Sebastian Raschka 近期大幅更新了他的「大型语言模型架构对比」长文,新增内容使其成为2025年迄今为止最全面的技术解析之一。本文基于其更新,旨在清晰梳理当今主流开源大型语言模型的核心架构演进与设计差异。

从最初的GPT架构至今已过去七年。回顾GPT-2(2019),再展望DeepSeek V3与LLaMA 4(2024-2025),人们或许会惊讶于这些模型在结构上仍然高度相似。当然,细节处有诸多改进:位置编码从绝对编码演变为旋转位置编码(RoPE),多头注意力(MHA)很大程度上被分组查询注意力(GQA)取代,激活函数也换成了更高效的SwiGLU。但在这些渐进式优化之下,我们是否看到了突破性的变革?
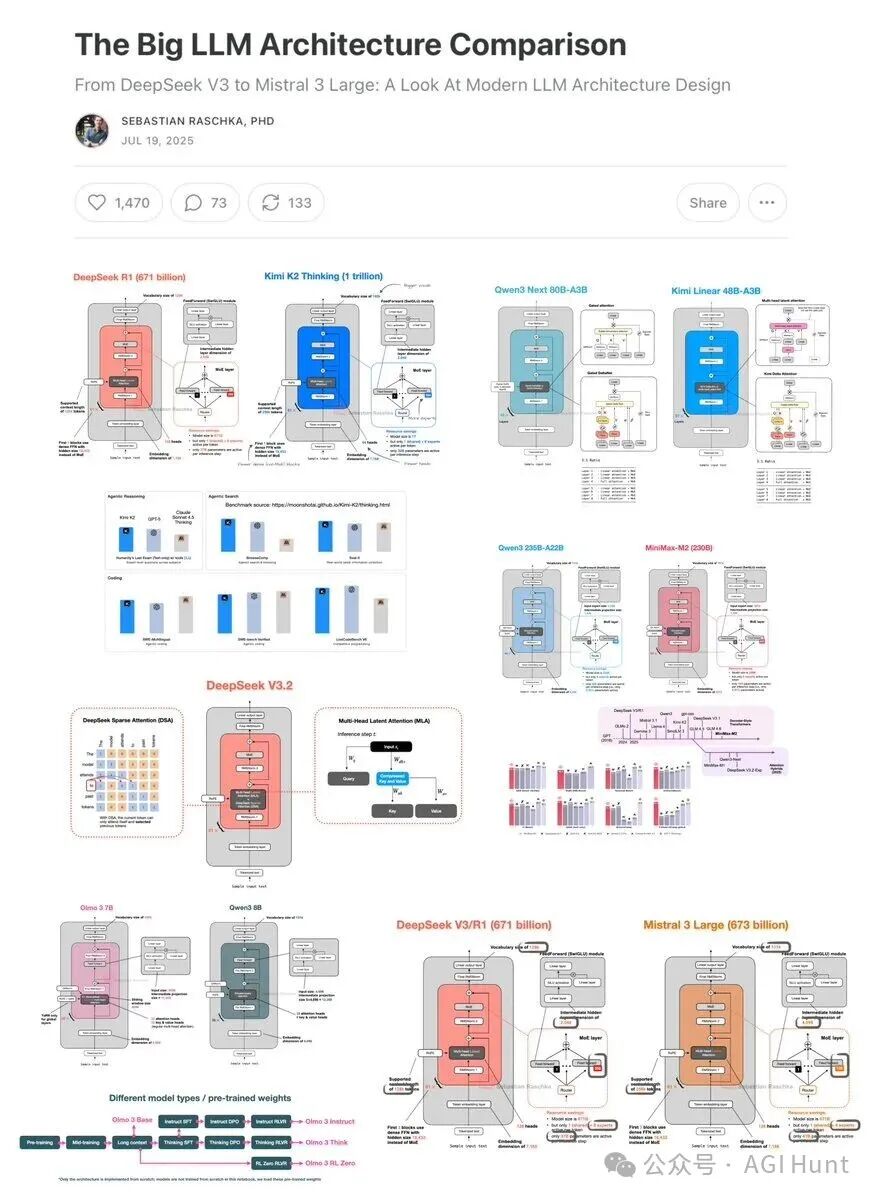
比较大型语言模型的性能归因异常困难:数据集、训练技术和超参数的差异巨大且往往记录不全。然而,剖析架构本身的结构变化依然极具价值,它能揭示2025年开发者们的设计共识与探索方向。(本文涵盖的部分模型架构如图1所示。)
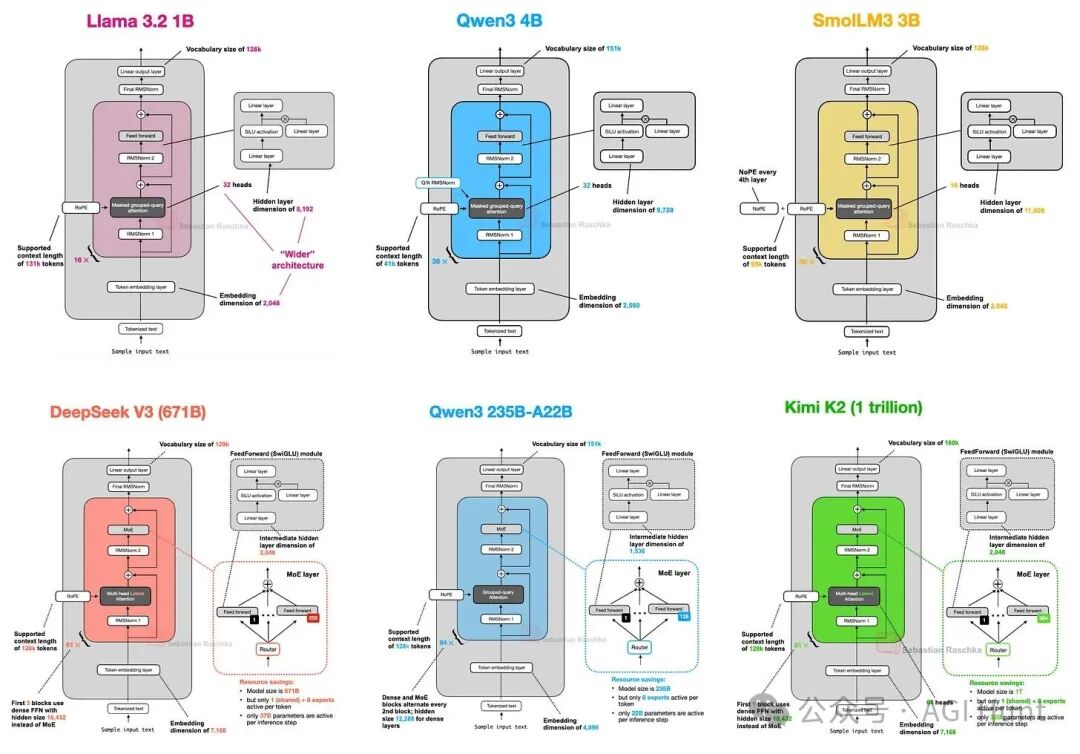
图 1:本文涵盖的一部分架构。
因此,本文将专注于定义当今旗舰开源模型架构的技术发展,而非讨论基准性能或训练算法。
(提示:本文内容较为全面,建议利用导航栏访问目录。)
DeepSeek V3/R1
DeepSeek R1 在2025年1月发布时产生了巨大影响。DeepSeek R1 是一个基于 DeepSeek V3 架构构建的推理模型,该架构于2024年12月推出。虽然重点在2025年,但包含DeepSeek V3是合理的,因其随R1的发布而获得广泛关注。
本节将重点介绍DeepSeek V3中两项提升计算效率的关键架构技术:
- Multi-Head Latent Attention (MLA)
- Mixture-of-Experts (MoE)
Multi-Head Latent Attention
在讨论MLA前,先回顾一下背景。近年来,分组查询注意力(GQA)已成为MHA的高效替代品。GQA的核心是通过让多个查询头共享同一组键和值投影来减少内存使用。
例如,图2显示,若有2个键值组和4个注意力头,则头1和2共享一组键值,头3和4共享另一组。这减少了键值计算总量,从而降低了内存使用并提升了效率,且根据消融研究,对建模性能影响甚微。
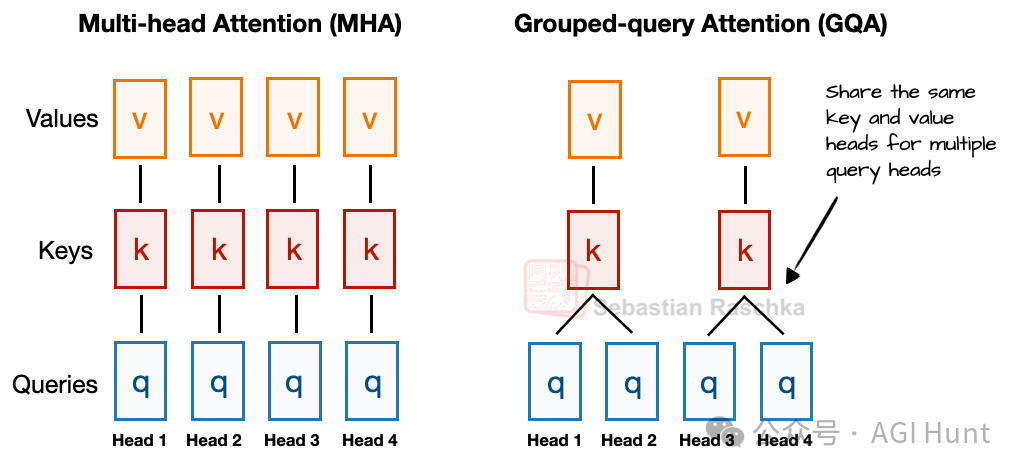
图 2:MHA和GQA的比较(组大小为2)。
而Multi-Head Latent Attention (MLA) 则提供了一种不同的内存节省策略,尤其适合与KV缓存配合使用。MLA不像GQA那样共享键值头,而是在将键值张量存入KV缓存前,将其压缩到低维空间。推理时,这些压缩的张量在使用前被投影回原始大小,如图3所示。这增加了一次额外的矩阵乘法,但显著减少了内存占用。
MLA并非全新概念,其前身DeepSeek-V2就已使用。V2论文中的消融研究(图4)解释了为何选择MLA而非GQA:GQA的性能似乎弱于MHA,而MLA则提供了优于MHA的建模性能。
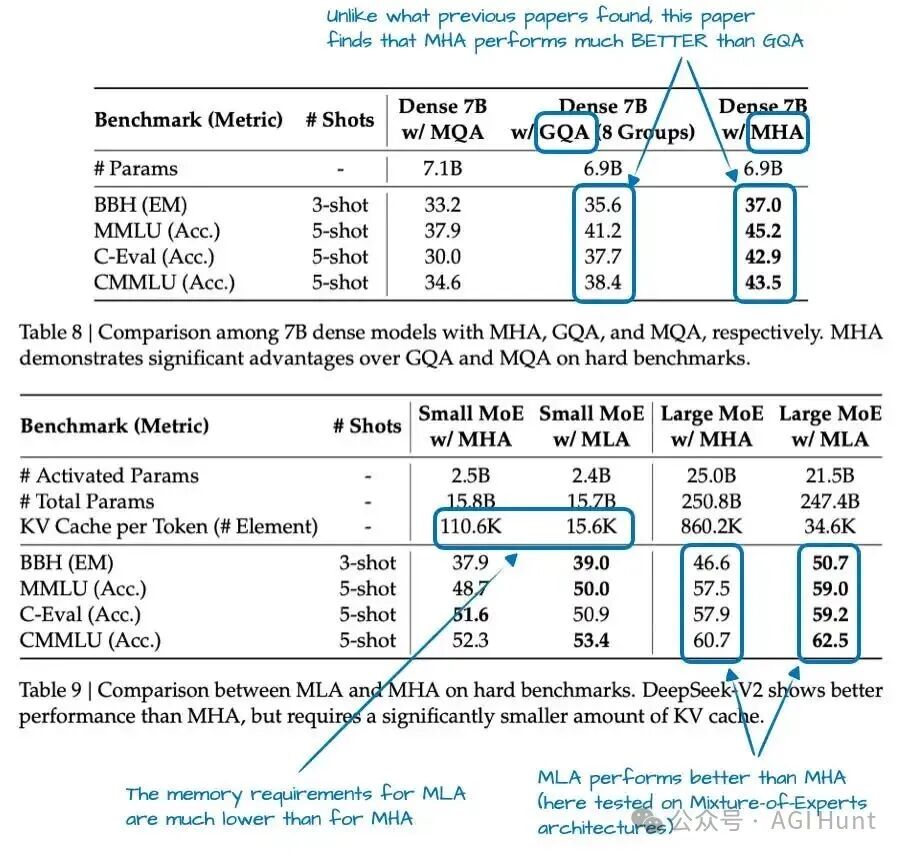
图 4:来自 DeepSeek-V2 论文的注释表格。
总结来说,MLA是一个巧妙的技巧,可在减少KV缓存内存使用的同时,在建模性能上甚至略优于MHA。
Mixture-of-Experts
DeepSeek另一个主要架构组件是使用混合专家(MoE)层。MoE的核心思想是用多个专家层(每个本身也是一个前馈模块)替换Transformer块中的单个前馈模块,如图5所示。

图 5:DeepSeek V3/R1 中的 MoE 模块(右)与标准前馈模块(左)的对比。
Transformer块中的前馈模块通常包含模型的大部分参数。用多个前馈块替换单个块会急剧增加总参数量。但关键技巧在于,并非每个token都使用所有专家。路由器仅为每个token选择一小部分专家。因此,MoE模块被称为稀疏模块,与始终使用全参数集的密集模块相对。
例如,DeepSeek V3每个MoE模块有256个专家,总参数量达6710亿。但在推理时,每次只有9个专家被激活(1个共享专家 + 8个路由选择的专家)。这意味着每个推理步骤仅使用370亿参数,而非全部6710亿。
DeepSeek V3的MoE设计一个显著特点是使用了共享专家,即一个始终为每个token激活的专家。这一概念在DeepSpeed-MoE等论文中被提出,其好处在于常见模式可由共享专家学习,从而让其他专家更专注于专业化模式。
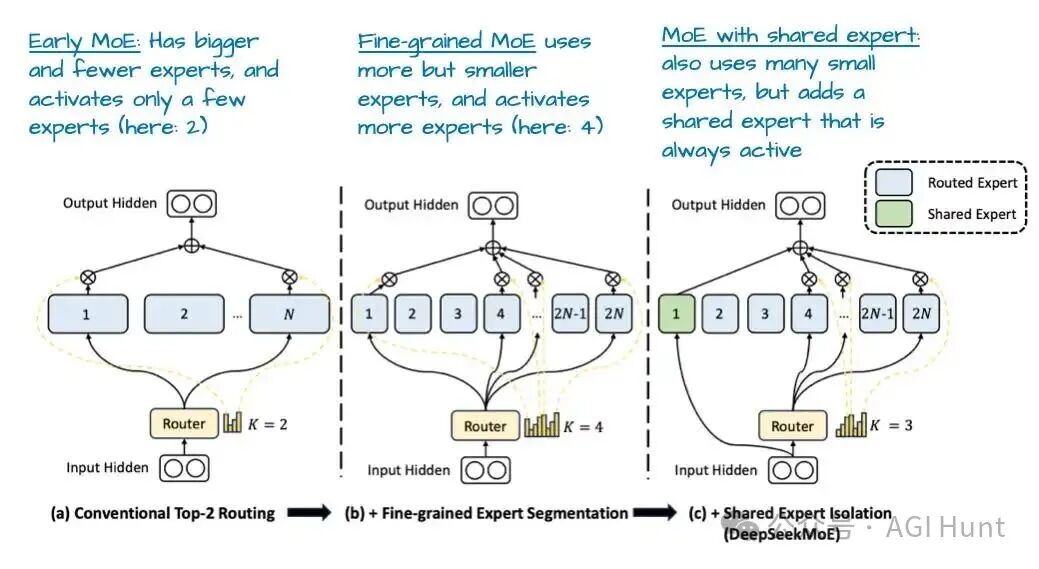
图 6:来自 DeepSeekMoE 论文的注释图。
总而言之,DeepSeek V3是一个庞大的6710亿参数模型,在发布时其性能优于其他开源权重模型。尽管体积庞大,但由于MoE架构,其在推理时效率更高(仅激活370亿参数)。另一个关键区别是使用MLA而非GQA,MLA和GQA都是MHA的高效推理替代方案,而MLA据研究能提供更好的建模性能。
OLMo 2
Allen Institute for AI的OLMo系列模型因其在训练数据和代码方面的透明度以及相对详细的技术报告而备受关注。虽然OLMo模型可能不在排行榜顶端,但其设计干净透明,是理解大型语言模型(LLM)开发的优秀蓝图。
在发布时(早于LLaMA 4、Gemma 3和Qwen 3),OLMo 2模型位于计算性能的帕累托前沿,如图7所示。
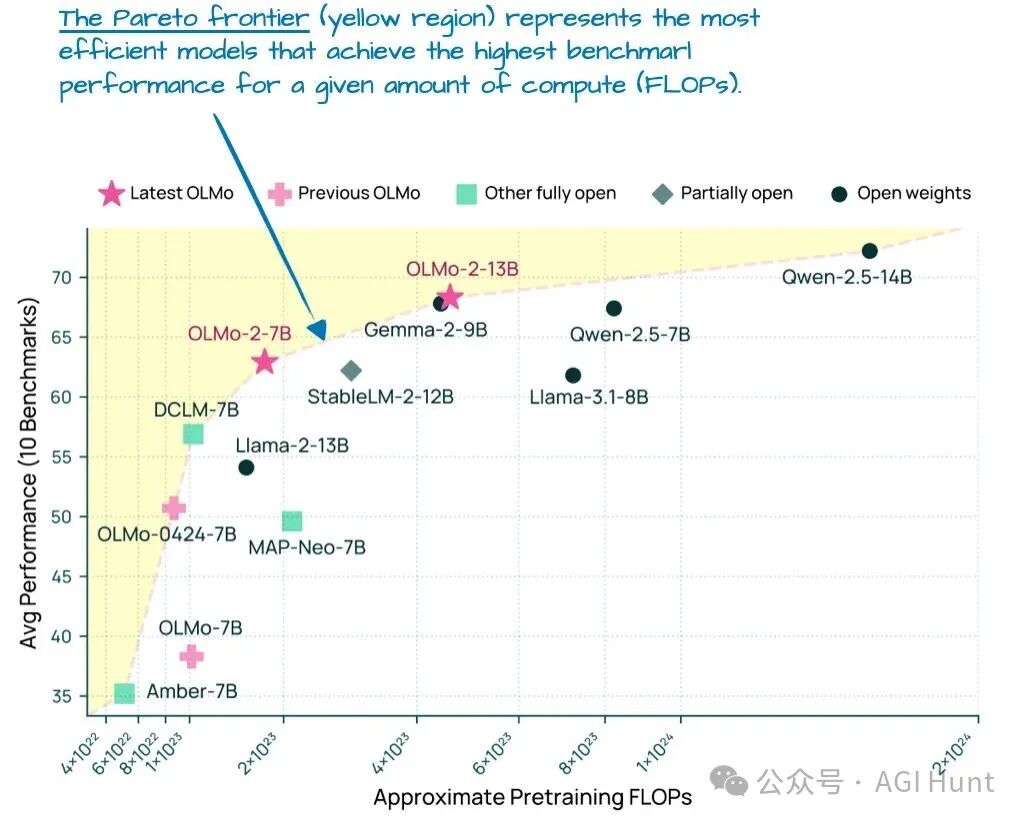
图 7:不同LLM的建模性能与预训练成本对比(来自OLMo 2论文)。
OLMo 2中有趣的架构设计选择主要围绕归一化:RMSNorm层的放置以及QK-Norm的添加。值得注意的是,OLMo 2仍然使用传统的MHA,而非MLA或GQA。
RMSNorm 的放置
与大多数现代LLM一样,OLMo 2使用RMSNorm而非LayerNorm。但关键在于RMSNorm层的放置位置。
原始Transformer采用后归一化(Post-Norm),即在注意力和前馈模块之后进行归一化。而GPT及之后许多模型采用前归一化(Pre-Norm),将归一化层放在模块之前,这有助于训练稳定性。
OLMo 2采用了一种后归一化(Post-Norm)形式,但归一化层仍在残差连接内部,如图8所示。这种改变旨在提升训练稳定性(见图9)。
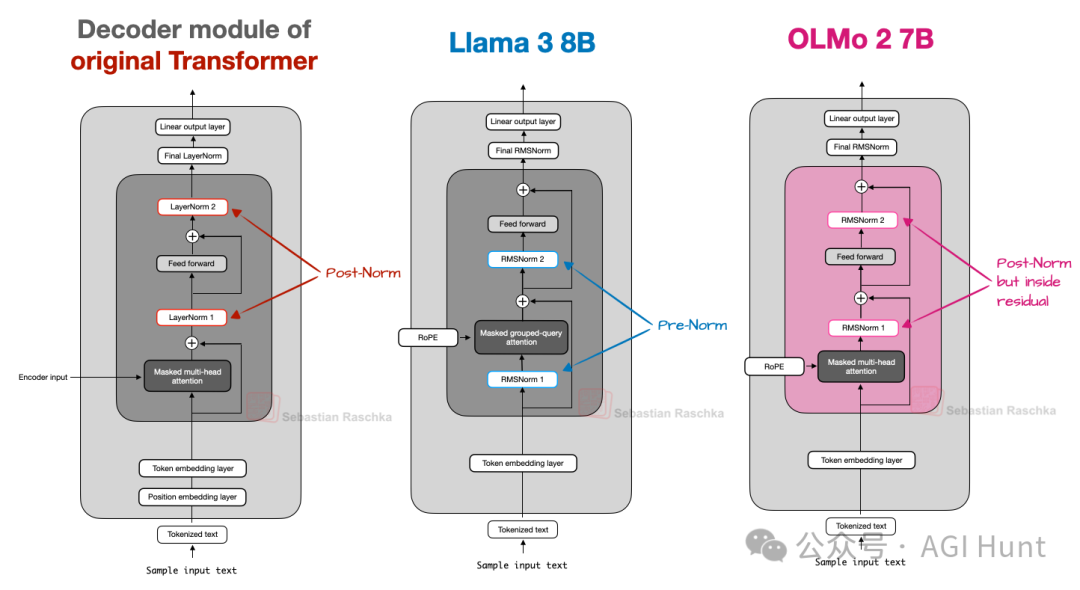
图 8:Post-Norm、Pre-Norm 和 OLMo 2 的 Post-Norm 风格比较。
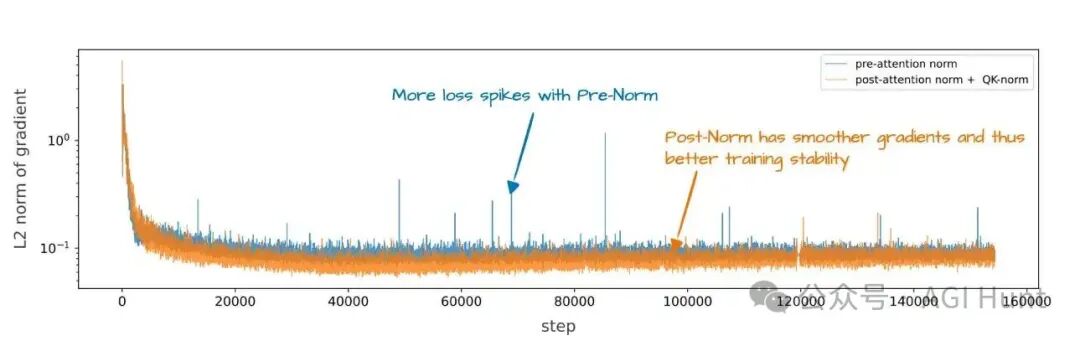
图 9:Pre-Norm 与 OLMo 2 的 Post-Norm 风格对训练稳定性的影响。
QK-Norm
QK-Norm本质上是另一个RMSNorm层。它被放置在MHA模块内部,在应用RoPE之前分别应用于查询(q)和键(k)。以下代码片段展示了其在GQA层中的应用方式(OLMo中的MHA类似):
class GroupedQueryAttention(nn.Module):
def __init__(
self, d_in, num_heads, num_kv_groups,
head_dim=None, qk_norm=False, dtype=None
):
# ...
if qk_norm:
self.q_norm = RMSNorm(head_dim, eps=1e-6)
self.k_norm = RMSNorm(head_dim, eps=1e-6)
else:
self.q_norm = self.k_norm = None
def forward(self, x, mask, cos, sin):
b, num_tokens, _ = x.shape
# Apply projections
queries = self.W_query(x)
keys = self.W_key(x)
values = self.W_value(x)
# ...
# Optional normalization
if self.q_norm:
queries = self.q_norm(queries)
if self.k_norm:
keys = self.k_norm(keys)
# Apply RoPE
queries = apply_rope(queries, cos, sin)
keys = apply_rope(keys, cos, sin)
# Expand K and V to match number of heads
keys = keys.repeat_interleave(self.group_size, dim=1)
values = values.repeat_interleave(self.group_size, dim=1)
# Attention
attn_scores = queries @ keys.transpose(2, 3)
# ...
QK-Norm与Post-Norm一同作用,稳定了训练。QK-Norm并非OLMo 2首创,其概念可追溯至更早的视觉Transformer研究。
简言之,OLMo 2的主要架构决策在于RMSNorm的放置方式:采用后归一化风格,并在注意力机制内为查询和键添加RMSNorm(QK-Norm),二者共同促进训练稳定。
图10对比了OLMo 2与LLaMA 3的架构,可见除了OLMo 2使用传统MHA外,二者在其他方面较为相似。
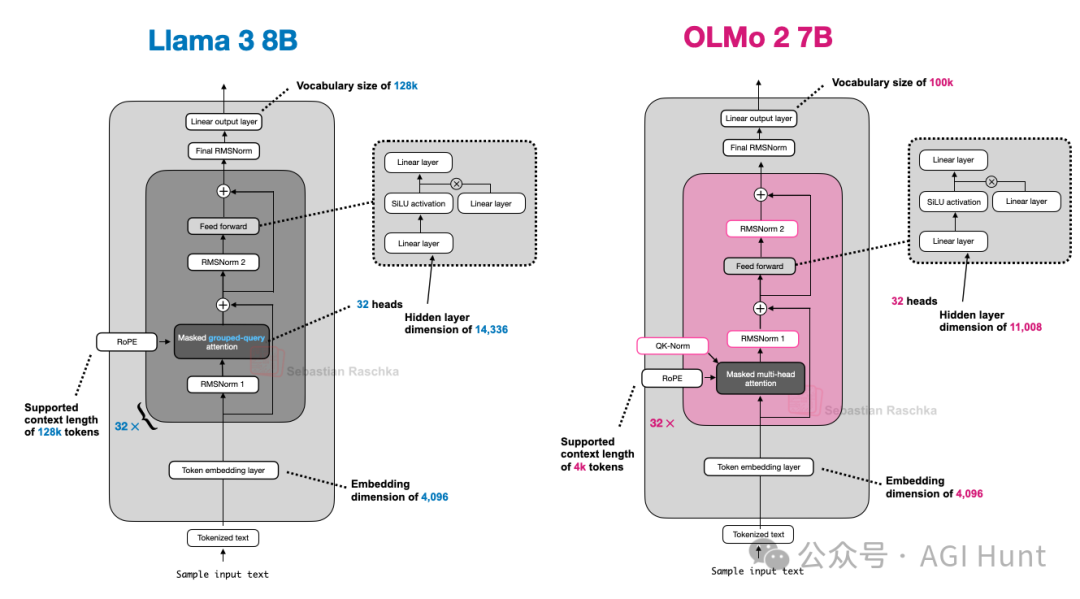
图 10:LLaMA 3 与 OLMo 2 的架构比较。
Gemma 3
Google的Gemma模型一直表现出色。Gemma 3采用了不同的“技巧”来降低计算成本:滑动窗口注意力。
通过滑动窗口注意力(最初在LongFormer中引入,Gemma 2也已使用),Gemma 3团队能够大幅减少KV缓存的内存需求,如图11所示。
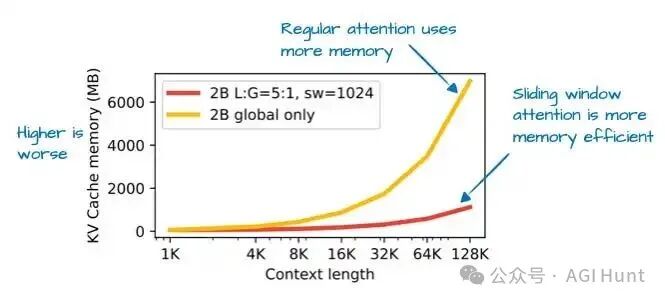
图 11:滑动窗口注意力带来的KV缓存内存节省(来自Gemma 3论文)。
滑动窗口注意力是一种局部注意力机制。它将当前查询位置的上下文窗口限制在附近区域,而非像常规注意力那样关注所有token(全局注意力),如图12所示。
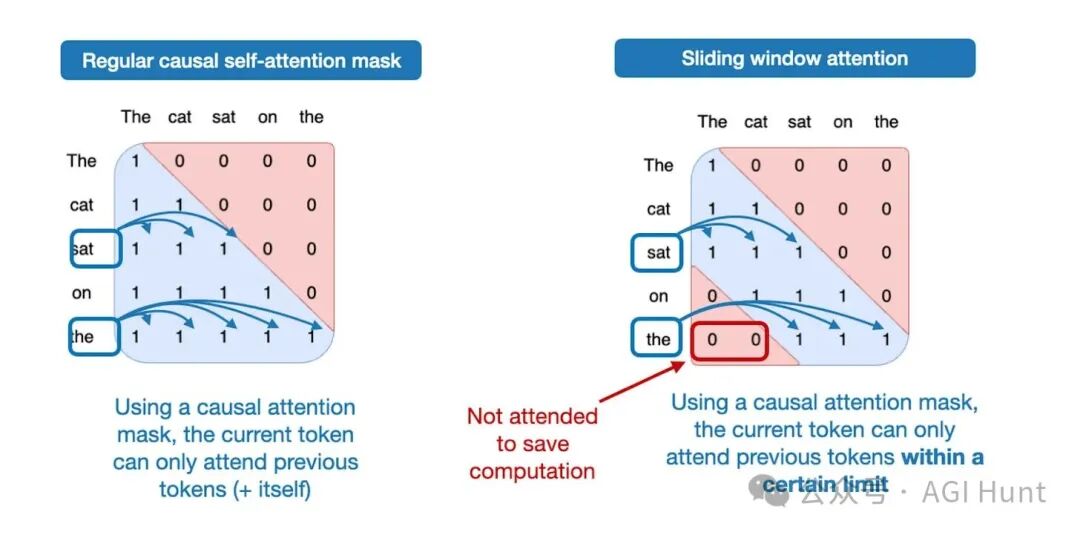
图 12:常规全局注意力(左)与滑动窗口局部注意力(右)的比较。
滑动窗口注意力可与MHA或GQA结合使用;Gemma 3使用的是分组查询注意力(GQA)。
Gemma 3与Gemma 2的不同之处在于调整了全局注意力与局部注意力的比例。Gemma 2以1:1的比例混合滑动窗口与全局注意力。而Gemma 3的比例为5:1,即每5个滑动窗口注意力层才有1个全局注意力层,并且滑动窗口大小从4096减至1024,将计算焦点转向更高效的本地化处理。
根据消融研究,使用滑动窗口注意力对建模性能影响很小,如图13所示。

图 13:滑动窗口注意力对输出困惑度的影响甚微(来自Gemma 3论文)。
另一个细节是,Gemma 3在其GQA模块周围同时使用了Pre-Norm和Post-Norm设置的RMSNorm(见图14)。这不同于原始Transformer的Post-Norm、GPT-2的Pre-Norm或OLMo 2的Post-Norm风格,可视为兼得两者之长的设计。
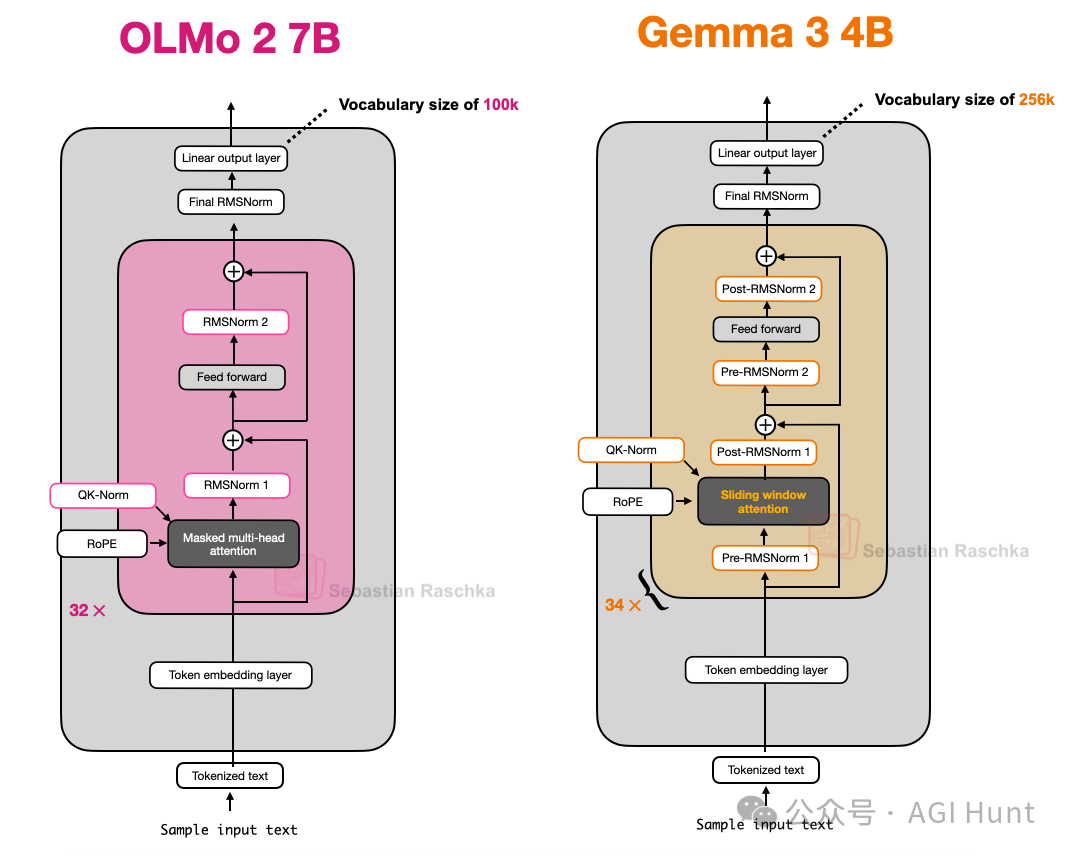
图 14:OLMo 2 与 Gemma 3 的架构比较(注意Gemma 3中的额外归一化层)。
总结,Gemma 3是一个性能优异的开源模型,其最显著的特点是使用滑动窗口注意力提升效率,并采用了独特的归一化层放置方式。
Mistral Small 3.1 24B
Mistral Small 3.1 24B在多个基准测试(数学除外)上优于Gemma 3 27B,且推理速度更快。其更低延迟可能归因于定制的分词器、更小的KV缓存和更少的层数。除此之外,它是一个相对标准的架构(图16)。
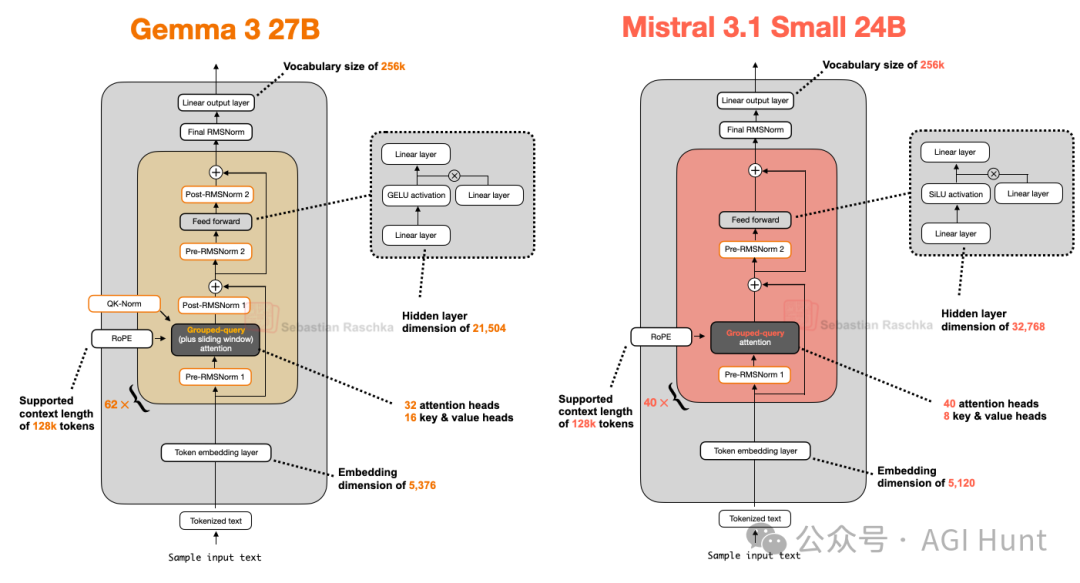
图 16:Gemma 3 27B 与 Mistral 3.1 Small 24B 的架构比较。
早期的Mistral模型曾使用滑动窗口注意力,但在Mistral Small 3.1中似乎放弃了这一设计,转而使用常规的GQA。这可能是因为虽然滑动窗口减少了内存使用,但不一定减少推理延迟,而使用常规GQA可以配合更优化的代码(如FlashAttention)来提升速度。
LLaMA 4
LLaMA 4也采用了混合专家(MoE)方法,其架构与DeepSeek V3非常相似,如图17所示。
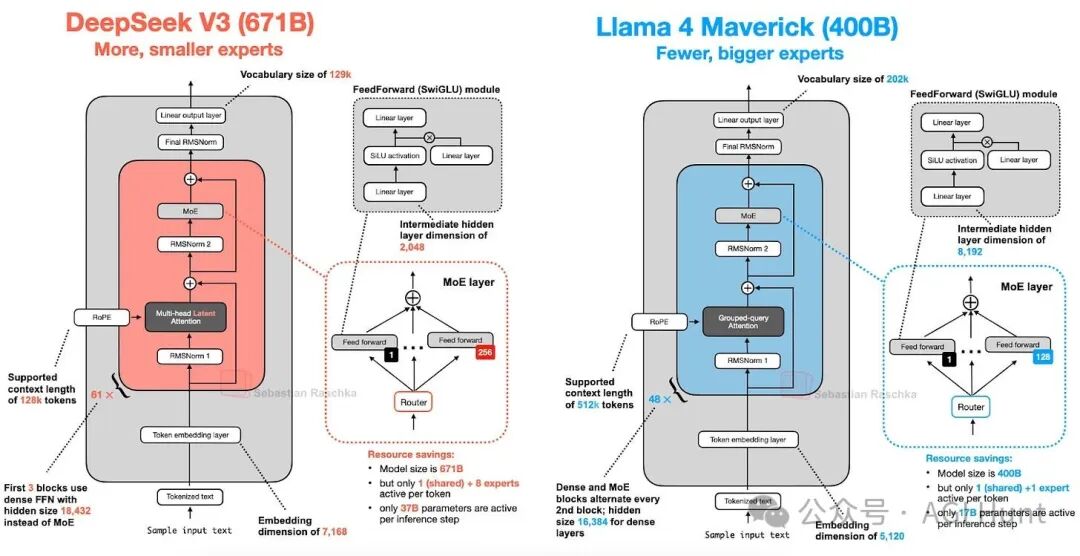
图 17:DeepSeek V3(671B参数)与 LLaMA 4 Maverick(400B参数)的架构比较。
主要差异在于:
- 注意力机制:LLaMA 4使用GQA,而DeepSeek V3使用MLA。
- MoE设计:DeepSeek V3总参数量更大(671B vs 400B),激活参数也更多(37B vs 17B)。LLaMA 4 Maverick使用更经典、专家更少但更大的MoE设置(2个活跃专家,隐藏大小8192),而DeepSeek V3使用更多更小的专家(9个活跃专家,隐藏大小2048)。此外,DeepSeek几乎每块都用MoE,而LLaMA 4在MoE与密集块间交替。
主要结论是,MoE架构在2025年获得了极大的普及。
Qwen3
Qwen3系列模型在其规模类别中表现优异。该系列包括7个密集模型(0.6B至32B)和2个MoE模型(30B-A3B和235B-A22B)。
Qwen3 0.6B是当前最小的当代开源权重模型之一,因其尺寸小、吞吐量高、内存占用低而适合本地运行与教育目的。图18将其与LLaMA 3 1B进行了比较。
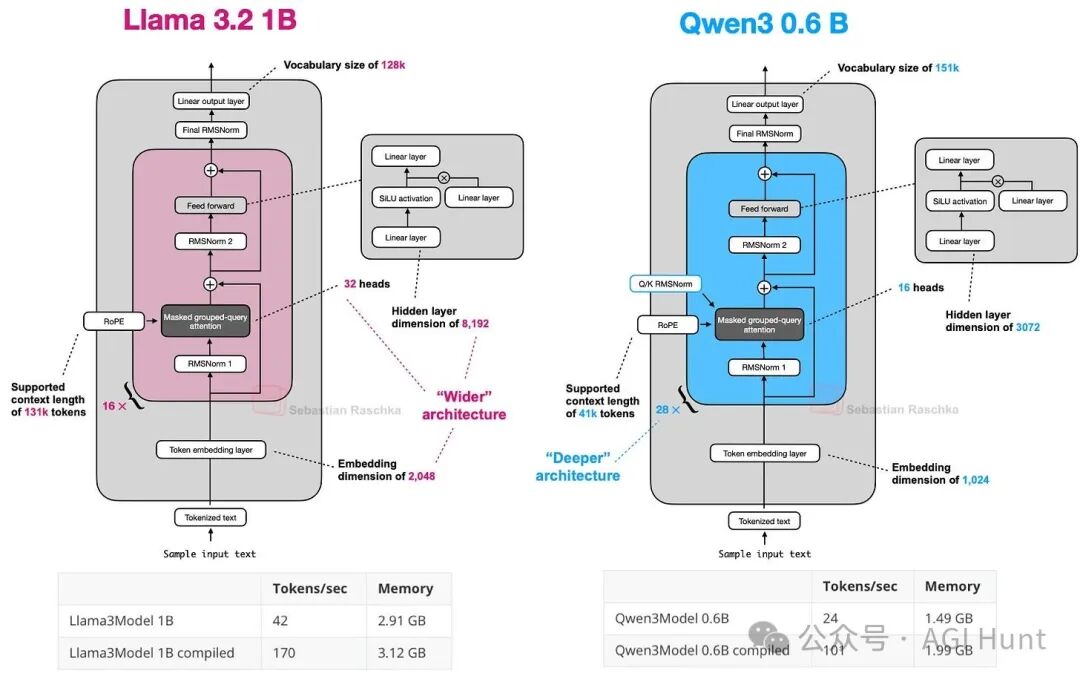
图 18:Qwen3 0.6B 与 LLaMA 3 1B 的架构比较。
同时提供密集和MoE变体为用户提供了灵活性:密集模型通常更容易微调、部署和优化;而MoE模型针对大规模高效推理服务进行了优化,在固定推理预算下实现更高的模型容量。
图19比较了Qwen3 235B-A22B与DeepSeek V3,两者架构高度相似。但值得注意的是,Qwen3模型不再使用共享专家(早期的Qwen2.5-MoE曾使用)。据开发者解释,当时未发现共享专家带来足够显著的改进,且担心其导致的推理优化问题。
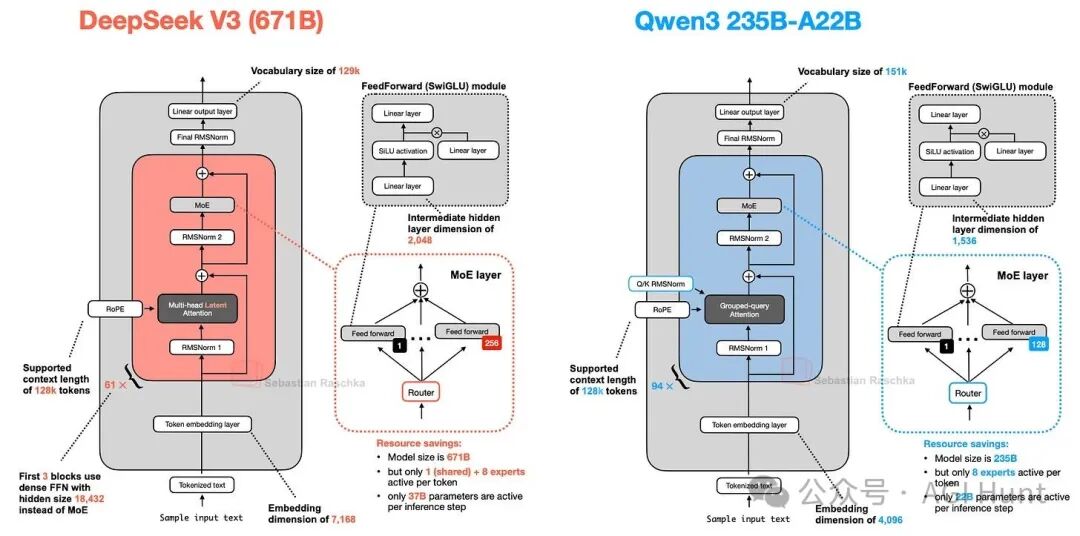
图 19:DeepSeek V3 与 Qwen3 235B-A22B 的架构比较。
SmolLM3
SmolLM3是一个有趣的模型,它在约30亿参数规模下提供了优秀的建模性能。其架构相当标准(图21),但最有趣的方面是它使用了NoPE。
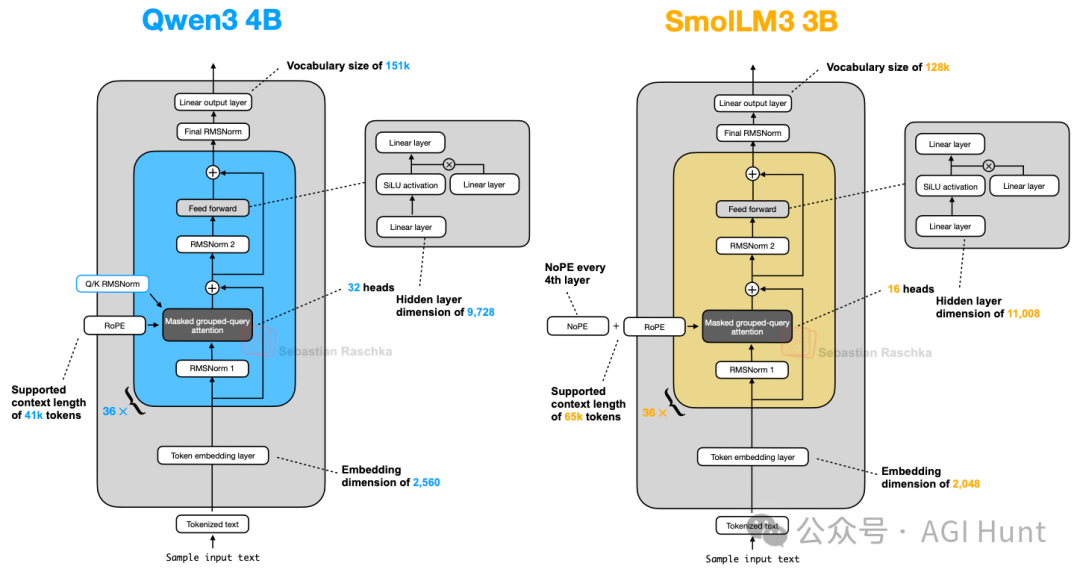
图 21:Qwen3 4B 与 SmolLM3 3B 的架构比较。
NoPE意味着完全不添加显式的位置信息(如绝对位置嵌入或RoPE)。模型仅依靠因果注意力掩码来隐含顺序信息(位置t的token只能看到位置≤t的token)。研究发现,NoPE具有更好的长度泛化能力(图23),即模型在更长序列上的性能下降更少。
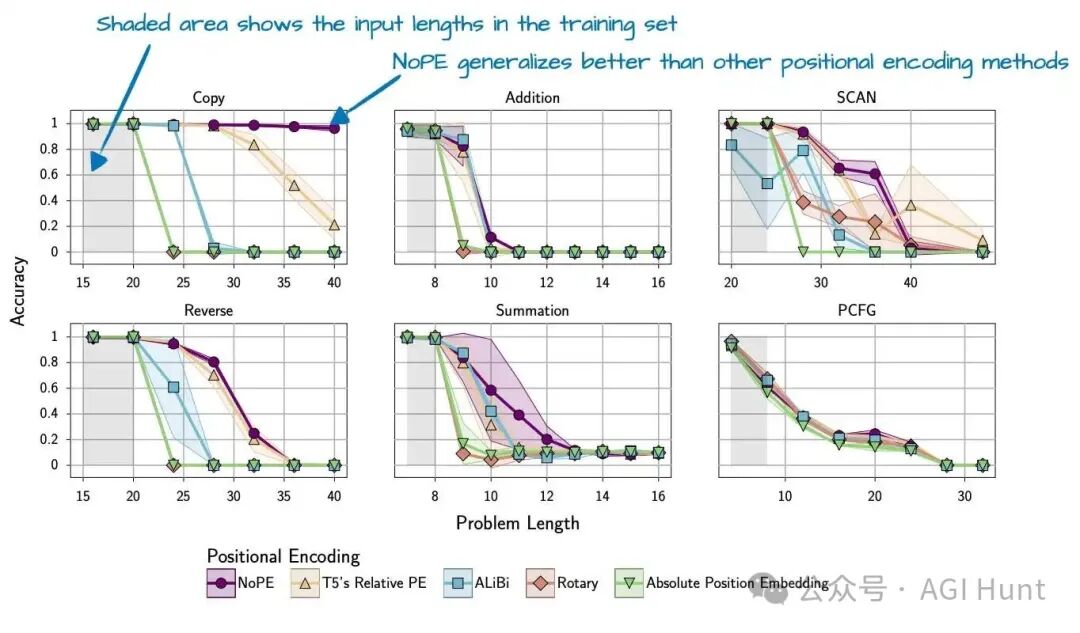
图 23:NoPE 展现出更好的长度泛化能力(来自 NoPE 论文)。
需要注意的是,这些实验是在较小模型上进行的。SmolLM3团队可能仅在部分层中“应用”了NoPE(即省略RoPE)。
Kimi K2
Kimi K2是一个性能接近顶级专有模型的开源权重模型。一个值得注意的方面是它使用了相对较新的Muon优化器的变体,而非AdamW,据信这是首次在此规模的生产模型中使用Muon。
该模型本身拥有1万亿参数,是当前一代最大的开源大型语言模型之一。有趣的是,Kimi K2基本上采用了与DeepSeek V3相同的架构,只是规模更大,且在MoE模块中使用了更多专家,在MLA模块中使用了更少的头(图25.1)。
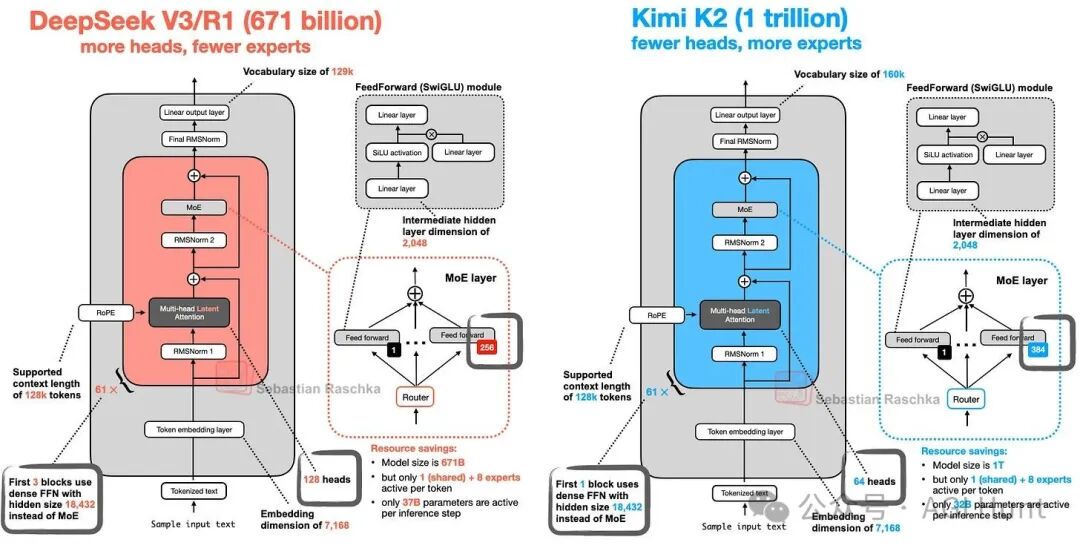
图 25.1:DeepSeek V3 与 Kimi K2 的架构比较。
Kimi K2团队后来还发布了“Thinking”模型变体,将上下文长度扩展到256k,并在某些基准上超过了领先的专有模型。

图 25.2:DeepSeek R1 与 Kimi K2 Thinking 架构及基准对比。
线性注意力的复兴
2025年下半年,线性注意力变体重新兴起,旨在提升LLM效率。传统的缩放点积注意力具有O(n²)的复杂度。线性注意力变体(如DeltaNet)通过近似计算将复杂度降至O(n),从而对长序列更高效,但历史上因可能降低模型精度而未在顶尖模型中广泛应用。
今年,多个模型开始尝试集成线性注意力:
- MiniMax-M1:使用了Lightning Attention。
- Qwen3-Next:采用Gated DeltaNet与门控注意力的混合(3:1比例)。
- DeepSeek V3.2:引入了稀疏注意力(一种线性注意力变体)。
- Kimi Linear:同样采用混合策略,使用改进的Kimi Delta Attention(KDA)机制与MLA结合。
有趣的是,MiniMax团队在后续的M2模型中又回归了常规的完全注意力,理由是线性注意力在推理和多轮任务中精度可能不足。但随后Kimi Linear的发布再次证明了线性注意力在保持性能的同时提升效率的潜力。
这些模型(如Qwen3-Next与Kimi Linear)的结构相似,都依赖于混合注意力策略(图41,42)。
图 41:线性注意力混合架构概述。
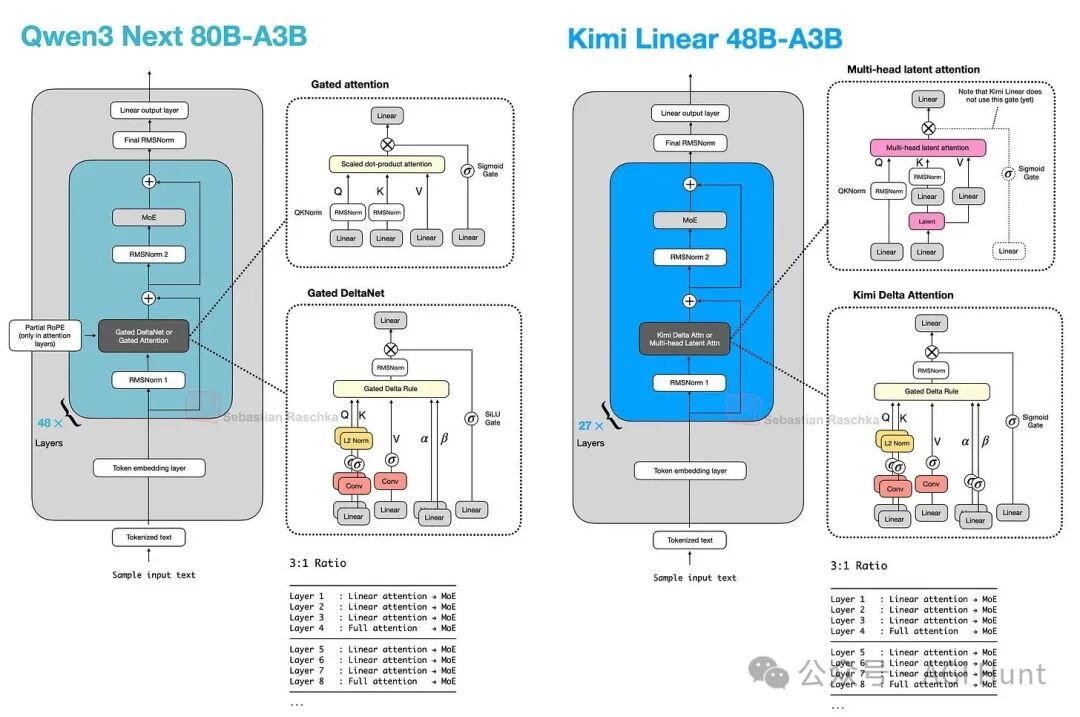
图 42:Qwen3-Next 与 Kimi Linear 架构对比。
Kimi Linear通过其KDA机制和通道式门控改进了Qwen3-Next的线性注意力,据称在长上下文推理上表现更好,并在基准测试中展现了与MLA相当甚至更优的性能,同时保持了高效性(图43)。

图 43:Kimi Linear 在速度与性能上的对比(来自其论文)。
Olmo 3
Allen AI发布的Olmo 3系列(7B, 32B)延续了其完全开源(代码、数据、训练细节透明)的传统。从架构上看,Olmo 3与Qwen3系列相对相似(图44,45)。
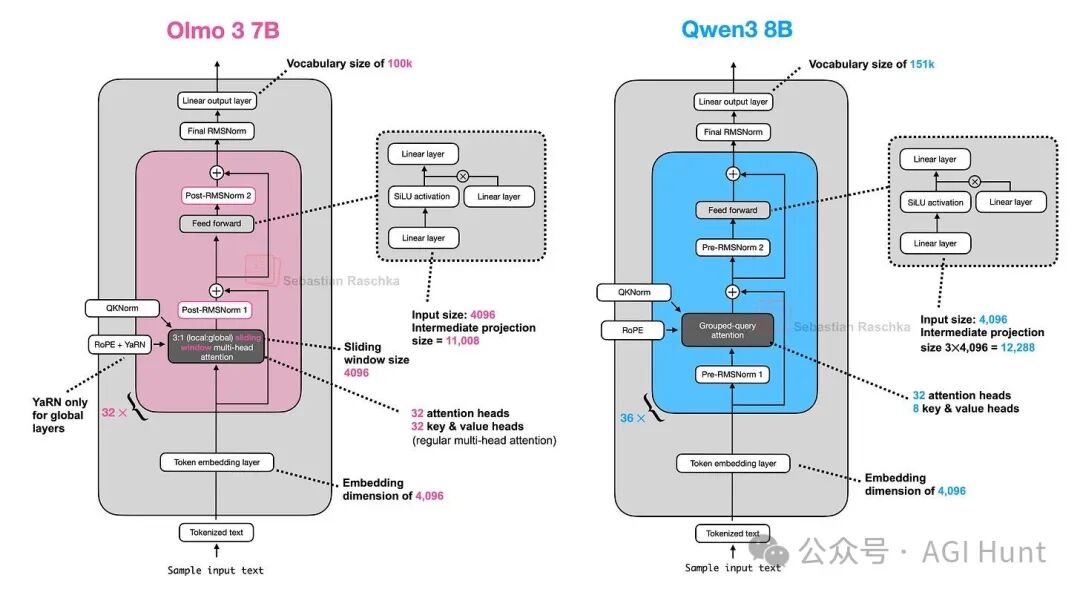
图 44:Olmo 3 7B 与 Qwen3 8B 架构对比。
与Olmo 2类似,Olmo 3仍使用后归一化,因为他们发现这能稳定训练。
- 7B模型使用MHA,并加入了滑动窗口注意力以提升效率、减少KV缓存。
- 32B模型则使用分组查询注意力(GQA)。
- Olmo 3使用YaRN技术将上下文长度扩展到64k。
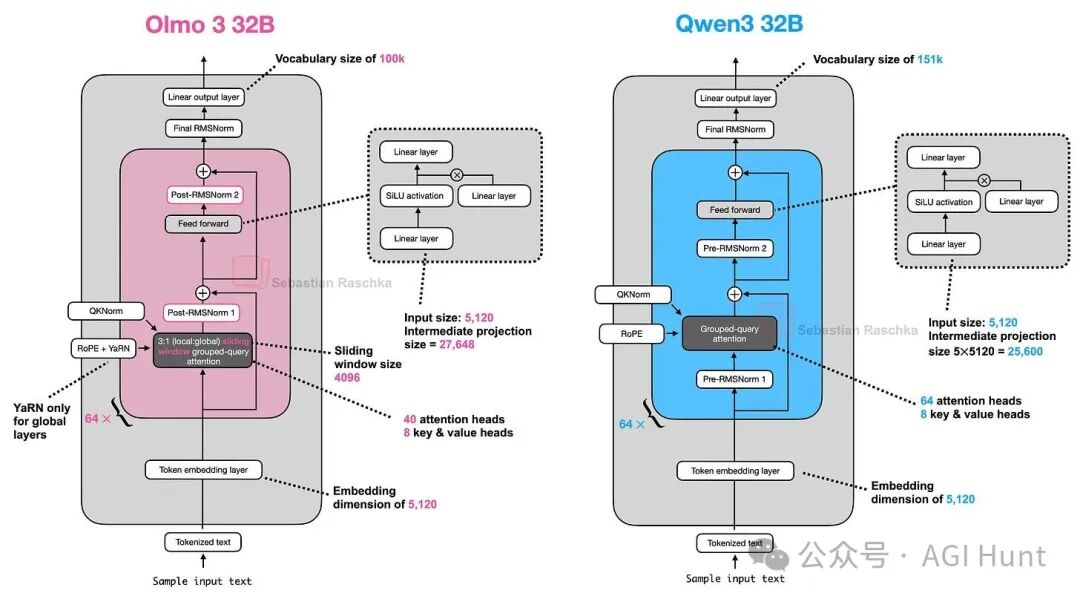
图 45:Olmo 3 32B 与 Qwen3 32B 架构对比。
DeepSeek V3.2
DeepSeek V3.2是一个重要版本,其在某些基准测试上与顶级专有模型不相上下。其架构在DeepSeek V3的基础上,引入了稀疏注意力机制以进一步提升效率(图48)。关于DeepSeek V3.2的详细解析可参见其独立的技术文章。
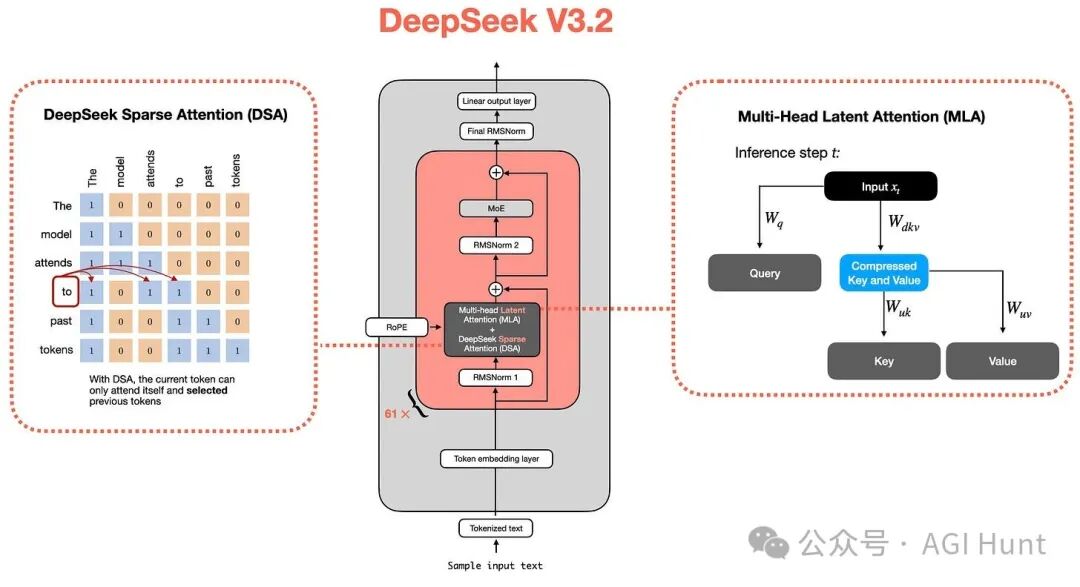
图 48:集成多头潜在注意力与稀疏注意力的DeepSeek模型架构。
Mistral 3
Mistral 3系列包括较小的密集模型(Ministral 3)和旗舰模型Mistral 3 Large(一个675B参数的MoE模型,含视觉编码器)。这是Mistral自2023年Mixtral以来的首个MoE模型。
分析其Hugging Face模型权重可以发现,Mistral 3 Large 与 DeepSeek V3/V3.1 的架构几乎完全相同(图49)。主要区别在于调整了专家大小与数量的比例,并为多模态支持添加了视觉编码器。这体现了业界对经过验证的优秀基础架构设计的认可与复用。
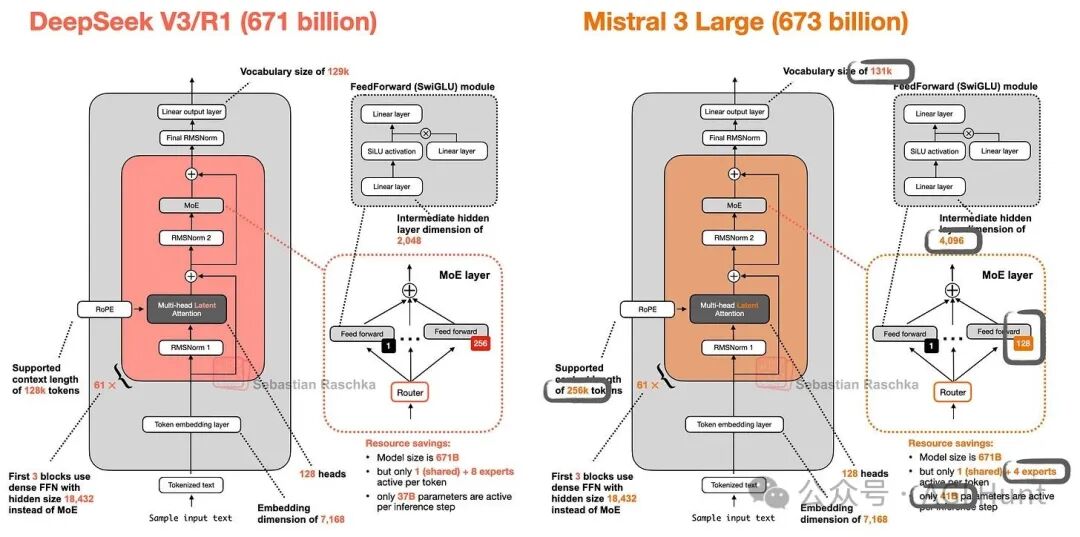
图 49:DeepSeek V3 与 Mistral 3 Large 架构对比。
Mistral 3 Large 的优势在于针对部署(如与NVIDIA合作优化)进行了深度优化,提供了较低延迟和成本效益,并支持多模态。而DeepSeek V3.2-Thinking 则在纯文本推理的答案质量上可能更具优势。
总结:2025年的大型语言模型架构演进呈现“渐进而多样”的特点。Transformer基础框架依然稳固,核心创新围绕提升效率与性能展开:
- 注意力机制优化:MLA、GQA、滑动窗口注意力、线性注意力复兴(DeltaNet等)共存,目标均为减少KV缓存与计算开销。
- 参数高效扩展:MoE架构成为千亿参数级别模型的主流选择,通过稀疏激活平衡容量与推理成本。
- 训练稳定性改进:归一化层放置(Pre-Norm, Post-Norm)、QK-Norm等技术被深入探索以稳定大规模训练。
- 设计复用与优化:优秀的基础架构(如DeepSeek V3)被多个团队采纳并在此基础上进行规模扩展或针对性优化。
秘密酱料越来越多地隐藏在训练流程、数据配比和推理优化策略中。开源社区的持续创新与透明分享,正不断推动着整个领域快速前进。
(本文基于 Sebastian Raschka 的《The Big LLM Architecture Comparison》一文编译整理,专注于架构技术解析。)
 发表于 2025-12-15 07:41:44
|
查看: 236|
回复: 0
发表于 2025-12-15 07:41:44
|
查看: 236|
回复: 0
