在量化投资领域,“增加因子复杂度”并非为了炫技或将数学公式复杂化,其核心目的在于挖掘数据中的非线性规律,并构建因“难以发掘”而产生的策略护城河。
通俗地讲,市场中的“低垂果实”(简单的线性规律)已被摘尽,若想持续获得超额收益,必须借助更复杂的工具与方法去探寻更深层次的市场逻辑。
我们可以从以下三个维度来深入理解因子复杂度的内涵:
1. 什么是“因子的复杂度”?
因子的复杂度通常体现在以下几个方面:
A. 算子与逻辑的非线性化 (Mathematical Complexity)
- 简单因子:传统动量因子可能仅计算过去N日的收益率。
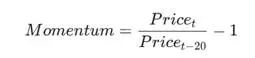
这是一种直观的线性逻辑。
- 复杂因子:通常由遗传规划或机器学习方法自动挖掘生成,其形态可能非常复杂。
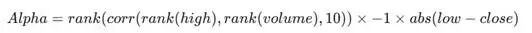
此类因子难以用传统金融理论直接解释,但可能捕捉到了市场微观结构中的非线性特征。
B. 信息的交叉与交互 (Interaction)
单一维度的信号往往噪声大、失效快,而多维度信息的交叉验证能有效提升信号的纯净度。
- 简单:仅筛选“市盈率低”的股票。
- 复杂:筛选同时满足“市盈率低”、“近期成交量放大”且“分析师一致预期上调”的股票。这种多条件组合将因子从一维标量提升为多维向量,能更有效地过滤噪声。
C. 数据源的深度 (Data Complexity)
- 简单:仅使用开盘价、最高价、最低价、收盘价(OHLC)等基础行情数据。
- 复杂:利用Level-2高频订单簿数据计算买卖盘失衡度,或引入另类数据(如基于自然语言处理的新闻情绪分析)。
2. 为何要增加复杂度?(底层驱动力)
核心驱动力源于量化市场的一个基本规律:Alpha衰减(Alpha Decay)。
A. 简单策略的极度拥挤
诸如“均线金叉”、“低估值”等简单逻辑已广为人知。当海量资金采用同质化策略进行交易时,该类策略的超额收益会迅速被摊薄直至消失,甚至转为负收益。
B. 提升信息比率 (Information Ratio)
简单线性因子通常信噪比较低。通过引入复杂的数学变换(如时序加权、去极值、正交化、衰减加权等),可以压制噪声,增强有效信号。
- 示例:单纯的“成交量”因子噪声较大,而“成交量除以过去20日波动率的衰减加权平均值”则可能构成一个更稳健的信号。
3. 必须警惕的陷阱:过拟合 (The Trap of Overfitting)
对于初学者而言,这是最需要警惕的误区。盲目增加复杂度是一把双刃剑。
如果一个因子的构建复杂到恰好完美拟合了历史数据中的随机波动:
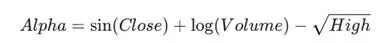
那么它在样本外(未来)的表现极大概率会失效。这种现象称为过拟合(Overfitting)——此时模型捕捉的并非市场规律,而是历史噪音。
专业的量化开发在提升因子复杂度的同时,必然会严格进行以下两项工作:
- 逻辑归因:即使公式复杂,也需尝试阐释其背后可能的经济学或行为金融学逻辑(例如,该复杂公式可能本质上在刻画“恐慌性抛售后的流动性恢复”)。
- 鲁棒性测试:将因子置于不同的市场周期(牛、熊、震荡市)和更长的历史时间段中进行测试,验证其稳定性和普适性。
总结而言,在当今高度内卷的量化市场中,依赖简单的线性价量关系已难以持续创造价值。通过引入更高维的数学变换、多源数据交叉验证,旨在挖掘那些超越人类直觉、深藏于数据底层的非线性规律,是策略进化的必然方向。
对于希望亲身体验“复杂度”的开发者,可以尝试使用Python生态中的遗传规划工具库(如gplearn)。它能够自动将基础价量数据组合成复杂的数学表达式作为候选因子,是探索“算法生成复杂因子”的有效工具。 |  发表于 2025-12-15 21:49:51
|
查看: 240|
回复: 0
发表于 2025-12-15 21:49:51
|
查看: 240|
回复: 0
