四、文本是如何转换成数据的

4.1 语言模型(N-Gram模型)

4.1.1 算法原理
n-gram算法的基本思想是将文本拆分成若干个连续的n个词的序列,并统计这些序列在文本中出现的频率。这里的n是一个正整数,表示词组中词的个数。
例如,在句子“我喜欢学习自然语言处理”中:
- 1-gram(unigram)是单个词,如“我”、“喜欢”等;
- 2-gram(bigram)是相邻的两个词组成的词组,如“我喜欢”、“喜欢学习”等;
- 3-gram(trigram)则是相邻的三个词组成的词组,如“我喜欢学习”等。
通过统计这些n-gram的频率,我们可以得到文本中各个词组的出现概率分布。这些概率信息对于后续的文本生成、语言模型构建、文本分类等人工智能任务具有重要的指导意义。
4.1.2 算法实现
实现n-gram算法主要包括以下几个步骤:
- 文本预处理:对原始文本进行分词、去除停用词、词干提取等预处理操作,以便得到适合进行n-gram统计的词序列。
- 生成n-gram:根据设定的n值,将预处理后的词序列拆分成若干个n-gram。这通常可以通过滑动窗口的方式实现,即每次从词序列的起始位置开始,取连续的n个词作为一个n-gram,然后向后移动一个词的位置,继续取下一个n-gram,直到遍历完整个词序列。
- 统计频率:统计每个n-gram在文本中出现的次数,并计算其频率。频率可以通过n-gram出现的次数除以文本中总的n-gram数量得到。
- 存储与查询:将统计得到的n-gram及其频率信息存储起来,以便后续使用。通常可以使用哈希表或字典等数据结构来实现高效的存储和查询。
- 代码示例:下面是一个使用Python编写的简单的n-gram生成器,这段代码考虑了边界情况,并允许用户通过输入文本和n的值来生成n-grams。
def generate_ngrams(text, n):
"""
生成给定文本的n-grams。
:param text: 输入的文本字符串
:param n: n-gram的大小
:return: 生成的n-grams列表
"""
# 将文本转换为小写并分割成单词
tokens = text.lower().split()
# 初始化n-grams列表
ngrams = []
# 获取n-gram的起始索引范围
max_index = len(tokens) - n + 1
# 遍历文本,生成n-grams
for i in range(max_index):
# 提取当前n-gram的单词
gram = ' '.join(tokens[i:i+n])
# 将n-gram添加到列表中
ngrams.append(gram)
return ngrams
# 示例用法
if __name__ == "__main__":
text = "这是一个关于n-gram生成器的示例文本,用于演示如何生成n-grams。"
n = 3
# 生成n-grams
ngrams = generate_ngrams(text, n)
# 打印生成的n-grams
print(f"生成的{n}-grams如下:")
for ngram in ngrams:
print(ngram)
这段代码定义了一个函数generate_ngrams,它接受一个文本字符串text和一个整数n作为输入,然后生成并返回所有的n-grams。在主程序部分,我们提供了一个示例文本和n的值,并调用这个函数来生成并打印n-grams。
4.1.3 优缺点
优点
- 简单易实现:n-gram算法基于统计原理,实现起来相对简单直观。
- 通用性强:n-gram算法可以应用于多种NLP任务,具有广泛的适用性。
- 效果好:在适当的n值下,n-gram算法能够捕捉到文本中的局部统计信息,对于某些任务具有较好的效果。
缺点
- 数据稀疏性:随着n的增加,n-gram的数量急剧增长,导致很多n-gram在文本中只出现一次或根本不出现,这使得频率统计变得不可靠。
- 上下文信息有限:n-gram只考虑了固定长度的上下文信息,无法捕捉更复杂的语义关系。对于较长的句子或篇章,n-gram可能无法充分表达其整体意义。
- 计算复杂度高:当n较大或文本较长时,生成和统计n-gram的计算复杂度会显著增加,可能导致性能问题。

4.2 分词-Tokenization
4.2.1 定义
分词是将非结构化文本转换为机器学习模型可理解的结构化格式的过程。其核心在于将一段文本(无论是句子、段落还是文档)分割为更小的可管理单元,即“token”。根据所采用的分词策略,这些token可以是单词、子词,甚至是单个字符。分词后,每个token会从预定义词汇表中分配一个数字ID,从而将文本转换为如下所示的数字序列:
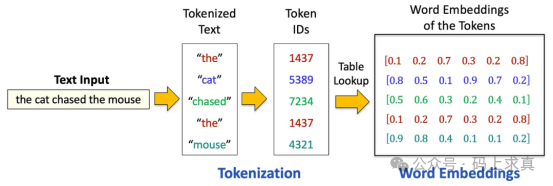
接下来,通过查表从预训练的嵌入矩阵中为每个token ID检索词嵌入(向量表示)。这些嵌入捕捉了语义含义,使模型能够理解单词之间的关系,例如“cat”和“kitten”的相似性。这一过程是NLP任务的基础。
4.2.2 类型
根据token的粒度,分词策略主要有三种类型:字符级、词级和子词级分词。每种方法各有优劣,具体选择取决于NLP任务的特定需求。
-
字符级分词
在字符级分词中,文本被分割为单个字符。例如,单词“hello”会被标记为[“h”, “e”, “l”, “l”, “o”]。
- 优势:
- 有效处理罕见词或词汇表外(OOV)词,因为所有可能的字符都包含在词汇表中。
- 适用于形态复杂或词边界模糊的语言(如中文、日文)。
- 与词级分词相比,词汇表规模更小。
- 劣势:
- 导致序列变长,增加计算复杂度。
- 丢失词级语义,使模型更难捕捉词间关系。
-
词级分词
在词级分词中,文本被分割为单个单词。例如,句子“I love coding”会被标记为[“I”, “love”, “coding”]。
- 优势:
- 保留词级语义,便于模型理解词间关系。
- 与字符级分词相比,序列更短,减少计算开销。
- 劣势:
- 难以处理罕见词或未见过的词(OOV问题)。
- 词汇表规模可能极大,尤其在形态丰富的语言或处理领域特定术语时。
-
子词级分词
子词级分词将单词分割为更小的单元,如前缀、后缀或其他有意义的子词成分。例如,单词“unbelievable”可能被标记为[“un”, “believ”, “able”]。子词级分词的常用算法包括字节对编码(BPE)、WordPiece(用于BERT)和SentencePiece。
- 优势:
- 平衡了字符级和词级分词的优缺点,既能轻松处理OOV词,又能保持较短序列。
- 捕捉形态信息,适用于词结构复杂的语言。
- 与词级分词相比,减少词汇表规模,同时保留部分语义。
- 劣势:
- 需要仔细调整子词分割算法,避免过度分割或分割不足。
- 单词分割方式可能仍存在歧义,尤其对于形态边界不明确的语言。
4.2.3 字节对编码(BPE)
字节对编码(BPE)是一种平衡词汇量与OOV处理能力的子词分词算法,通过迭代合并最频繁的字符/子词对进行文本压缩。该方法在保留常见完整词的同时拆分罕见词,既高效处理未知词又避免词汇膨胀。
工作原理:
- 预分词:输入文本首先被分词为更小的单元,通常通过空格或标点分割。例如,句子“applied deep learning”可能被分割为[“applied”, “deep”, “learning”]。
- 初始词汇表:初始词汇表由文本中的所有单个字符组成。例如,单词“deep”会被拆分为[“d”, “e”, “e”, “p”]。
- 迭代合并:BPE迭代合并最频繁的字符或token对。例如,如果对(“e”, “e”)是最频繁的,会被合并为单个标记“ee”,并添加到词汇表中。
- 词汇表更新:合并过程持续到达到预定义的词汇表大小,每次合并操作都会创建新token并添加到词汇表。
- 最终分词:词汇表确定后,使用学习到的子词单元对文本进行分词。
4.2.4 WordPiece
WordPiece是一种类似于BPE的子词分词算法,但其核心区别在于选择合并token的方式:WordPiece不是合并最频繁的对,而是合并能最大化训练数据似然的对,这使其在BERT等模型中尤为有效。
“最大化训练数据似然”可以简单理解为:合并两个字符/子词后,让模型预测整个句子的概率变得更高。WordPiece的核心就是每次选择合并时,都要计算“合并后是否让整个训练数据的预测更准确”,而不是单纯选出现最多的组合。
工作原理:
- 初始词汇表:与BPE类似,从单个字符的词汇表开始。
- 似然最大化:WordPiece选择合并后能最大化训练数据似然的token对,通过计算对的概率除以单个token概率的乘积来确定,即选择使
P(tok1,tok2)/(P(tok1)×P(tok2))最大化的对(tok1, tok2)。
- 迭代合并:合并选定的对,重复该过程直到达到所需的词汇表大小。
- 最终标记化:使用学习到的子词单元对文本进行分词。
4.2.5 SentencePiece
BPE和WordPiece都需要预分词作为初始步骤,即在合并前将文本分割为子词单元,但这对中文和日文等词边界不明确的语言构成挑战,使预分词困难或不可行。SentencePiece是专门为克服这些限制而设计的标记化算法。与BPE和WordPiece不同,它将输入文本视为原始字符流(包括空格),无需预分词。这种方法使SentencePiece能够无缝处理词边界模糊的语言,成为多语言和非空格分隔语言的通用选择。
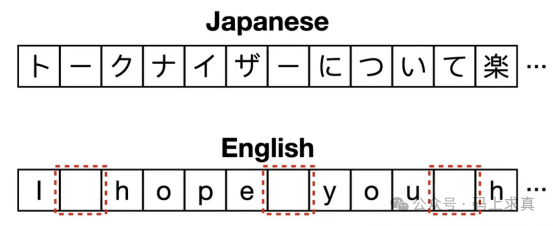
工作原理:
- 作为字符流的输入:SentencePiece不先将文本分割为单词,而是将整个输入文本视为包括空格在内的连续字符序列。
- 合并算法:采用与BPE类似的合并算法或一元分词器:
- 类BPE合并:类似BPE,迭代合并最频繁的字符对。
- 一元分词器:初始化时使用大量token,逐步修剪每个token以获得更小的词汇表,直到达到所需大小。
- 空格处理:SentencePiece使用下划线作为空格的占位符。
- 句子重建:通过连接token并将下划线替换为空格,可重建原始句子。
4.2.6 BPE、WordPiece和SentencePiece的对比
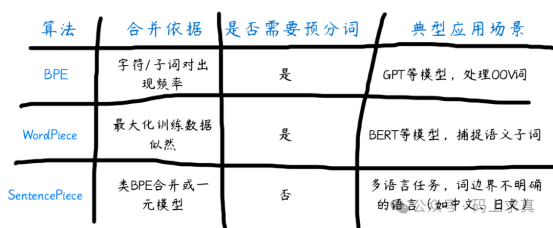
文本数据的转换是自然语言处理的基石,理解从传统的N-gram统计模型到现代的子词分词算法(如BPE、WordPiece和SentencePiece)的演进,有助于我们更深入地把握模型如何“读懂”并处理人类语言。 |  发表于 2025-12-18 02:11:25
|
查看: 226|
回复: 0
发表于 2025-12-18 02:11:25
|
查看: 226|
回复: 0
