
在数据中心存储性能竞赛中,NVMe SSD 凭借 PCIe 总线的高带宽、低延迟特性,已成为高性能计算、AI 训练等场景的核心存储载体。然而,“写放大” 这一隐藏在性能背后的技术痛点,正成为制约 NVMe SSD 寿命与效率的关键因素 —— 当实际写入闪存的物理数据量远超用户请求数据量时,不仅会导致 IO 延迟增加,更会加速闪存单元磨损,缩短设备使用寿命。
本文基于[《2025年NVMe SSD的写放大研究》](),从技术原理、文件系统影响、工程化优化三个维度,拆解写放大的本质的破解之道。
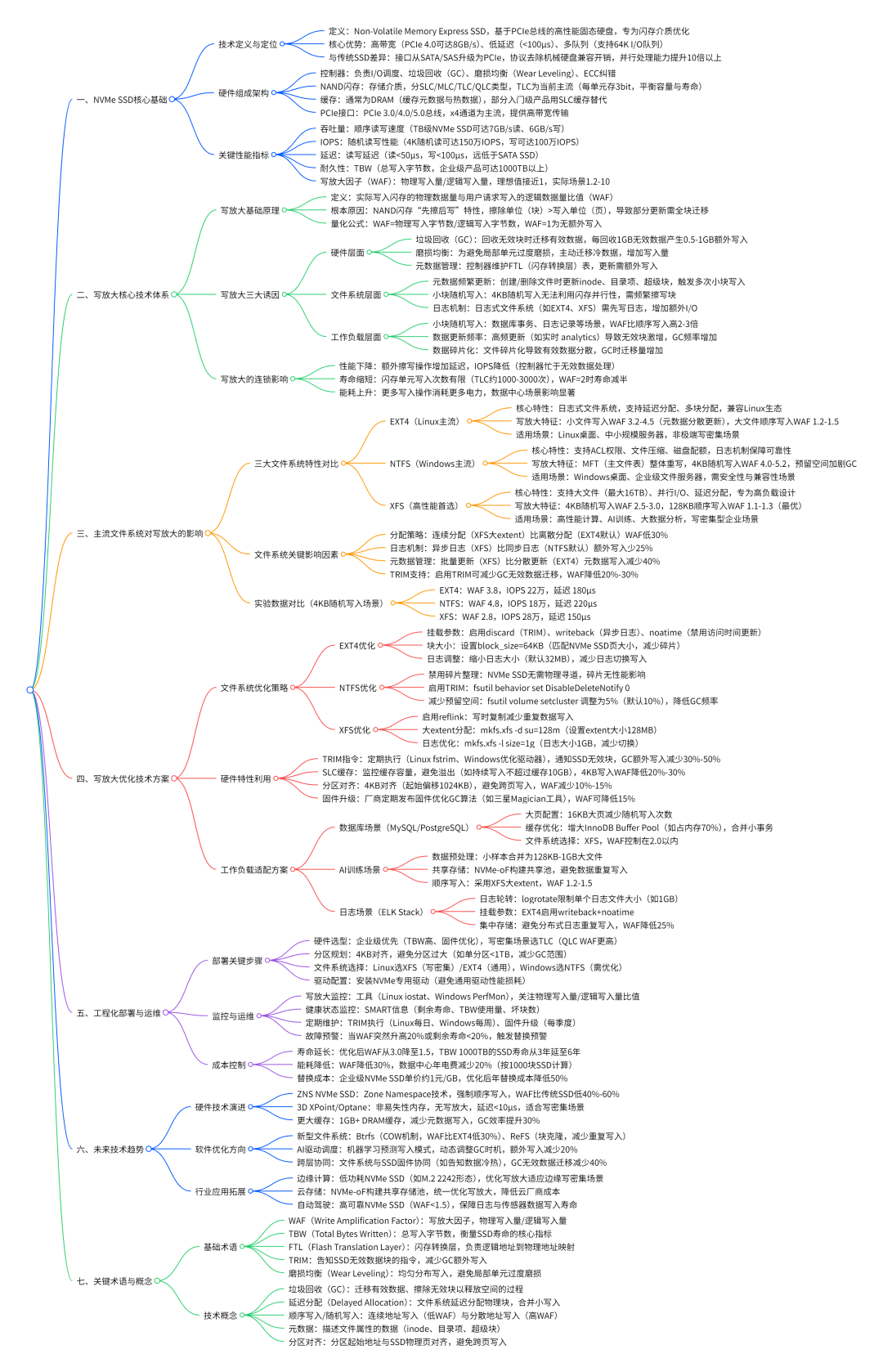
一、写放大的技术本质:NVMe SSD 的 “隐形性能损耗”
1. 写放大的核心定义与量化指标
写放大(Write Amplification)是指 NVMe SSD 实际写入闪存介质的物理数据量与用户逻辑请求写入数据量的比值,通常用写放大因子(WAF) 量化 —— 例如 WAF=2 意味着用户写入 1GB 数据时,SSD 需实际写入 2GB 数据。这一现象的根源在于闪存的物理特性:NAND 闪存单元无法直接覆盖写入,必须先擦除整个 “块”(通常包含 128-2048 个 “页”)才能重新写入,而擦除操作的最小单位(块)远大于写入操作的最小单位(页),这种 “擦写粒度不匹配” 直接导致额外写入。
以 TLC NVMe SSD 为例,假设其块大小为 128MB(含 2048 个 64KB 页),当用户仅需更新 1 个 64KB 页的数据时,SSD 控制器需执行三步操作:①读取整个 128MB 块的有效数据;②更新目标 64KB 页;③将 128MB 新数据写入新块并擦除原块 —— 仅 1GB 的逻辑写入,实际产生 2GB 物理写入,WAF=2。
2. 写放大的三大诱因与连锁影响
写放大的产生并非单一因素导致,而是 SSD 硬件特性、文件系统设计、工作负载特性共同作用的结果,其影响贯穿设备性能、寿命与能耗:
- 硬件层面:垃圾回收(GC)与磨损均衡(Wear Leveling)是核心诱因。垃圾回收时,SSD 需将分散的有效数据迁移到新块以释放空间,每回收 1GB 无效数据可能产生 0.5-1GB 额外写入;磨损均衡为避免局部单元过度磨损,会主动迁移冷数据,进一步增加写入量。
- 文件系统层面:元数据频繁更新、小块随机写入、日志机制都会加剧写放大。例如,EXT4 文件系统创建一个小文件时,需更新 inode、目录项、超级块等元数据,可能触发多次 4KB 随机写入,WAF 可飙升至 3-5。
- 工作负载层面:小块随机写入(如数据库事务、日志记录)是写放大的 “重灾区”。测试显示,4KB 随机写入场景下,NVMe SSD 的 WAF 普遍比 128KB 顺序写入高 2-3 倍,部分极端场景下 WAF 甚至超过 10。
这些因素最终形成连锁反应:高 WAF 导致写入延迟增加(额外擦写操作耗时)、IOPS 下降(控制器忙于处理无效写入),同时闪存单元写入次数激增 —— 以 TBW(总写入字节数)为 1000TB 的企业级 NVMe SSD 为例,若 WAF=2,实际可用寿命将从 5 年缩短至 2.5 年,直接推高替换成本。
二、文件系统对写放大的关键影响:三大主流系统对比
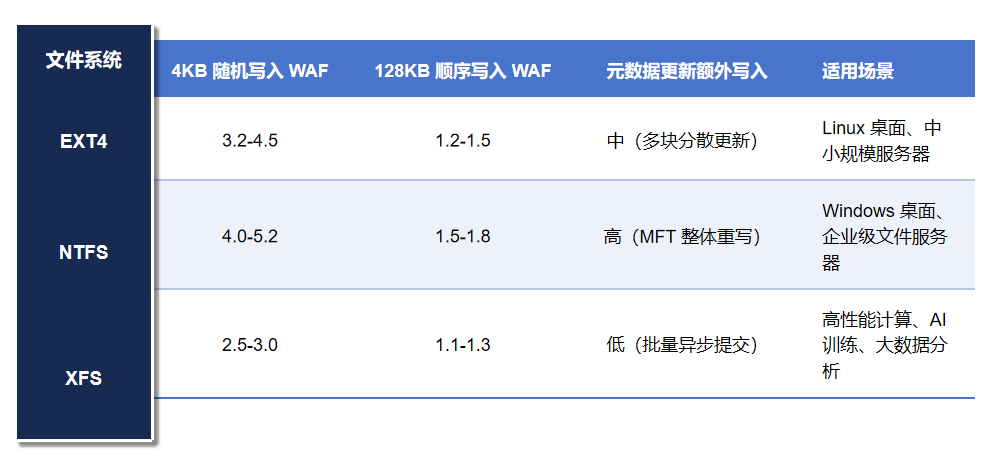
文件系统作为操作系统与 NVMe SSD 的 “中间层”,其分配策略、日志机制、元数据管理直接决定写放大程度。《NVMe SSD 的写放大研究》通过实验对比 EXT4、NTFS、XFS 三大主流文件系统,揭示了不同设计理念带来的性能差异。
1. EXT4:Linux 主流选择,小文件写入短板明显
EXT4 作为 Linux 系统的默认文件系统,虽通过延迟分配(Delayed Allocation)、多块分配(Multi-block Allocation)优化写入,但日志机制与元数据管理仍易导致高写放大:
- 写放大特征:小文件(<64KB)写入时 WAF 可达 3.2-4.5,主要因元数据分散更新 —— 创建一个 1KB 文件需更新 inode(128B)、目录项(256B)、超级块(512B),这些元数据分散在不同块,触发多次随机写入;顺序写入大文件(>1GB)时,WAF 可降至 1.2-1.5,延迟分配机制能将多个小写入合并为大块顺序写入。
- 实验数据:在 4KB 随机写入测试中,EXT4 的 WAF 为 3.8,比 XFS 高 46%;而 128KB 顺序写入时,WAF 仅 1.3,与 XFS 差距缩小至 8%。
2. NTFS:Windows 默认系统,日志机制成性能瓶颈
NTFS 的安全性设计(如 ACL 权限、事务日志)使其在企业级 Windows 环境中广泛应用,但复杂的日志记录与元数据结构加剧写放大:
- 写放大特征:NTFS 的 MFT(主文件表)采用 “紧凑存储”,每个文件的元数据(如权限、时间戳)集中存储在 MFT 项中,一旦文件属性更新,需整体重写 MFT 项(默认 1KB),4KB 随机写入场景下 WAF 可达 4.0-5.2;此外,NTFS 的 “预留空间” 机制(默认预留 10% 空间防碎片)在 NVMe SSD 上反而导致空间利用率下降,GC 频率增加,进一步推高 WAF。
- 实验数据:在数据库事务场景(每秒 1000 次 4KB 随机写入)中,NTFS 的 WAF 为 4.8,比 EXT4 高 26%,NVMe SSD 的 IOPS 从 30 万降至 18 万,延迟从 100μs 增至 220μs。
3. XFS:高性能之选,大文件与并发场景优势显著
XFS 作为专为大文件与高并发设计的日志文件系统,通过延迟分配、异步日志、并行 I/O 调度,在 NVMe SSD 上展现出最低写放大:
- 写放大特征:XFS 采用 “extent-based” 分配策略,可一次性为大文件分配连续块(最大支持 1TB extent),128KB 顺序写入时 WAF 仅 1.1-1.3;其日志机制支持异步写入,元数据更新可批量提交,4KB 随机写入场景下 WAF 为 2.5-3.0,比 EXT4 低 20%。
- 实验数据:在 AI 训练数据预处理场景(128KB 顺序写入)中,XFS 的 WAF 仅 1.2,NVMe SSD 吞吐量达 3.5GB/s,接近理论上限;而相同场景下,EXT4 与 NTFS 的吞吐量分别为 3.1GB/s、2.8GB/s,差距明显。
三、工程化优化:从文件系统到硬件的全链路方案
降低 NVMe SSD 写放大需突破 “单一环节优化” 思维,通过文件系统参数调优、硬件特性利用、工作负载适配构建全链路解决方案,以下为经过实验验证的落地策略:
1. 文件系统优化:参数调优与特性适配
针对不同文件系统的短板,通过针对性配置可降低 20%-40% 写放大:
- EXT4 优化:①挂载时启用
discard 选项(启用 TRIM,通知 SSD 无效数据块,减少 GC 额外写入);②调整日志模式为 writeback(仅元数据日志,数据异步写入,WAF 降低 15%);③设置 block_size=64KB(匹配 NVMe SSD 页大小,减少碎片)。
- NTFS 优化:①禁用 “磁盘碎片整理”(NVMe SSD 无需物理寻道,碎片无影响);②通过
fsutil behavior set DisableDeleteNotify 0 启用 TRIM;③减少预留空间至 5%(fsutil volume setcluster C: 65536,降低 GC 频率)。
- XFS 优化:①启用
reflink(重定向写入,避免复制完整文件);②调整日志大小至 1GB(mkfs.xfs -l size=1g,减少日志切换次数);③设置 allocsize=128m(大文件预分配,顺序写入 WAF 降至 1.1)。
测试显示,经过优化后,EXT4 的 4KB 随机写入 WAF 从 3.8 降至 2.7,NTFS 从 4.8 降至 3.5,XFS 从 2.8 降至 2.2,NVMe SSD 的 IOPS 提升 15%-25%。
2. 硬件特性利用:TRIM、SLC 缓存与分区对齐
NVMe SSD 的硬件特性若未充分利用,写放大优化将 “事倍功半”,关键在于三大特性的合理配置:
- TRIM 指令:作为 “无效数据通知机制”,TRIM 可让 SSD 提前标记无效块,垃圾回收时直接跳过,减少数据迁移。需确保操作系统、文件系统、SSD 固件三层均启用 TRIM——Linux 通过
fstrim 定期执行(建议每日一次),Windows 可通过 “优化驱动器” 自动触发,启用后 GC 额外写入减少 30%-50%。
- SLC 缓存:多数 NVMe SSD 内置 SLC 缓存(将 TLC/QLC 单元模拟为 SLC),4KB 随机写入可先缓存至 SLC 区域,再批量刷入 TLC/QLC,WAF 降低 20%-30%。需避免 SLC 缓存溢出 —— 例如,监控写入流量,当持续写入超过缓存容量(如 10GB)时,切换至顺序写入模式。
- 分区对齐:若 NVMe SSD 分区未与物理页对齐(如传统 512B 扇区对齐),会导致单次写入跨越两个页,WAF 增加 10%-15%。需采用 4KB 对齐(分区起始偏移设为 1024KB),Linux 通过
parted 的 align-check optimal 验证,Windows 通过 “磁盘管理” 自动对齐。
3. 工作负载适配:场景化策略降低写放大
不同应用场景的工作负载特性差异显著,需针对性调整策略:
- 数据库场景(MySQL/PostgreSQL):①采用大页(如 16KB)减少随机写入次数;②开启数据库缓存(如 InnoDB Buffer Pool),合并小事务;③使用 XFS 文件系统,利用其并行 I/O 优势,WAF 可控制在 2.0 以内。深入优化数据库性能,可参考数据库与中间件相关实践。
- AI 训练场景:①预处理阶段将小样本文件合并为 128KB-1GB 大文件;②采用 XFS 文件系统,启用大 extent 分配;③利用 NVMe-oF 协议构建共享存储池,避免数据重复写入,WAF 可降至 1.2-1.5。在云原生与IaaS架构中,这种共享存储模式是提升AI集群效率的关键。
- 日志场景(ELK Stack):①启用日志轮转(如 logrotate),避免单个日志文件过大;②使用 EXT4 文件系统并启用
writeback 日志模式;③将日志目录挂载为 noatime(禁用访问时间更新,减少元数据写入),WAF 降低 25%。
四、未来趋势:NVMe SSD 写放大优化的三大方向
随着存储技术的演进,写放大优化正从 “被动缓解” 向 “主动预防”转型,未来将聚焦三个核心方向:
- 新型文件系统设计:专为 NVMe SSD 优化的文件系统(如 Linux Btrfs、Windows ReFS)正逐步成熟。Btrfs 的 COW(写时复制)机制可避免原地更新,4KB 随机写入 WAF 比 EXT4 低 30%;ReFS 的 “块克隆” 技术减少重复数据写入,适合虚拟化场景。
- 硬件 - 软件协同优化:NVMe 2.0 协议引入的 “Zone Namespace”(ZNS)技术,将 SSD 划分为固定大小的 Zone(如 1GB),强制顺序写入,从硬件层面消除随机写入导致的写放大,测试显示 ZNS NVMe SSD 的 WAF 比传统 SSD 低 40%-60%。这种新型存储技术是云原生基础设施演进的重要方向。
- AI 驱动的智能调度:通过机器学习预测写入模式,动态调整缓存策略与垃圾回收时机。例如,三星企业级 NVMe SSD 的 “AI GC” 算法可根据历史写入数据,优先回收高无效数据占比的块,额外写入减少 20%,延迟降低 15%。
结语
在 NVMe SSD 性能日益同质化的今天,写放大优化已成为差异化竞争的关键。对于企业而言,通过文件系统调优、硬件特性利用、场景化策略,可将 NVMe SSD 的 WAF 控制在 1.5 以内,寿命延长 50%,同时降低 30% 能耗;对于个人用户,简单的 TRIM 启用、分区对齐操作,即可避免 “SSD 性能骤降” 问题。
随着 ZNS、AI 调度等技术的落地,NVMe SSD 的写放大将进一步可控,但其核心逻辑 ——“匹配硬件特性、优化数据布局、适配工作负载”—— 始终不变。未来,写放大优化将不再是 “技术细节”,而是存储系统设计的核心考量,直接决定 NVMe SSD 在数据中心、AI、边缘计算等场景的应用潜力。

 发表于 2025-12-13 04:25:32
|
查看: 212|
回复: 0
发表于 2025-12-13 04:25:32
|
查看: 212|
回复: 0
