在讨论开放表格式(如 Apache Iceberg)的性能时,“索引”这个概念常被提及,无论是在现有设计还是对未来功能的展望中。但在这个领域,什么才能真正算作“索引”呢?
某些格式,例如 Apache Hudi,确实维护了记录级的索引(如主键到文件组的映射),这能高效地将插入/删除操作定向到正确的文件,从而支持主键表。但这并不能像在 OLTP 数据库中那样,依靠二级索引来提升基于任意谓词的读取性能。
传统的二级索引(例如关系数据库中的 B 树)在 Iceberg、Delta Lake 甚至 Hudi 中都不存在。这是为什么?如果我们在 Iceberg 规范中加入二级索引,是否能解决一些性能瓶颈?
答案并非简单的“我们还没来得及做”,而是有深刻的现实原因。本文将深入探讨以下两个核心问题:
- 为什么不能像在关系数据库(RDBMS)中那样,通过添加二级索引来加速分析查询?
- 分析型工作负载如何塑造了表格式(包括其核心结构与辅助文件)的设计,这与 RDBMS 有何本质不同?
一个核心观点是,无论是传统 RDBMS 还是 Iceberg 表,读取性能最终都取决于 I/O 数量的减少,而这又取决于:
- 数据本身的组织方式。
- 在数据组织之上使用的辅助数据结构。
关键在于,工作负载决定了数据组织和辅助结构的选择。我们将首先剖析 RDBMS 中的索引机制,再对比 Iceberg 等开放表格式的工作原理。
传统关系数据库中的数据组织、索引与辅助结构
索引的核心价值在于通过减少查询所需的 I/O 来加速查询。如果查询单行却需扫描全表,在大数据集上将是灾难性的。在 RDBMS 中,索引通常是 B 树,支持两种主要访问模式:查找(Seek)(遍历树以定位特定行)和扫描(Scan)(遍历树或某个范围)。
在传统 RDBMS 中,索引可大致分为两类:
- 聚集索引:索引与数据本身是一体的。表本身若按主键排序,就是一个聚集索引。如同图书馆书架按作者字母顺序排列,数据顺序即索引。
- 非聚集索引:索引是一个独立的(通常更小的)结构,指向表中的实际数据行。二级索引就是典型例子。如同图书馆的电脑检索系统,告诉你书在哪个书架。
此外,还有表统计信息(如基数估计和直方图),它们对于查询优化器选择高效执行计划至关重要。
RDBMS 表本身(聚集索引)
假设一个 User 表以自增 UserId 为主键。该表作为聚集索引,数据按 UserId 排序存储在 B 树中。
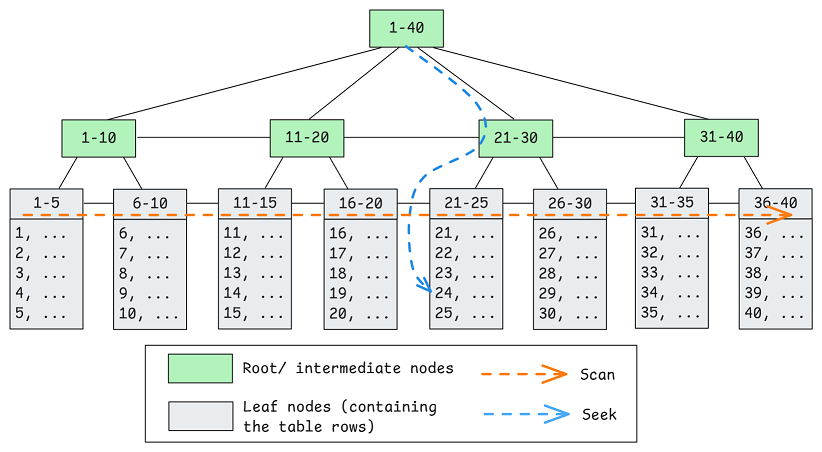
通过主键查询(如 SELECT * FROM User WHERE UserId = 100;),数据库会执行聚集索引查找,快速定位到对应数据页。这种结构的代价是插入、删除可能导致页分裂、合并及碎片化,但其带来的好处在 OLTP 场景下是值得的——绝大多数查询都是针对单行或极少行的快速操作。按主键排序的 B 树确保了查找成本为 O(log n),且能高效支持主键连接。
二级(非聚集)索引
如果需按 Country 或 LastName 查询,则需要二级索引。它们是独立的 B 树,将特定列的值映射到聚集索引中的行(即主键)。
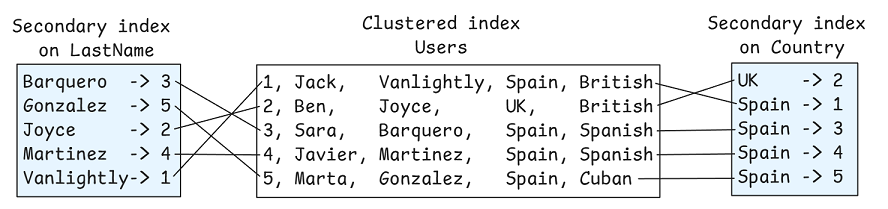
查询 SELECT * FROM Users WHERE LastName = 'Martinez' 会执行:1. 在二级索引 B 树中查找,获得匹配行的主键;2. 用这些主键回表(聚集索引)查找,获取完整行。
选择性在此至关重要。如果二级索引返回的行很少,这种“索引查找+回表”的随机 I/O 是高效的;但如果返回大量行(例如,Country = 'Spain' 匹配了表中80%的行),全表扫描可能更快。查询优化器会基于统计信息做出选择。此外,二级索引还可通过包含列来避免回表,直接满足查询。不过,这些在数据库与中间件中常见的优化,都以额外的存储空间、写入开销和维护成本为代价。
列统计信息
表统计信息(基数、直方图)指导优化器决策。例如,如果 Country 列的统计显示“Spain”值占比极高,优化器就会放弃使用该列上的二级索引,转而选择全表扫描。
RDBMS 设计哲学小结
- 工作负载:优化点查找、短范围查询、少量行连接及频繁写/更新。查询通常只涉及少量行。
- 数据组织:基于行的存储,页中包含完整行,单行访问高效。
- 聚集索引:表是按主键排序的 B 树,按键查找高效。
- 二级索引:独立的 B 树,将其他列映射到主键。适用于高选择性查询和覆盖查询,但增加维护负担。
- 权衡:索引以减少读取 I/O 为目标,但增加了写入和维护开销。在 OLTP 中,此代价可接受。
核心在于,二级索引使得单张表能够支持多样化的查询模式。这一点在开放表格式中难以直接实现。
开放表格式中的数据组织、索引与辅助结构
分析系统(如数据仓库或湖仓一体)的工作负载与 OLTP 截然不同。查询通常需要扫描数百万甚至数十亿行数据进行聚合或连接。因此,基于行的有序 B 树存储效率低下,列式存储成为主流,其优化核心从“减少随机查找”转变为“高效跳过无关数据”。
表结构:元数据 + 数据文件
以 Iceberg 为例,其表结构是一棵由元数据文件、清单列表、清单文件和数据文件(Parquet/ORC)组成的树,数据文件本身是无序、不可变的。
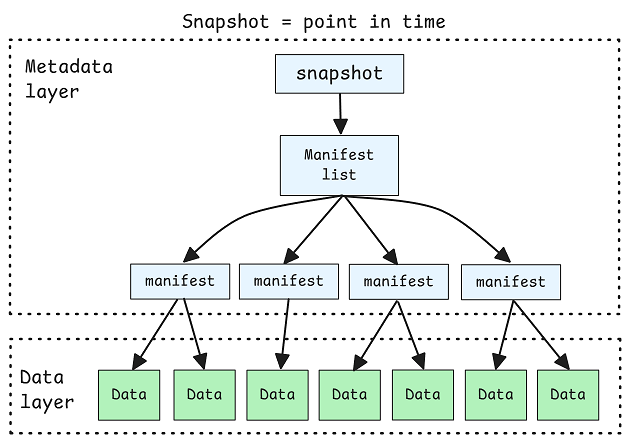
性能提升的关键在于剪枝(Pruning)——根据元数据在规划或执行时跳过不相关的文件或数据块。剪枝的有效性取决于数据布局。
数据的物理布局
- 分区:根据一列或多列(如日期、地区)将数据文件分组到不同目录。当查询条件匹配分区键时,引擎可分区修剪,直接跳过无关分区。分区键选择需谨慎,避免产生大量小文件。
- 排序:在每个分区内,按常用筛选列(如
EventTime, Country)排序。这确保了相似值在物理上邻近存储,显著提升了文件内和文件间的数据局部性,使列统计信息更精确,从而增强行组级修剪。仅靠写入时排序可能造成分区内文件间顺序不一致,压缩(Compaction) 操作能合并小文件并强制执行全局排序顺序,是发挥排序优势的关键。
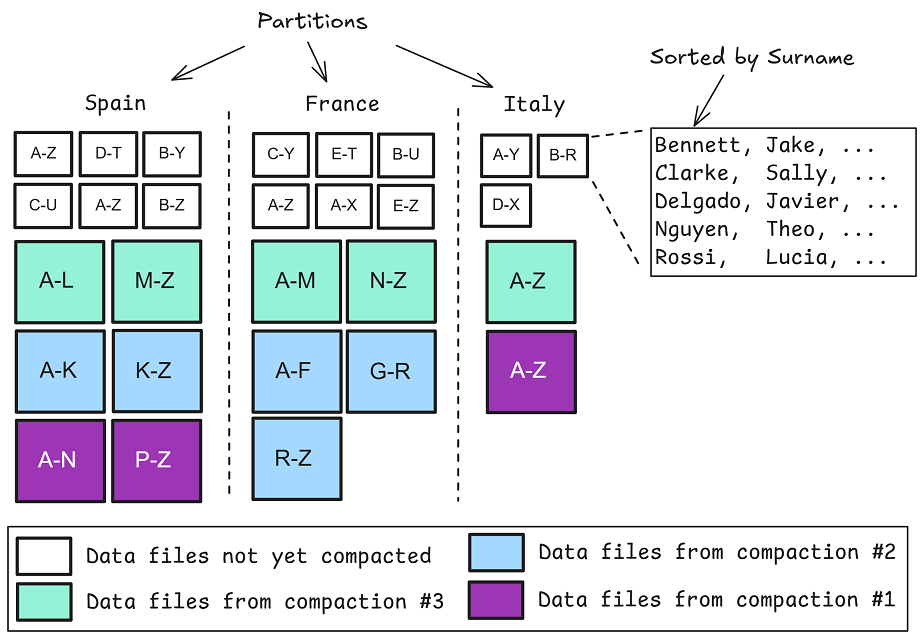
- Z-Ordering / Liquid Clustering:Delta Lake 的 Z-Ordering 和 Databricks 的 Liquid Clustering 提供了多维聚类能力,即使未对任何单列全局排序,也能让具有相似列值组合的行在物理上靠近,利于多维度筛选查询。
元数据与辅助数据结构
- 列统计信息:这是驱动剪枝的主要低成本工具。
- 清单文件级:记录每个数据文件中各列的最小值/最大值。
- 数据文件(Parquet行组)级:每个行组也记录列的最小值/最大值。
当数据按某列良好聚类时,其统计信息范围狭窄,剪枝高效;反之,统计信息范围宽泛,剪枝效果差。
- 布隆过滤器 (Bloom Filter):一种概率数据结构,用于快速判断某个值是否肯定不存在于某个文件或行组中。对于未排序列或等值查询,它能提供最小值/最大值范围之外的另一层高效筛选。
- 其他辅助文件:如更精细的直方图、表级布隆过滤器(Hudi)、主键到文件的映射索引(Hudi, Paimon)等,用于加速特定操作(如 Upsert)。
- 物化视图/预计算投影:这可能是最接近 RDBMS 二级索引概念的策略。通过预计算并以优化后的格式(如 Dremio Reflections)存储派生数据集,查询引擎可透明地重写查询以使用这些投影,从而以额外的存储和维护成本换取特定查询模式的极致速度。
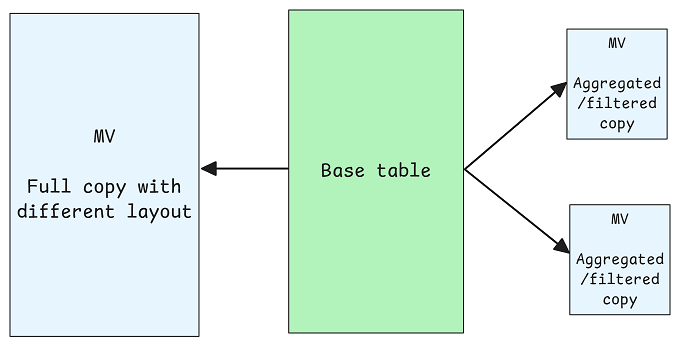
开放表格式设计哲学小结
- Iceberg、Delta 等格式将数据存储在不可变的列式文件中,针对大规模分析扫描优化。
- 性能取决于数据跳过(剪枝) 能力。
- 数据布局(分区、排序、压缩)是剪枝有效性的基础。
- 列统计信息和布隆过滤器是关键的辅助元数据结构。
- 物化视图通过数据复制的形式,提供了类似二级索引的、支持多样化查询的能力,但需要权衡存储与维护成本。
分析数据建模的作用
单一表的物理布局并非全部,数据建模同样关键。例如,在星型模式中:
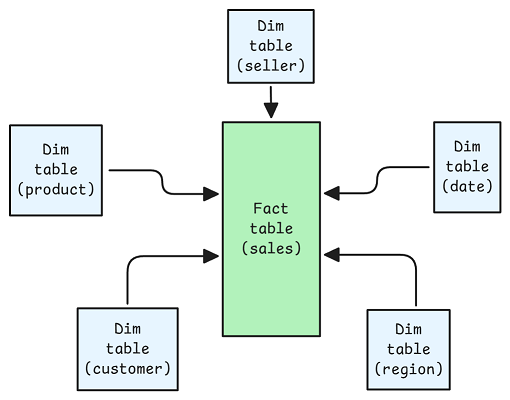
查询模式高度可预测:对小维度表进行筛选,然后通过外键连接到大事实表。这种结构使得各种分析查询无需二级索引也能高效运行。在基于 Iceberg 实现时,事实表应按粗粒度时间或地区分区,并在分区内按高选择性的外键(如 customer_id)排序,使物理布局与逻辑访问路径对齐,最大化 Iceberg 元数据剪枝的效力。
结论
深入观察可以发现,关系数据库的聚集索引与开放表格式的 Parquet 层及元数据层有着共同目标:最大化减少扫描的数据量。区别在于,开放表格式(OTF)不维护严密的 B 树结构,而是依赖更松散的数据布局和轻量级元数据来指导搜索(剪枝本质是一种搜索优化)。这对于扫描百万行的分析工作负载是合理的,因为流式读取大块连续数据的成本远低于随机指针追踪和维护庞大 B 树。
在开放表格式的世界里,布局即王道。性能取决于布局(分区、排序、压缩)与查询模式的匹配度,以及数据建模(如星型模式)的合理性。由于 OTF 表的数据通常只存储一份,其布局必须反映主要查询模式。若要支持多元化查询,以物化视图形式进行数据复制是一种有效策略,这与二级索引的空间换时间权衡类似。
未来,开放表格式可能会通过规范更丰富的性能导向元数据(如标准化的高级统计信息)来演进。而像物化视图、自适应聚类等更上层的智能优化,则将由各云原生数据引擎在其基础上构建,成为平台的差异化能力。
那么,在这个世界里,“索引”究竟指什么?最接近的概念或许是布隆过滤器,而列统计信息和物化视图也扮演着类似角色——引导查询规划器提升效率。传统的二级索引已不复存在,但“索引”一词可能仍会沿用,泛指整个提升系统效率的元数据与优化结构生态。
 发表于 2025-12-16 22:07:19
|
查看: 213|
回复: 0
发表于 2025-12-16 22:07:19
|
查看: 213|
回复: 0
