在高并发系统的架构设计中,Redis 常常扮演着核心数据缓存与高速存储的角色,其支撑百万级并发请求的能力是其核心价值之一。本文将深入分析Redis实现高并发高性能的几个关键技术点。
核心之一:纯内存操作带来的极致速度
Redis将所有数据存储在内存(RAM)中,这一设计从根本上避免了传统数据库在数据读写时需要进行的磁盘I/O操作(如磁盘寻道、旋转等待)。内存的访问速度远高于磁盘,这使得Redis的响应时间能够达到毫秒甚至微秒级,为高并发处理奠定了速度基础。

核心之二:简洁高效的单线程模型
许多开发者对Redis的“单线程”模型存在误解。这里的“单线程”指的是其核心网络请求处理器和键值对读写操作是由一个主线程完成的。
这种设计的优势在于:
- 避免了线程切换和锁竞争的开销:多线程环境下,上下文切换和共享资源的锁管理会消耗大量CPU资源。Redis的单线程模型完全规避了这个问题,使得CPU时间可以更纯粹地用于处理命令。
- 顺序执行保证原子性:所有命令在主线程中顺序执行,每个命令在执行过程中都不会被其他命令打断,这天然保证了单个命令操作的原子性。
- 瓶颈不在于CPU:对于绝大多数操作是内存访问的Redis来说,性能瓶颈通常在于网络I/O而非CPU计算能力。一个高效的单线程足以在I/O等待时迅速切换处理其他已就绪的请求,从而充分利用CPU。

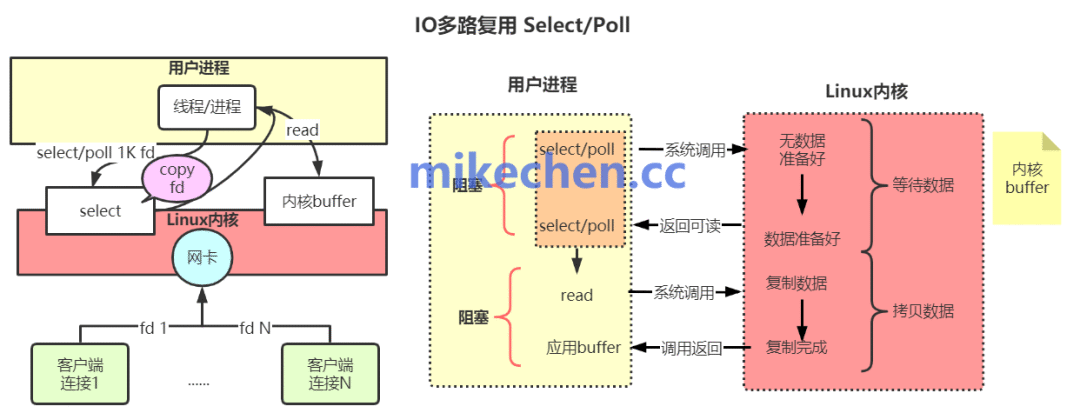
核心之三:I/O多路复用驾驭海量连接
单线程如何同时处理数万甚至十万级的并发连接?答案就是I/O多路复用技术(在Linux下通常使用epoll,Mac/BSD下使用kqueue)。
I/O多路复用是一种网络编程模型,它允许单个线程监听和管理大量的网络连接(Socket)。其工作流程如下:
- 主线程通过
epoll机制,将所有客户端连接注册到事件监听器中。
- 主线程阻塞在
epoll_wait调用上,等待事件(如某个Socket可读、可写)发生。
- 一旦有连接的数据准备就绪(例如客户端发送了一个命令请求),
epoll_wait就会返回,并通知主线程是哪些连接就绪。
- 主线程再顺序、非阻塞地处理这些就绪连接上的请求。
这样,单个线程无需为每个连接创建独立线程,也无需轮询所有连接,就能高效地处理海量并发,将CPU资源用在“刀刃”上。
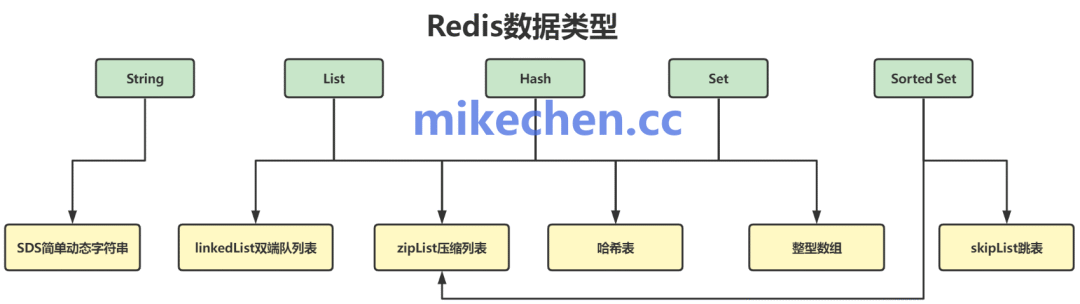
核心之四:精心设计的高效数据结构
性能不仅源于架构,也源于细节。Redis内部实现了多种高度优化的数据结构:
- 简单动态字符串 (SDS):兼容C字符串,同时能高效处理长度计算和追加操作。
- 哈希表 (Dict):使用渐进式Rehash解决扩容时的性能抖动问题。
- 跳跃表 (Skip List):用于实现有序集合 (Sorted Set),在维持元素有序的同时,支持平均O(log N)复杂度的查找、插入和删除。
- 压缩列表 (ZipList) / 快速列表 (QuickList):用于列表(List)等结构的底层实现,在节约内存和性能之间取得平衡。
这些数据结构的设计目标是让绝大多数操作(如GET、HSET、ZADD)的时间复杂度保持在O(1)或O(log N)级别,从算法层面保障了高性能。
总结
Redis的高并发能力并非源于复杂的多线程架构,而是通过纯内存存储、避免锁竞争的单线程核心、高效的I/O多路复用模型以及底层数据结构的极致优化这四大支柱共同构建的。这种设计在特定场景(数据量可容纳于内存、命令处理速度快)下,实现了性能、开发复杂度和系统稳定性的最佳平衡。理解这些原理,有助于我们在实际架构中更合理地使用和配置Redis,充分发挥其潜力。 |  发表于 2025-12-12 21:46:59
|
查看: 176|
回复: 0
发表于 2025-12-12 21:46:59
|
查看: 176|
回复: 0
