近日,腾讯混元团队正式开源了新一代机器翻译模型 Tencent-HY-MT1.5 ,并同步上线混元官网、GitHub 以及 Hugging Face。该系列模型主打 高质量、多语言、端侧可部署 ,在翻译效果与工程落地之间取得了较好的平衡,受到开发者社区关注。
一、模型概览:两种规模,覆盖端侧与云端
Tencent-HY-MT1.5 系列当前主要包含两个版本:
- HY-MT1.5-1.8B
- HY-MT1.5-7B
两者均为 专用机器翻译模型 ,而非通用对话大模型,整体架构围绕翻译任务深度优化。
1️⃣ HY-MT1.5-1.8B
这是一个面向 端侧部署 的轻量版本,参数规模约 18 亿,重点优化推理效率与内存占用,可运行在移动端或边缘设备上。
2️⃣ HY-MT1.5-7B
该版本参数规模约 70 亿,定位为 高质量翻译基座模型 ,在翻译准确率、语义完整性与复杂句式处理方面表现更强,是此前 WMT 国际机器翻译评测冠军模型的升级版本。
二、多语言覆盖:不仅是中英互译
在语言支持方面,Tencent-HY-MT1.5 并未局限于常见语种:
- 支持 33 种主流国际语言互译
- 支持 5 种中国少数民族语言 / 方言
- 覆盖多种低资源语言与小语种
整体语言范围涵盖:
- 中、英、日、法、德等主流语言
- 捷克语、马拉地语、爱沙尼亚语、冰岛语等小语种
这使其在 跨境内容、本地化服务、政企翻译 等场景中具备更高适用性。
三、端侧部署能力:1.8B 模型是重点
Tencent-HY-MT1.5 的一大亮点,在于 端侧翻译能力的实用性 。
✅ 内存与推理效率
- 1.8B 模型在量化后, 内存占用约 1GB
- 在消费级设备上即可运行
- 50 tokens 推理耗时约 0.18 秒
这一指标在同类翻译模型中具有较强竞争力,尤其适合:
✅ 支持多种量化格式
官方在 Hugging Face 上提供了 GGUF 等量化权重 ,方便直接接入本地推理框架,降低部署门槛。
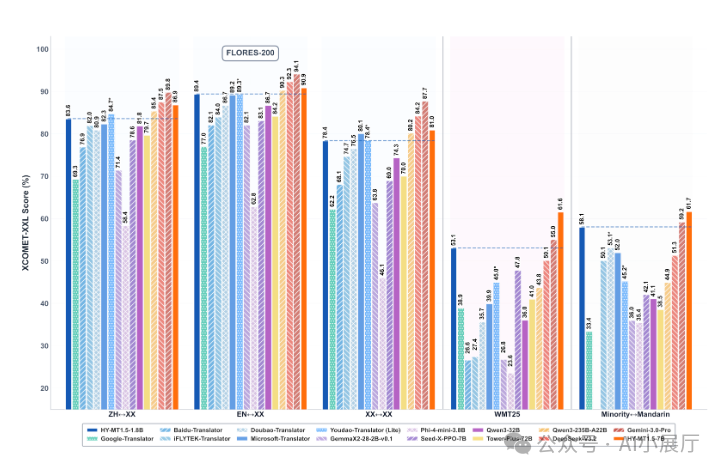
四、翻译质量:接近大型闭源模型水平
在公开评测中,Tencent-HY-MT1.5 在多个权威翻译基准上表现稳定:
其中:
- 1.8B 模型 在翻译质量上已接近部分大型闭源模型的主流水平
- 7B 模型 在复杂句、长文本与专业语境下表现更稳健
整体来看,腾讯在 模型体量与翻译质量之间 做了较为务实的权衡。
五、实用工程特性:面向真实翻译场景
Tencent-HY-MT1.5 并非只关注模型指标,也强化了多个工程级能力。
✔ 术语干预机制
支持用户自定义术语表,适用于法律、医疗、科技等专业领域,确保关键术语不被误译。
✔ 上下文感知翻译
模型具备一定的上下文理解能力,可用于 多轮文本或长文档翻译 ,减少前后语义不一致问题。
✔ 格式保留能力
在翻译过程中可尽量保持原始文本结构,适合 HTML、技术文档等内容的翻译需求。
六、训练策略:小模型并非“简单裁剪”
在 1.8B 模型训练中,腾讯采用了 On-Policy Distillation(策略蒸馏) 方法:
- 由 7B 大模型实时指导小模型训练
- 小模型学习的是大模型的预测分布,而非固定答案
- 有助于提升泛化能力与低资源语言表现
这也是 1.8B 模型在体量受限情况下仍能保持较高翻译质量的重要原因。
七、开源与生态支持
目前 Tencent-HY-MT1.5 已完整开源,资源齐全:
- 混元官网 :模型展示与能力介绍
- GitHub :源码、模型配置、推理示例
- Hugging Face :权重下载、量化版本、社区生态
模型可通过 transformers 直接加载,也支持接入 vLLM 等推理框架,适合快速构建翻译服务。对于想要深入实践或学习这类前沿 开源实战 项目的开发者来说,这提供了绝佳的机会。
Github 链接:https://github.com/Tencent-Hunyuan/HY-MT
HuggingFace 链接:https://huggingface.co/collections/tencent/hy-mt15
从此次开源可以看出,大厂正将成熟的 人工智能 技术以更易用的形式推向社区。模型的工程化特性,如端侧部署和术语干预,直接回应了真实业务需求。如果你对这类实用的技术进展感兴趣,欢迎在 云栈社区 与我们一同探讨。
 发表于 2026-1-3 12:08:29
|
查看: 222|
回复: 0
发表于 2026-1-3 12:08:29
|
查看: 222|
回复: 0
