Dmitry Vyukov 实现的多生产者多消费者(MPMC)队列是一种经典的高效并发数据结构,专为具有多个生产者和消费者的场景设计。该队列为有界队列,即其容量固定。当队列已满时,生产者线程会被阻塞或返回失败;当队列为空时,消费者线程同样无法取出数据。本文将深入解析这一队列的实现细节、工作原理及其性能优势。
概述
Vyukov 的 MPMC 队列基于环形缓冲区(circular buffer)构建。它是一个无锁并发数据结构,主要依赖原子操作来确保在多线程环境下的安全访问,无需使用传统的互斥锁。这种设计使得它能够支持多个生产者和多个消费者同时高效工作,特别适合高并发场景。
数据结构
队列的核心是一个数组,该数组由一系列“单元格”(cell)组成。每个单元格包含两部分:需要存储的数据和一个用于协调访问的序列号。所有队列操作都围绕这些序列号展开,生产者和消费者通过检查序列号的值来确定单元格的状态,并利用原子操作来避免并发冲突。
具体结构定义如下:
// 为避免缓存伪共享(False Sharing)问题,将结构对齐到 64 字节(缓存行大小)
template<typename T>
class alignas(64) mpmc_bounded_queue {
public:
mpmc_bounded_queue(size_t buffer_size)
:buffer_(new cell_t[buffer_size])
,buffer_mask_(buffer_size - 1)
{
// 要求底层数组 buffer 的长度是 2 的幂
// 这样可以通过位运算 pos & (buffer_size - 1) 快速取模,替代昂贵的除法操作
assert((buffer_size >= 2) && ((buffer_size & (buffer_size - 1)) == 0));
// 初始化:将每个 cell 的 sequence 设置为它的索引值,表示该位置为空
for(size_t i = 0; i != buffer_size; i += 1) {
buffer_[i].sequence_.store(i, std::memory_order_relaxed);
}
enqueue_pos_.store(0, std::memory_order_relaxed);
dequeue_pos_.store(0, std::memory_order_relaxed);
}
private:
struct alignas(64) cell_t {
std::atomic<size_t> sequence_; // 序列号,用于标记数据顺序状态
T data_; // 实际存储的数据
};
cell_t* const buffer_; // 底层存储数组
size_t const buffer_mask_; // 用于快速取模的掩码
alignas(64) std::atomic<size_t> enqueue_pos_; // 生产者游标
alignas(64) std::atomic<size_t> dequeue_pos_; // 消费者游标
};
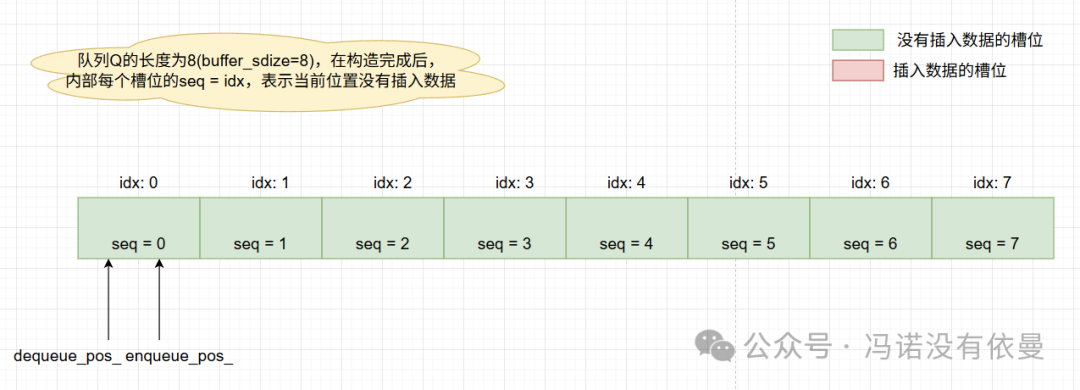
图1:队列初始化后的内部结构示意图
队列操作
入队 (Enqueue)
入队操作需处理生产者之间以及生产者与消费者之间的竞争。其核心逻辑是生产者尝试获取一个空闲的单元格并写入数据。
生产者间竞争:假设两个生产者线程几乎同时尝试入队。它们会先加载相同的enqueue_pos_值,从而指向同一个单元格。随后,它们会通过compare_exchange_weak原子操作竞争递增enqueue_pos_的权利。成功的线程获得该单元格的写入权,失败的线程则自旋重试,尝试下一个位置。
生产者与消费者竞争:
- 当队列为空,生产者刚获得写入权但尚未写入数据时,消费者会因序列号条件不满足而消费失败。生产者完成写入并更新序列号的操作(
store with release)与消费者检查序列号的操作(load with acquire)构成同步,确保了“先写入后消费”的顺序。
- 当队列为满,生产者尝试写入已满位置时会失败。待消费者消费该位置的数据并更新序列号后,生产者才能感知并成功写入,这保证了“先消费后写入”。
下图展示了生产者插入两条数据后,队列底层的逻辑视图。
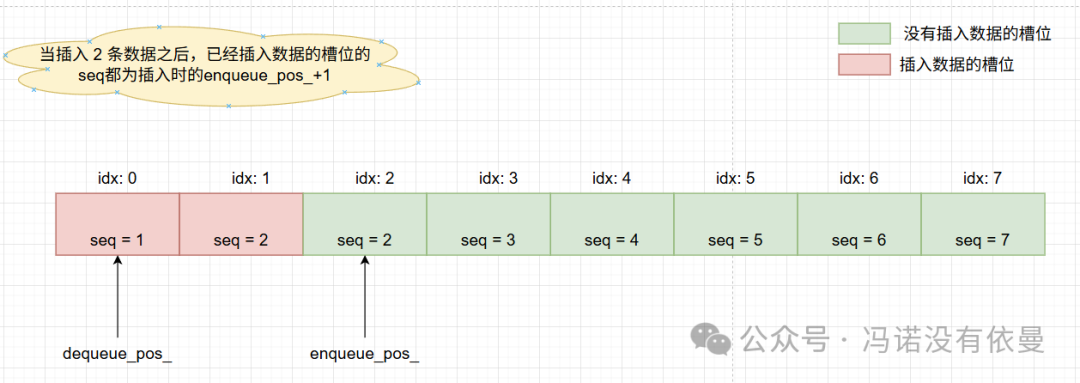
图2:入队操作后的状态
入队操作的代码实现如下:
bool enqueue(T const& data)
{
cell_t* cell;
size_t pos = enqueue_pos_.load(std::memory_order_relaxed);
for(;;)
{
cell = &buffer_[pos & buffer_mask_];
size_t seq = cell->sequence_.load(std::memory_order_acquire);
intptr_t diff = (intptr_t)seq - (intptr_t)pos;
if(diff == 0)
{
if(enqueue_pos_.compare_exchange_weak(pos, pos + 1, std::memory_order_relaxed))
break;
} else if (diff < 0) {
// 队列已满
return false;
} else {
pos = enqueue_pos_.load(std::memory_order_relaxed);
}
}
cell->data_ = data;
cell->sequence_.store(pos + 1, std::memory_order_release);
return true;
}
出队 (Dequeue)
出队操作的逻辑与入队对称。消费者尝试获取一个存有有效数据的单元格并读取数据。它同样需要处理多个消费者之间的竞争,以及消费者与生产者之间的协调。
- 消费者通过检查单元格序列号是否为
pos + 1 来判断数据是否就绪。
- 成功消费后,消费者将序列号更新为
pos + buffer_mask_ + 1,这实际上是将该单元格标记为“空”,并绕回到一个未来可被生产者再次使用的序列号范围,完美避免了ABA问题,这是并发编程中无锁数据结构设计的一个关键点。
下图展示了生产者插入两条数据且消费者消费一条数据后,队列的状态。
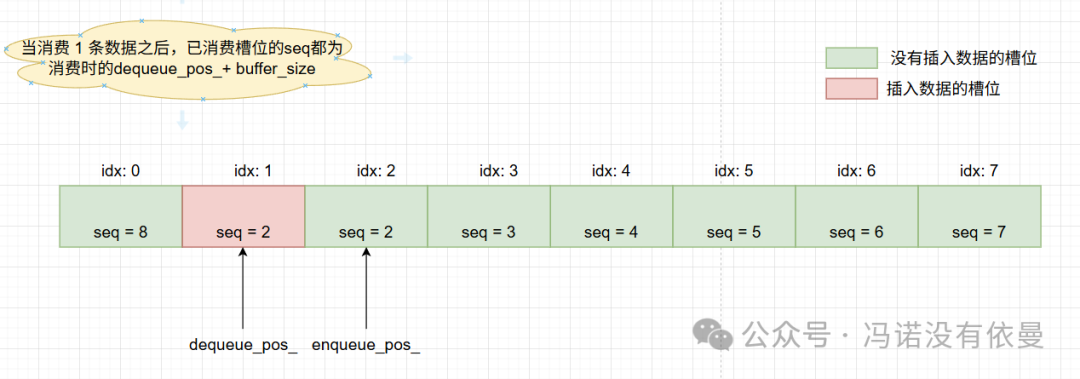
图3:出队操作后的状态
出队操作的代码实现如下:
bool dequeue(T& data)
{
cell_t* cell;
size_t pos = dequeue_pos_.load(std::memory_order_relaxed);
for(;;)
{
cell = &buffer_[pos & buffer_mask_];
size_t seq = cell->sequence_.load(std::memory_order_acquire);
intptr_t diff = (intptr_t)seq - (intptr_t)(pos + 1);
if(diff == 0)
{
if(dequeue_pos_.compare_exchange_weak(pos, pos + 1, std::memory_order_relaxed))
break;
} else if (diff < 0){
// 队列为空
return false;
} else {
pos = dequeue_pos_.load(std::memory_order_relaxed);
}
}
data = cell->data_;
cell->sequence_.store(pos + buffer_mask_ + 1, std::memory_order_release);
return true;
}
优势与特点
- 高并发性:完全基于原子操作实现,摒弃了重型锁,使得生产者和消费者线程的争用大幅减少,在高并发环境下性能显著优于基于锁的队列。
- 无ABA问题:通过单元格中的序列号(
sequence_)机制,巧妙地避免了无锁编程中常见的ABA问题。
- 设计优雅简洁:整个实现逻辑清晰,核心思想易于理解,是学习无锁并发数据结构的优秀范例。
- 缓存友好:通过内存对齐(
alignas(64))隔离了生产者游标、消费者游标以及各个单元格,有效防止了缓存伪共享,提升了多核CPU下的性能。
参考
[1] Dmitry Vyukov. Bounded MPMC queue. https://www.1024cores.net/home/lock-free-algorithms/queues/bounded-mpmc-queue
 发表于 2025-12-15 11:03:15
|
查看: 327|
回复: 0
发表于 2025-12-15 11:03:15
|
查看: 327|
回复: 0
