将大型语言模型(LLM)部署至边端设备是推动AI应用落地的关键,它需要在保持模型能力的同时,满足边缘场景对功耗、延迟、体积和安全性的严苛要求。目前,相关技术已日趋成熟,本文将从核心原则到工具链,系统性地介绍边端大模型的部署流程。
一、核心原则:为边缘重构模型
边端部署并非简单地将云端模型“搬运”下来,其核心思想是“为边缘重构模型”。这意味着我们需要根据边缘设备的算力、内存和功耗限制,对模型进行专项的选型、压缩和优化,而非直接使用为云端设计的庞大模型。
二、四步部署流程
1. 明确边缘场景需求
不同的应用场景对模型的要求差异巨大。在技术路线的起点,必须首先明确场景需求。下表梳理了典型场景的设备与模型方案推荐:
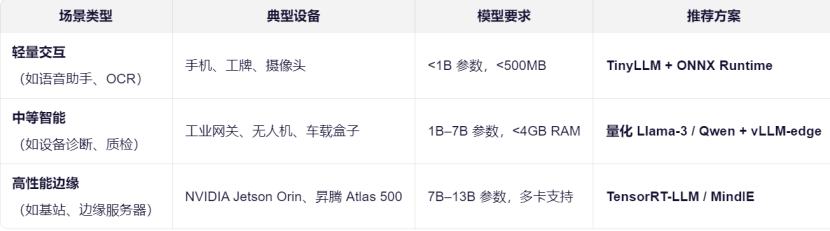
如图表所示,从轻量交互(如语音助手)到中等智能(如设备诊断),再到离线分析(如日志审计),所需的模型参数量和推荐技术栈各不相同,这直接决定了后续的选型方向。
2. 模型选择与优化压缩
在明确需求后,选择合适的基础模型并进行极致压缩是成败的关键。
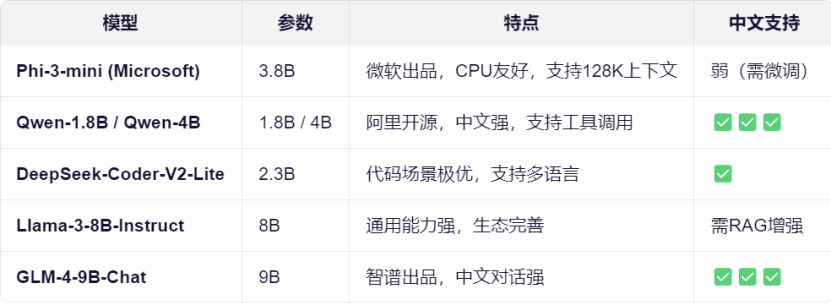
主流通用小模型选型:
当前社区涌现出多个优秀的轻量化基础模型,它们为边端部署提供了良好的起点。
选择合适的模型后,必须应用模型压缩技术,这是边端部署的“必选项”。
核心压缩技术组合:
量化、知识蒸馏和剪枝是当前最有效的模型“瘦身”手段,通常组合使用以达到最佳效果。
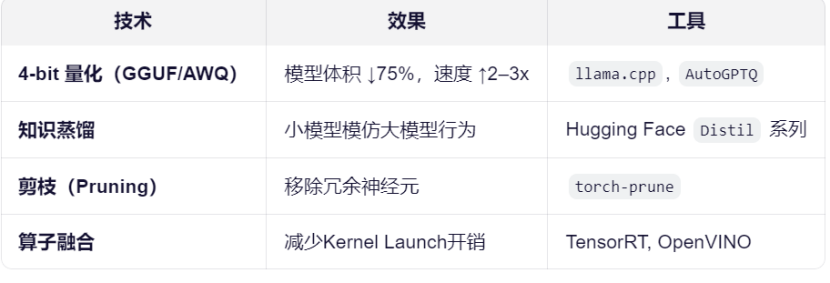
以最常用的4-bit量化为例,它可以显著减少模型体积并提升推理速度,是边端AI部署中的关键技术。
3. 推理引擎选型
模型最终需要通过推理引擎在硬件上执行。选择与硬件匹配的引擎,才能释放最大性能。
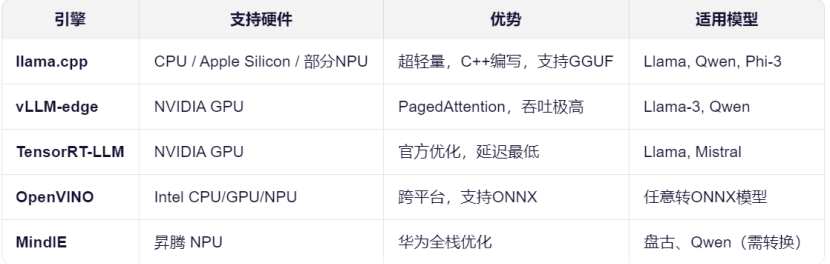
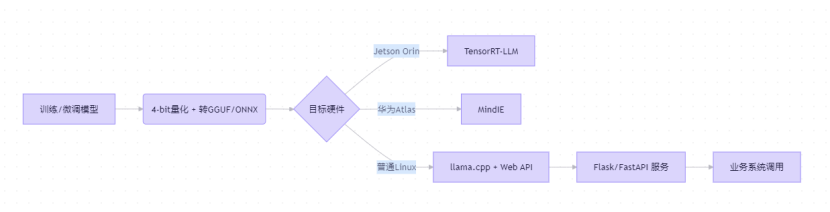
例如,对于通用CPU环境,llama.cpp 因其超轻量和高效而成为首选;对于 NVIDIA Jetson 等设备,则需使用针对其 GPU 优化的 TensorRT-LLM。
4. 部署与监控
部署并非终点,持续的监控与维护至关重要。
部署流程概览:
一个完整的部署流程通常包括模型准备、格式转换、针对目标硬件优化以及服务封装等步骤。
关键监控要点:
- 内存占用:确保常驻内存低于物理内存的80%。
- 温度/功耗:工业设备需严格监控芯片温度与功耗,避免超限。
- QPS/延迟:设置熔断与降级机制,例如当单次请求延迟超过500ms时自动切换至轻量模式或返回缓存。
- 模型更新:支持安全的OTA(空中下载)远程升级,实现模型的迭代与修复。
三、典型硬件平台性能参考
不同硬件平台的算力、内存和功耗决定了其所能承载的模型规模和性能表现。下表对比了几种常见边缘设备的实测能力:
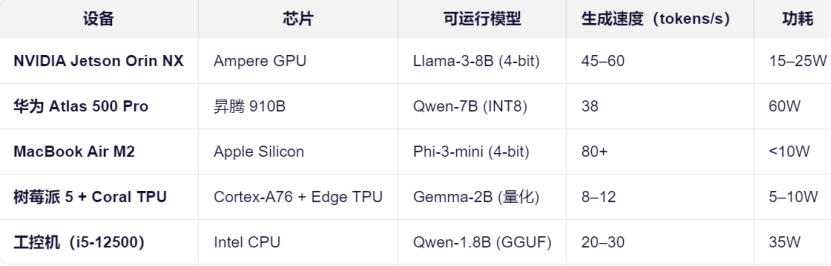
选择合适的硬件需要综合考量成本、算力需求及部署环境。例如,树莓派5适合极轻量级应用,而Jetson Orin则能承载更大的模型以实现更复杂的推理任务。
四、开源工具链推荐
工欲善其事,必先利其器。一套顺手的工具链能极大提升边端模型部署的效率。

从量化转换到本地推理,再到服务封装,上表中的工具覆盖了部署全链路。例如,使用 ollama 可以一行命令快速启动并测试模型;而使用 FastAPI 或 Flask 封装成Web API,则是集成到业务系统中的常用方式,配合 Nginx 等组件可以更好地管理服务与负载。 |  发表于 2025-12-14 06:28:20
|
查看: 263|
回复: 0
发表于 2025-12-14 06:28:20
|
查看: 263|
回复: 0
