在先前关于Cilium丢包问题的讨论中,初步结论是由于VXLAN封装与中间网络设备不支持分片所致,并通过调整MTU值临时解决。然而,这次排查并未穷尽所有细节。在分析过程中,一个关键线索浮出水面:所有丢包的数据包在抓包记录中都呈现乱序状态。网络传输中数据包乱序本是常态,TCP协议具备重组能力以应对。但对于作为云原生网络解决方案的Cilium而言,特定场景下的乱序却可能成为致命伤。本文将深入解析这一现象背后的原因。
环境介绍
- 采用混合云架构部署的Kubernetes集群,节点分布于阿里云、华为云、腾讯云及自建数据中心(IDC)。
- 集群网络插件为Cilium,采用Overlay网络模式,跨节点通信使用VXLAN隧道封装。
问题现象
- 位于IDC机房节点上的Pod,在请求公有云中特定CVM节点上的Pod时,响应极其缓慢并频繁超时。
- 请求数据量较小的内容(如几百KB的文件)时,一切正常。
- 执行
ping <Pod_IP> -s 1400 命令发送大包时,失败率高达90%。
分析工具
- Wireshark:网络抓包与分析。
- cilium-dbg:Cilium官方网络诊断工具。
- eBPF程序:自定义内核态数据包追踪。
排查分析过程
1. Wireshark工具注意事项
首先需要明确使用Wireshark分析分片报文时的两个关键点:
① Wireshark会自动补全分片数据:这有时会产生误导,因为它展示的是重组后的逻辑视图,而非线路上原始的分片顺序。
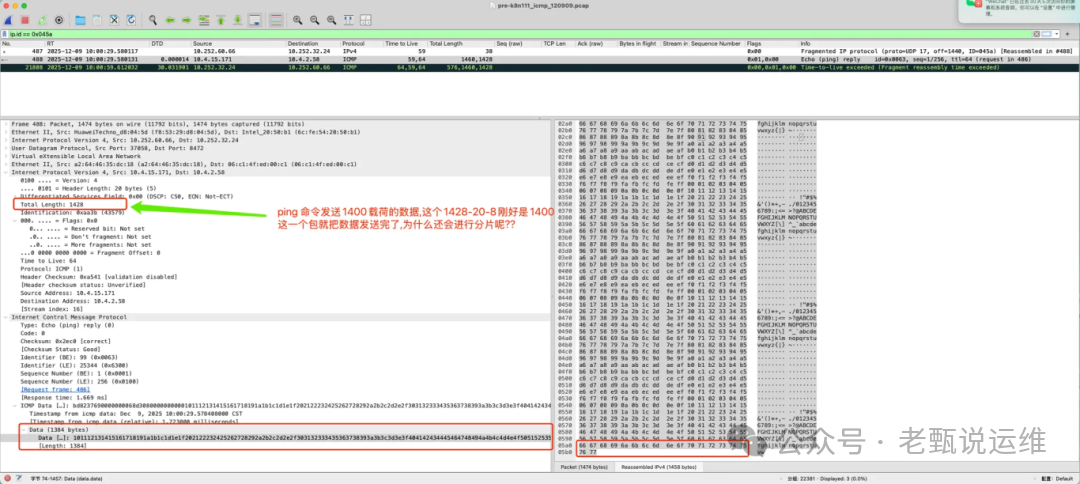
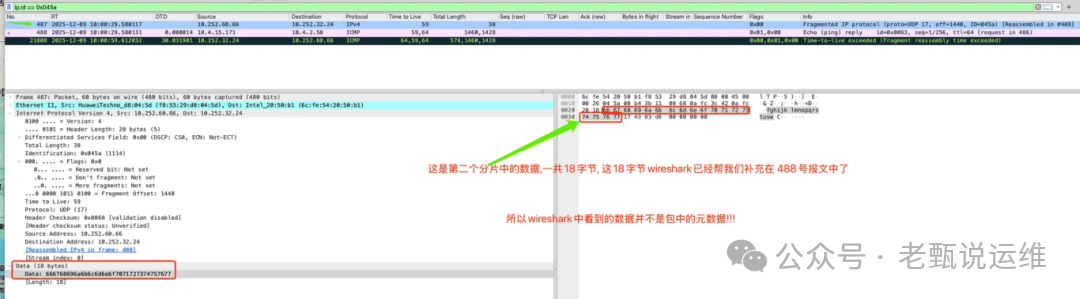
② 识别重组超时报文:Time-to-live exceeded (fragment reassembly time exceeded) 报文表示接收方因分片未能及时到齐而宣告重组失败,并通知发送方。
通过对IDC服务器物理网卡(bond1)抓包,我们发现ICMP应答报文已抵达宿主机,但ping命令却提示无响应。这表明数据包被宿主机网络栈或Cilium丢弃,未递交给上层应用。
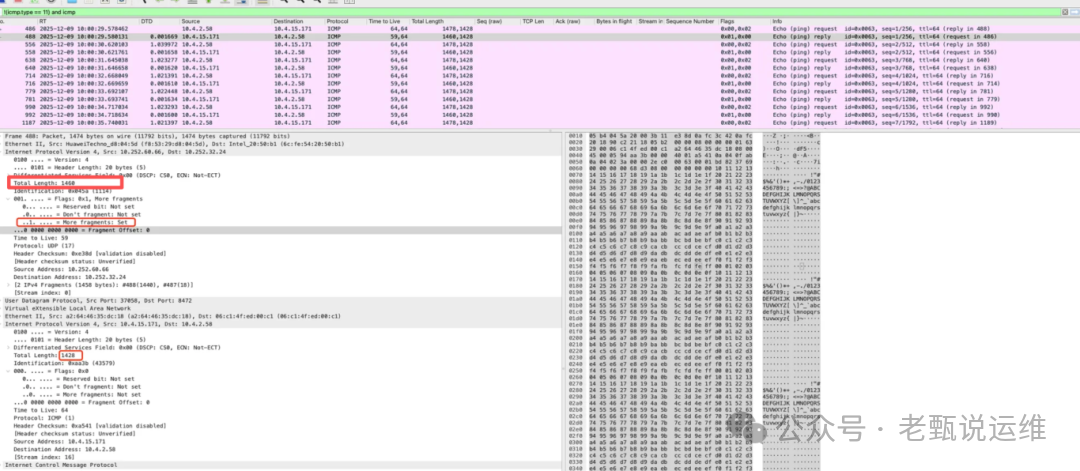
报文长度计算:
ping -s 1400 指ICMP负载为1400字节。因此,内层IP包的Total Length为:20字节(IP头) + 8字节(ICMP头) + 1400字节 = 1428字节。
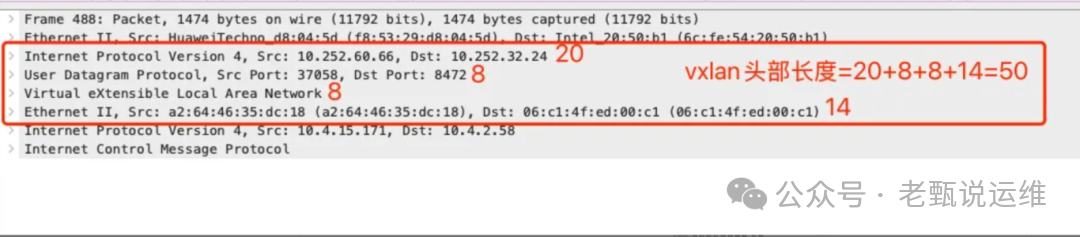
加上VXLAN头部(通常为50字节,格式如下图),外层IP包总长度约为1478字节,极易超过标准1500字节的MTU,从而在路径上触发分片。
2. 对比正常与异常分片报文
通过对比抓包文件,我们发现了异常与正常报文的关键差异:

正常情况:
- 1460字节的大分片先到达。
- 60字节的小分片(尾片)后到达。
- 这个顺序符合IP分片预期,最后一个分片偏移量最大。
异常情况:
- Wireshark将VXLAN头部信息显示在最后一个分片(60字节)中。这不符合网络原理,因为VXLAN头部作为外层封装,理应存在于第一个分片内。
- 这实际上是Wireshark的“误导性”显示特性,它会将VXLAN头固定在它认为的“最后一个分片”位置展示。但在真实链路上,VXLAN头只存在于首个分片。
- 核心发现:凡是分片到达顺序错乱(小分片先于大分片到达)的报文,对应的
ping请求均发生丢包。
问题:为什么分片顺序错乱在VXLAN模式下必然导致丢包?
3. 使用eBPF深入内核协议栈观测
为探究内核如何处理这些乱序分片,我们编写了一个eBPF程序(bpftrace脚本),用于追踪IP分片重组函数 ip_defrag 的调用情况。
#!/usr/bin/env bpftrace
/*
* trace_defrag.bt
* 追踪指定 IP 的 IP 分片重组情况 (ip_defrag)
*/
BEGIN{
if ($# < 1) {
printf("用法: ./trace_defrag.bt <POD_IP>\n");
exit();
}
printf("正在追踪 IP: %s 的分片重组情况... 按 Ctrl-C 停止\n", str($1));
printf("%-10s %-16s %-16s %-8s %-8s %-4s %-6s\n",
"TIME", "SRC", "DST", "ID", "OFFSET", "MF", "LEN");
}
kprobe:ip_defrag
{
$skb = (struct sk_buff *)arg1;
$ip = (struct iphdr *)($skb->head + $skb->network_header);
$saddr = ntop($ip->saddr);
$daddr = ntop($ip->daddr);
$id_be = $ip->id;
$id = ($id_be >> 8) | (($id_be & 0xff) << 8);
$off_be = $ip->frag_off;
$off_raw = ($off_be >> 8) | (($off_be & 0xff) << 8);
$mf = ($off_raw & 0x2000) >> 13; /* More Fragments 标志 */
$offset = ($off_raw & 0x1fff) * 8; /* 实际偏移量 (字节) */
$len_be = $ip->tot_len;
$len = ($len_be >> 8) | (($len_be & 0xff) << 8);
printf("%-10s %-16s %-16s %-8d %-8d %-4d %-6d\n",
strftime("%H:%M:%S", nsecs),
$saddr, $daddr,
$id, $offset, $mf, $len);
}
执行与输出:
# ./trace_defrag.bt 10.4.15.171
Attaching 2 probes...
正在追踪 IP: 10.4.15.171 的分片重组情况... 按 Ctrl-C 停止
TIME SRC DST ID OFFSET MF LEN
10:50:37 10.252.60.66 10.252.32.24 59399 0 1 1460
10:50:37 10.252.60.66 10.252.32.24 59399 1440 0 60
10:50:37 10.252.60.66 10.252.32.24 59400 0 1 1460
10:50:37 10.252.60.66 10.252.32.24 59400 1440 0 60
...
输出参数解释:
- ID:IP标识字段,相同ID代表属于同一个原始数据包的分片。
- OFFSET:分片偏移量,0代表是第一个分片。
- MF (More Fragments):1表示后面还有分片,0表示这是最后一个分片。
- LEN:当前分片的总长度(IP头+负载)。
关键发现:从eBPF程序的输出中,我们观察到大量 ID 相同、OFFSET 为1440(即最后一个分片)、MF为0、LEN为60的报文被记录。然而,结合抓包现象(小包先到)和最终丢包的结果分析,内核协议栈实际上将这些先到达的、没有VXLAN头部的尾部分片丢弃了,导致后续即使第一个分片到达,也无法完成重组。
4. 验证猜想:Cilium的严格顺序依赖
通过向大模型咨询和查阅资料,我们得到一个核心观点:Cilium在VXLAN模式下,对分片的到达顺序有强依赖。这是因为Cilium的eBPF数据面程序需要看到完整的VXLAN头部(它只存在于第一个分片)才能正确识别和处理报文。
为了验证,我们使用Cilium的调试命令查看丢包原因:
# 在发生丢包的宿主机节点上,进入对应的Cilium Pod执行
cilium-dbg monitor --type drop -vv
(输出内容较长,展示关键部分)
...
Ethernet {Contents=[..62..] SrcMAC=f8:53:29:d8:04:5d DstMAC=6c:fe:54:20:50:b1 EthernetType=IPv4 Length=0}
IPv4 {Contents=[..20..] Payload=[..40..] Version=4 IHL=5 TOS=0 Length=60 Id=54580 Flags= FragOffset=180 TTL=59 Protocol=UDP Checksum=14199 SrcIP=10.252.60.66 DstIP=10.252.32.24 Options=[] Padding=[]}
CPU 06: MARK 0x6f2d398c FROM 3981 DROP: 74 bytes, reason First logical datagram fragment not found, identity world->unknown
...
在cilium-dbg monitor的输出中,我们清晰地看到了丢包记录及原因:First logical datagram fragment not found(未找到第一个逻辑数据报分片)。这直接证实了我们的猜想:当偏移量不为0的后续分片(如尾片)先于第一个分片到达Cilium的虚拟网络设备时,由于无法找到包含必要元信息(如VXLAN头)的首个分片,Cilium的eBPF程序会将其丢弃。
结论与解决方案
根本原因:
在Cilium VXLAN Overlay网络模式下,数据包的分片到达顺序至关重要。由于VXLAN封装信息仅存在于第一个分片中,Cilium的eBPF数据面程序需要据此进行隧道解封装和路由决策。如果后续分片(特别是尾片)先于第一个分片到达,Cilium因无法识别该报文所属的隧道上下文,会直接将其丢弃,导致IP重组失败,引发通信超时和丢包。这在公网链路质量不佳、易发生乱序的混合云场景中尤为突出。
解决方案:
- 规避分片(推荐):调整集群内节点和Pod的MTU值,确保在计入VXLAN等隧道开销后,报文总长度仍小于网络路径上的最小MTU。这是最根本的解决方法,可以彻底避免分片及其带来的乱序问题。
- 优化网络路径:确保
Kubernetes节点间网络链路质量,减少公网传输中的乱序概率,但此方法通常不可控。
附:Cilium 常用调试命令速查
# 网络完全不通
cilium-dbg monitor --type drop
# Service 访问不通
cilium-dbg service list
# 网络策略不生效/连接被误杀
cilium-dbg policy trace <src> <dst> <port> <protocol>
# 查询Pod端点信息
cilium-dbg endpoint list
# 排查连接跟踪状态
cilium-dbg bpf ct list global
 发表于 2025-12-15 11:06:49
|
查看: 223|
回复: 0
发表于 2025-12-15 11:06:49
|
查看: 223|
回复: 0
