
论文题目:Inverse Knowledge Search over Verifiable Reasoning: Synthesizing a Scientific Encyclopedia from a Long Chains-of-Thought Knowledge Base
论文链接:https://arxiv.org/abs/2510.26854
发表时间:2025年11月7日
论文来源:arXiv
SciencePedia网站链接:https://www.bohrium.com/sciencepedia
被压缩的“暗物质”:传统知识体系的根本缺陷
从教科书到维基百科,人类构建的科学知识库普遍存在一个根本缺陷:为了节省认知成本,它们倾向于优先呈现结论,而将支撑结论的复杂推理过程进行极端压缩。这些庞大而未记录的推导网络,构成了人类知识体系中难以触及的“暗物质”。
这种“暗物质”的缺失导致两个关键问题:
- 知识难以验证:读者只能诉诸权威,而无法审查透明、逐步的思维过程。
- 跨学科链接断裂:一旦推导路径被压缩,学科内部及学科之间驱动创新的内在联系也随之被切断。
要逆转这种压缩,将推理过程外部化,需要一个远超人类能力的知识生成与验证引擎。当前,大语言模型(LLM)成为首个可行的候选者。但若直接让其提炼知识或撰写百科,往往会重蹈“重结论、轻推理”的覆辙,并继承原始训练数据中的“幻觉”问题。
为此,研究团队提出了一套两步走的解决方案:首先,系统性地构建一个规模庞大、可验证且高度互联的长思维链知识库;其次,将这个“解压缩”的知识库投射为一部人类可探索的、推理驱动的百科全书。
LCoT语料库:为何能成为可靠的知识基石?
研究团队认为,由现代LLM生成的长思维链语料库,形成了一种与LLM预训练数据(互联网语料)截然不同的新型数据分布。其独特性与可靠性源于两大支柱。
一、新颖性:推理的全新统计分布
LLM的预训练本质上是让其对齐互联网语料的分布,这类语料充斥着快速结论(“系统1”思维),缺乏逐步推演(“系统2”思维)。因此,基础模型几乎不具备生成长思维链的能力。
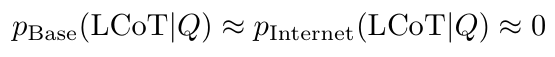
然而,通过采用“基于可验证奖励的强化学习”进行后训练,模型被优化为生成终点可被验证(如计算数值、推导公式)的推理轨迹。这一过程解锁了模型的长文本推理能力,使得经过训练的模型能够针对问题生成长篇、多步骤的思维链。最终,两个模型的生成分布出现巨大差异:经过优化的模型生成LCoT的概率远高于基础模型。
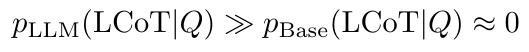
二、可靠性:因果与逻辑的固有一致性
LCoT的核心优势在于其终点的可验证性。多个独立的模型几乎不可能巧合地生成不同的错误推理路径,却最终收敛到同一正确答案。因此,通过“跨模型答案验证”达成的共识,可以用来筛选出具有高度因果与逻辑一致性的推理链,使LCoT语料库能够紧密贴合科学的真实结构。
LCoT知识库的构建:苏格拉底智能体的“还原论”策略
为了形成一个全面、互联且基于第一性原理的知识库,研究团队构建了以“长思维链问答对”为基本单元的新框架。它贴合科学探究的本质,为验证提供了清晰框架,并让庞大知识库变得可导航。
研究团队基于还原论策略开发了“苏格拉底智能体”,以规模化生成LCoT-QA对,其工作流程如图所示。
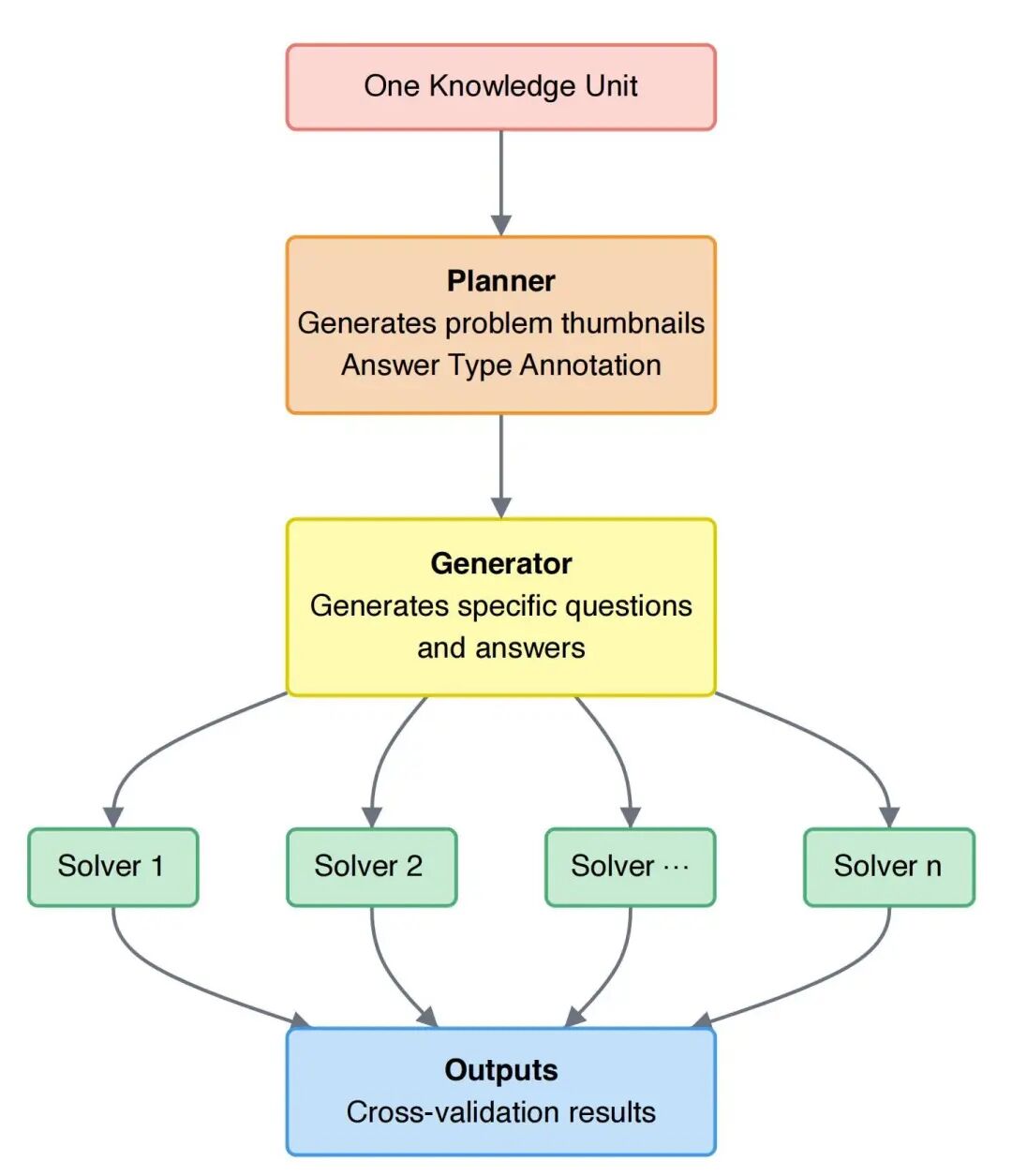
图1. 问题生成与交叉验证的三阶段流程。
苏格拉底智能体并非从公理“正向推理”,而是从高层知识点(即“终点”)出发,让模型从更基础的原理中推导出该知识点。这种策略能系统性确保知识覆盖的完整性。
为了让“终点”的定义更全面,团队开发了基于课程的支架式实现:手动整理了约200门本科与研究生课程,为每个核心主题自动生成了两类提示:还原论提示(What and Why),要求从第一性原理解释概念;应用提示(How),将理论与实际场景结合。
知识生成后,关键的多维度验证协议包括:提示词净化(滤除有瑕疵的问题)、可验证终点设计(偏向答案可客观验证的问题)、跨模型答案验证(不同LLM答案一致才保留)。
头脑风暴搜索引擎:让知识搜索变成“推理探索”
基于构建完成的LCoT知识库,研究团队开发了用于知识合成与发现的核心工具——头脑风暴搜索引擎。
该引擎的核心机制是反向知识搜索:用户提供一个目标概念,引擎即可检索出所有包含该概念的推导链,从而揭示概念的多元起源和应用。
例如,搜索“瞬子(Instanton)”,引擎不仅返回其定义,还会呈现其作为量子隧穿工具、在宇宙学中描述霍金辐射、以及在纯数学中推动四维流形理解等多维度的推导路径。
柏拉图智能体:让合成内容“有创意且无幻觉”
头脑风暴引擎发现的关联为AI科学写作的“幻觉”问题提供了解决方案。基于该引擎构建的柏拉图智能体,专注于结构化合成而非无约束生成。
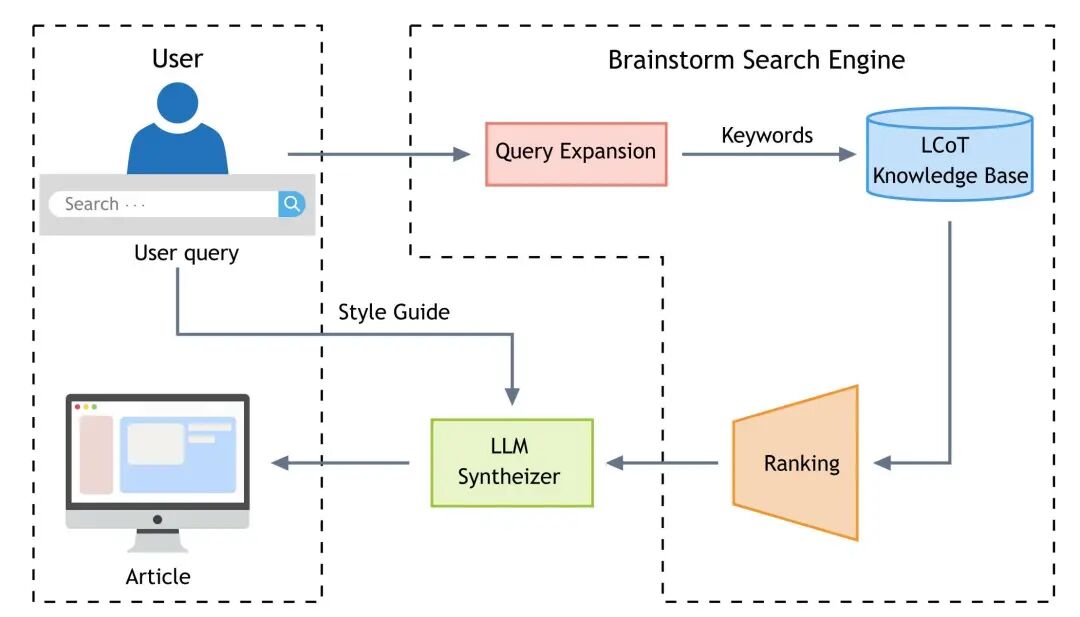
图2. 头脑风暴搜索引擎与柏拉图智能体架构。
柏拉图智能体以检索到的“跨领域推理支架”为基础进行合成,创意源于搜索过程中发现的“经过验证的惊喜关联”,同时大幅降低了“幻觉”风险。LLM的角色从“纯生成者”转变为“叙述者”,其核心任务是在已验证的概念间搭建“叙事桥梁”。
在六个科学学科的评估中,与无检索的基线模型相比,柏拉图智能体生成的文章“知识点密度”显著更高,“事实错误率”降低了约50%。
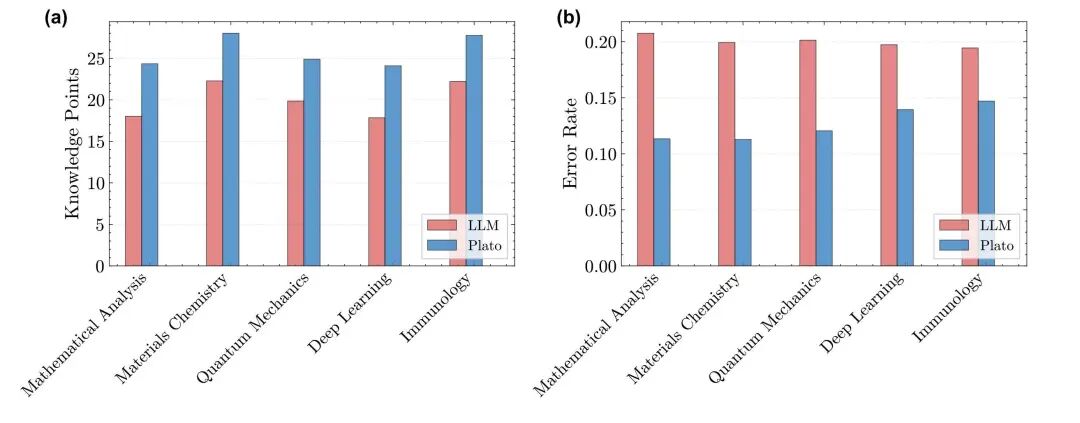
图3. (a)知识点密度与(b)事实错误率对比。
SciencePedia:从长思维链中“生长”的科学百科
最终,由苏格拉底智能体构建的可验证LCoT知识库催生出了SciencePedia——一部全面的、跨学科的STEM百科全书。其核心在于,庞大且多样的LCoT-QA对集合会自然形成一个密集的知识网络,连接从推导内容中自然涌现。
生成百科全书页面的过程是一个确定性的工作流:利用基于头脑风暴搜索引擎的柏拉图智能体,将原始的长链思维问答对转化为结构化的叙述。每个关键词页面都包括由“What & Why”部分构成的“原理与机制”核心章节,以及由“How”部分形成的“跨领域应用”章节。
与直接查询LLM或传统百科相比,SciencePedia在知识点密度、可靠性、解释深度和跨领域关联覆盖上更具优势。
为了验证其跨学科关联性,研究团队对关键词网络进行了大规模分析,发现不同学科社区间存在大量非平凡连接,这为SciencePedia捕捉跨领域关联的能力提供了直接实证。
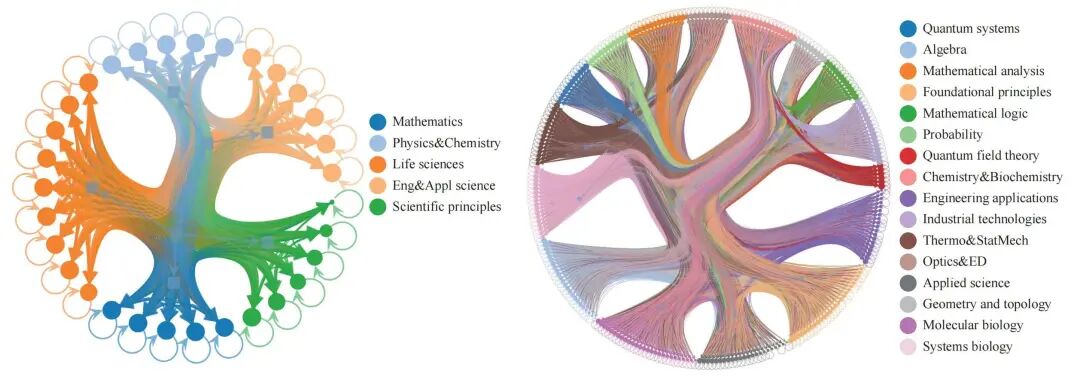
图4. 关键词图谱的层级结构,展示了跨学科社区间的复杂连接。
结语:从“解压缩”知识到构建协作式知识生态
这项研究的核心是解决现有知识体系“推理压缩”的根本局限。通过构建基于第一性原理的LCoT知识库、开发反向知识搜索引擎、设计低幻觉的合成器,最终打造出SciencePedia这一“涌现式”科学百科。这套人工智能驱动的框架不仅生成了规模庞大的可靠知识,更让知识回归“推理驱动”,解锁了被埋没的跨领域关联。
当前,SciencePedia涵盖数理化生工科等STEM领域,内容以客观事实与逻辑推理为主。未来,研究团队计划将LCoT方法应用于教科书、论文等其他高质量语料,以补充科学史、更新前沿研究,并将覆盖范围扩展到更多自然科学领域,致力于打造一个全面且动态演进的科学知识生态。
 发表于 2025-12-16 22:24:35
|
查看: 244|
回复: 0
发表于 2025-12-16 22:24:35
|
查看: 244|
回复: 0
