三、NLP的工作原理

3.1 文本预处理

3.1.1 概述
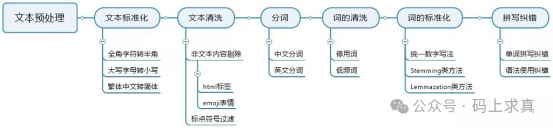
3.1.2 文本标准化
文本标准化旨在将不同格式的文本统一,为后续处理奠定基础,主要包括字符编码、英文大小写和中文繁简体的统一。
-
字符编码标准化(全角英文字符转半角)
在计算机中,所有中文字符都是全角字符,而英文字母、阿拉伯数字及符号有全角和半角两种unicode编码方式。它们的全角字符unicode编码从65281~65374 (十六进制 0xFF01 ~ 0xFF5E),半角字符unicode编码从33~126 (十六进制 0x21~ 0x7E)。空格符比较特殊,全角unicode编码为12288 (0x3000),半角为32 (0x20)。
除空格符外,每个全角字符的unicode编码等于其半角字符的unicode编码加65248,因此转换实现代码如下:
#全角转半角
def full_to_half(text:str):
#输入为一个句子
_text = ""
for char in text:
inside_code = ord(char) #以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值
if inside_code == 12288: #全角空格直接转换
inside_code = 32
elif 65281 <= inside_code <= 65374: #全角字符(除空格)根据关系转化
inside_code -= 65248
_text += chr(inside_code)
return _text
-
英文大小写字母统一化
英文字母大小写的统一化可直接借助Python内置字符串方法实现:
#大写字母转为小写字母
def upper2lower(text:str):
return text.lower()
-
中文繁简字统一化
中文繁体字与简体字的统一化可以借助opencc包的OpenCC类实现。在Python开发中,该类通过不同的转换功能代码实现不同的文字转化功能,常用代码表如下:
| 转换代码 |
功能说明 |
| t2s |
繁体中文转简体 |
| s2t |
简体中文转繁体 |
| s2tw |
简体中文转换成繁体中文(台湾标准) |
实现代码如下:
from opencc import OpenCC
#繁简体统一化
def chinese_standard(text:str, conversion='t2s'):
cc = OpenCC(conversion)
return cc.convert(text)
3.1.3 文本清洗
文本清洗常通过Unicode码过滤来去除非文本内容。Unicode码表中,中日韩统一表意文字字符区间为 4E00~9FA5,半角英文字母、阿拉伯数字及符号的字符区间为 0x21~0x7E。因此,标准文本字符范围为 $[\text{4E00}, \text{9FA5}] \cup[\text{0x21}, \text{0x7E}]$。
非文本内容过滤与标点符号过滤可借助正则表达式实现:
import re
def clear_character(text):
#只取合法字符
pattern = [
"[^\u4e00-\u9fa5^a-z^A-Z^0-9^\u0020^\u0027^\u002e]", # save_standing_character
"\.$" # remove_full_stop
]
return re.sub('|'.join(pattern), '', text)

3.2 文本分析
3.2.1 分词
-
分词任务分类
根据语言特点,分词任务主要分为两大类。
- 拉丁语系文本分词(如英文):英文单字成词,且词与词之间由空格隔开,任务较为简单,直接按空格切分即可。
- 中文文本分词:中文多字成词,且词与词之间没有明显区分标志,因此分词较为复杂,需借助词表和算法实现。目前技术已相对成熟,实际工作中常使用Jieba分词等开源工具直接完成。
-
分词算法原理
中文分词主要分为基于词库匹配规则的算法和基于概率统计的算法。
- 基于规则的分词:常使用最大匹配算法,不考虑句子语义。它包括前向、后向和双向最大匹配。核心思想是贪心地匹配最长的词典词。
- 效率优化:将词典中同长度单词编制成哈希表,然后将文本子字符串进行哈希查找,可将时间复杂度从 $O(n^2)$ 降低到 $O(n)$。
- 基于概率统计的分词:考虑句子语义,先基于词库获取所有可能的分词组合,然后利用语言模型(如unigram模型)计算概率最大的组合作为结果。为提升效率,常结合维特比算法这一动态规划算法来快速求解最优路径(即概率最大的分词序列)。
3.2.2 词的清洗
词过滤通常在分词之后进行,用于移除对模型任务无用的词,主要包括两类:
- 停用词:频繁出现在所有文档中但不表示具体含义的虚词(如“的”、“了”),对预测无意义。
- 低频词:语料库中极少出现的词。是否去除需人工判断,某些低频但关键的词应保留。
# 加载停用词列表
stop_words = set([……])
word_list = [……]
filtered_words = [word for word in word_list if word not in stop_words]
3.2.3 词的标准化
词的标准化一般用于英文文本,旨在将不同形态的同一单词(如不同时态、单复数)统一映射。主要有两类算法:
- 词干提取 (Stemming):根据规则去除词缀,结果可能不是合法单词(如
flies -> fli)。
- 词形还原 (Lemmatization):更严格,需根据词典转换为词的原形(如
are -> be),结果一定是合法单词。
from nltk.stem.porter import *
stemmer = PorterStemmer()
word_list = [……]
stand_words = [stemmer.stem(word) for word in word_list]
3.2.4 拼写纠错
拼写纠错主要检查和改正两类错误:单词拼写错误和语法使用错误。这涉及到人工智能中常见的模式识别和语言模型应用。
-
单词拼写错误纠正原理
- 检测:识别不在词库中的单词。
- 纠正:在词库中找出与错误单词编辑距离最小的词进行替换。
-
编辑距离计算方法
编辑距离指将字符串A转换为字符串B所需的最少单字符编辑操作(插入、删除、替换)次数。
import sys
from collections import defaultdict
class StrEditDistance():
"""
计算两英文字符串的编辑距离
"""
# 初始化
def __init__(self, edit_costs={'insert':1, 'delete':1, 'replace':1}):
self.str1 = ''
self.str2 = ''
self.c_dic = defaultdict(int) # 动态规划结果记录
self._edit_costs = edit_costs
# 动态规划核心
def editCostFun(self, i, j):
# 判断是否已计算过
if self.c_dic[str(i)+','+str(j)] == -1:
# 基础条件
if i*j==0 and i+j==0:
self.c_dic[str(i)+','+str(j)] = 0
elif i*j==0 and i+j>0:
self.c_dic[str(i)+','+str(j)] = sys.maxsize
# 递归条件
else:
if self.str1[:i]==self.str2[:j]:
self.c_dic[str(i)+','+str(j)] = 0
else:
self.c_dic[str(i)+','+str(j)] = min([
self._edit_costs['insert'] + self.editCostFun(i, j-1),
self._edit_costs['insert'] + self.editCostFun(i-1, j),
self._edit_costs['insert'] + self.editCostFun(i-1, j-1)
])
return self.c_dic[str(i)+','+str(j)]
# 调用接口
def transform(self, str1, str2):
self.str1 = str1
self.str2 = str2
m = len(self.str1)
n = len(self.str2)
for i in range(m+1):
for j in range(n+1):
self.c_dic[str(i)+','+str(j)] = -1
return self.editCostFun(m, n)
# sed = StrEditDistance()
# sed.transform('app', 'apple')
-
工程实现方法
在实践中,更高效的方法是生成所有与错误单词编辑距离为1或2的候选词,然后在词库中查找这些候选词。
# 生成所有与给定字符串编辑距离为1的字符串
def gen_editOne_str(str_: str):
letters = 'abcdefghijklmnopqrstuvwxyz'
splits = [(str_[:i], str_[i:]) for i in range(len(str_)+1)]
inserts = [L+c+R for L,R in splits for c in letters]
deletes = [L+R[1:] for L,R in splits]
replaces = [L+c+R[1:] for L,R in splits for c in letters]
return set(inserts + deletes + replaces)
# 生成所有与给定字符串编辑距离为2的字符串
def gen_editTwo_str(str_: str):
return {edTwo_str for edOne_str in gen_editOne_str(str_) for edTwo_str in gen_editOne_str(edOne_str)}
|  发表于 2025-12-16 22:21:48
|
查看: 207|
回复: 0
发表于 2025-12-16 22:21:48
|
查看: 207|
回复: 0
