆发可达 160W,且满载噪音控制在可接受范围内。
🧩 核心亮点:强大的多机集群能力
这是铭凡 MS-S1 MAX 最具潜力的功能——低成本构建 AI 集群。
双机集群:解锁 235B 模型

通过高速网络连接两台机器,即可运行 235B (Q4) 参数的大模型,且输出速度稳定,可用性极高。这意味着两台桌面设备就能承担以往需要大型服务器才能完成的任务。
四机集群:671B 模型的迷你机房

四台机器堆叠放入 2U 小机架,即可构建一个迷你 AI 数据中心,能够运行 DeepSeek 671B (Q4) 级别的超大模型。这套集群足以支撑企业知识库、多部门共享 AI 中心以及复杂的音视频 AI 处理工作流。
🆚 成本对比:MS-S1 MAX 集群 vs 传统 GPU 服务器
以常见的 5U RTX 5090 GPU 服务器 为对标对象,我们来算一笔账:

1. 功耗与电费
- MS-S1 MAX 四机集群:整机功耗约 0.72 kW。
- 5U RTX 5090 服务器:整机功耗约 4-5 kW。
按企业 7×24 小时运行,电费 1 元/kWh 计算:
- MS-S1 MAX 集群:约 ¥6,307 / 年
- 传统服务器:约 ¥39,420 / 年
- 结论:仅电费一项,每年可节省约 3.3 万元。
2. 采购成本
- MS-S1 MAX 四机集群:约 ¥68,000
- 5U RTX 5090 服务器:约 ¥300,000
- 结论:硬件采购成本降低约 77%。
3. 总拥有成本 (TCO) - 3年周期
- MS-S1 MAX 方案:¥68,000 (购置) + ¥18,921 (3年电费) ≈ ¥86,900
- 传统服务器方案:¥300,000 (购置) + ¥118,260 (3年电费) ≈ ¥418,260
巨大的成本差异表明,MS-S1 MAX 不仅仅是“便宜的替代品”,更是企业真正用得起、维护得起的 AI 基础设施。
🧾 总结
对于开发者,它让你摆脱云端 API 的束缚,实现本地高效开发;对于企业 IT 负责人,它提供了一种无需专业机房、低预算、高安全性的 AI 落地通过方案。
铭凡 MS-S1 MAX 是一台真正实现“桌面能放,企业能用,集群能扩,成本能控”的本地 AI 工作站。
 发表于 2025-12-12 19:54:56
|
查看: 296|
回复: 0
发表于 2025-12-12 19:54:56
|
查看: 296|
回复: 0
