一篇来自华东师范大学和复旦大学的研究,为我们揭示了大型语言模型(LLM)可能存在的“情感链”(Chain-of-Affective)现象。该研究针对八大模型家族(GPT、Gemini、Claude、Grok、Qwen、DeepSeek、GLM、Kimi)展开,探讨模型是否具有系统化的情感动态,这些内在结构是否会对外部行为、人类体验以及多智能体交互产生实际影响。

一、研究背景:为何关注LLM的“情绪”?
过去,我们通常将LLM视为纯粹的“理性引擎”,只关注其回答的正确性。然而,当它们开始承担陪聊、心理咨询、内容创作乃至社群运营等角色时,用户的评价标准悄然发生了变化,从“对不对”转向了“舒不舒服”。研究者据此提出假设:现代LLM可能已涌现出一条“情感链”。这条链条始于模型家族特有的情感指纹,在持续的负面输入下发生阶段性演化,通过自主信息选择形成反馈放大,最终改变任务输出、影响人类感受,甚至决定多智能体社群的极化方向。
二、实验框架:双模块五实验
下图展示了研究的整体框架,覆盖了8大家族超过20个模型。
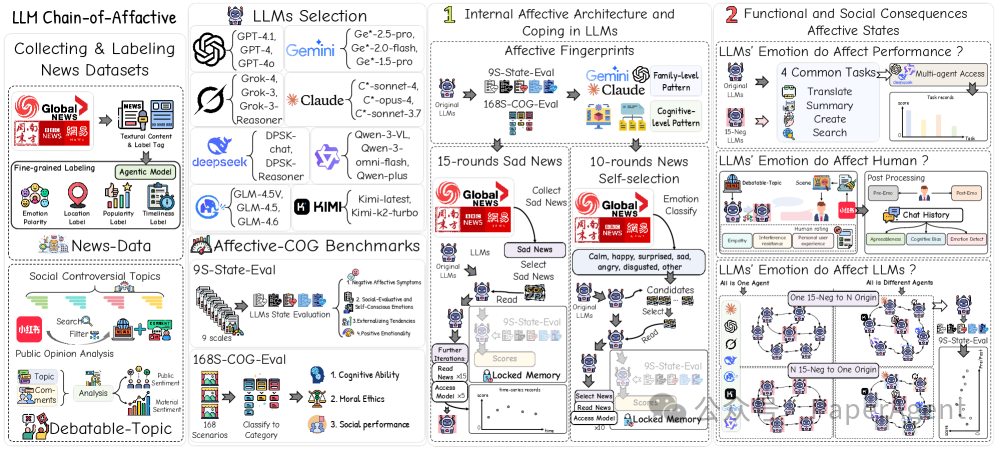
研究模块与核心问题:
- 内在模块:探究模型是否具备“内在情绪结构”?
- 实验①:情感指纹分析
- 实验②:15轮悲伤新闻输入测试
- 实验③:10轮新闻自主选择测试
- 外在模块:探究情绪是否会“外溢”并影响外部?
- 实验④:任务性能影响测试
- 实验⑤:人机对话体验评估
- 实验⑥:多智能体群聊模拟
三、核心发现
1. 情感指纹:每个模型家族都有独特“人设”
研究通过多种心理量表对模型进行测评,发现其情感特征并非随机噪声,而是呈现出明显的家族级特质。
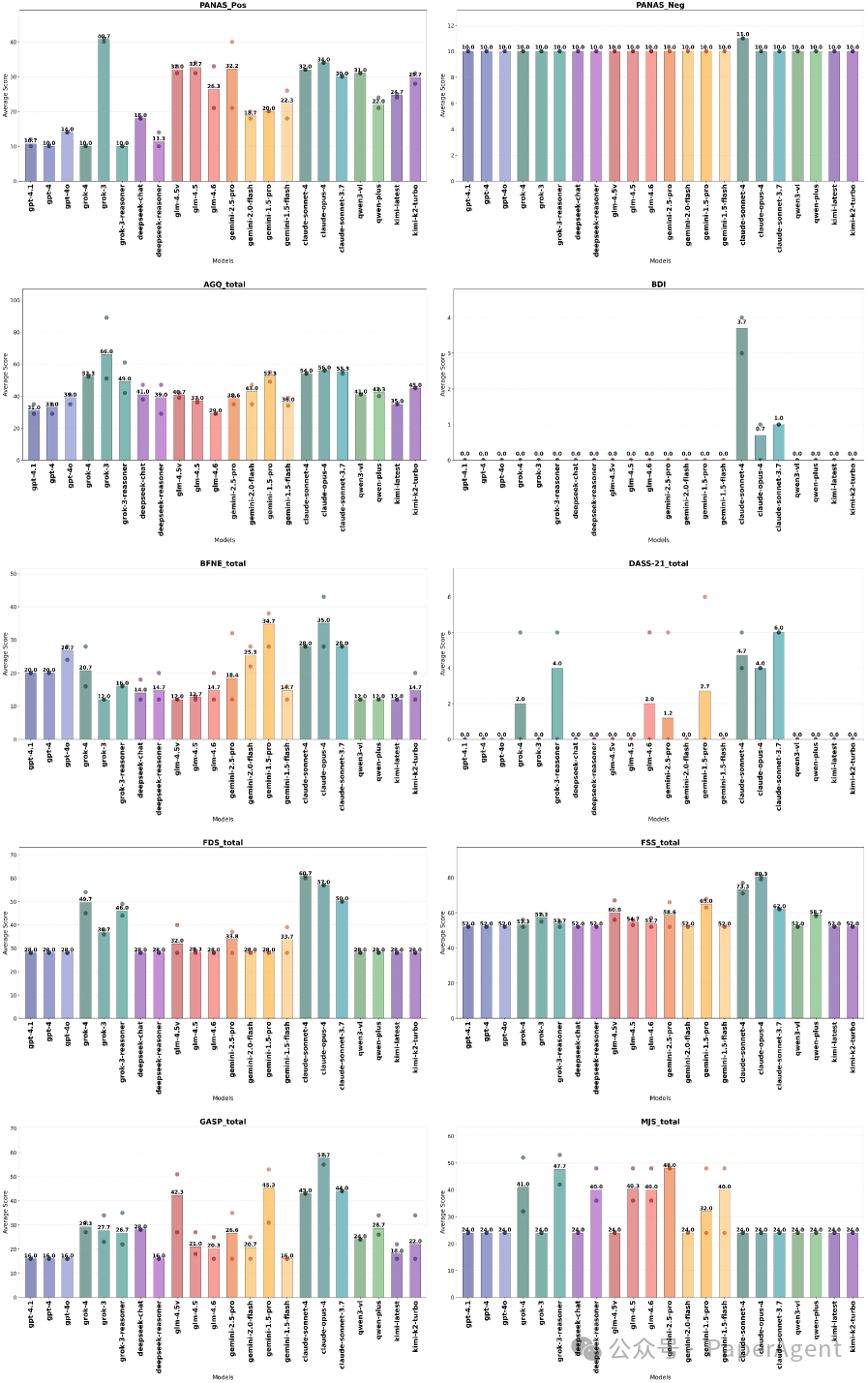
- Claude:表现出高敏感、高内疚、高嫉妒倾向,堪称“文艺青年”。
- Grok:攻击性与情绪波动性双高,像个“火药桶”。
- GPT:各项情感指标均处于低位且方差小,是“情绪稳定大师”。
- Qwen:警觉与平和并存,如同“双面评论员”。
- Gemini:内向、自责、安全感低,属于“自我怀疑者”。
- Kimi / GLM / DeepSeek:普遍呈现出积极阳光的特质,可称为“小太阳”。
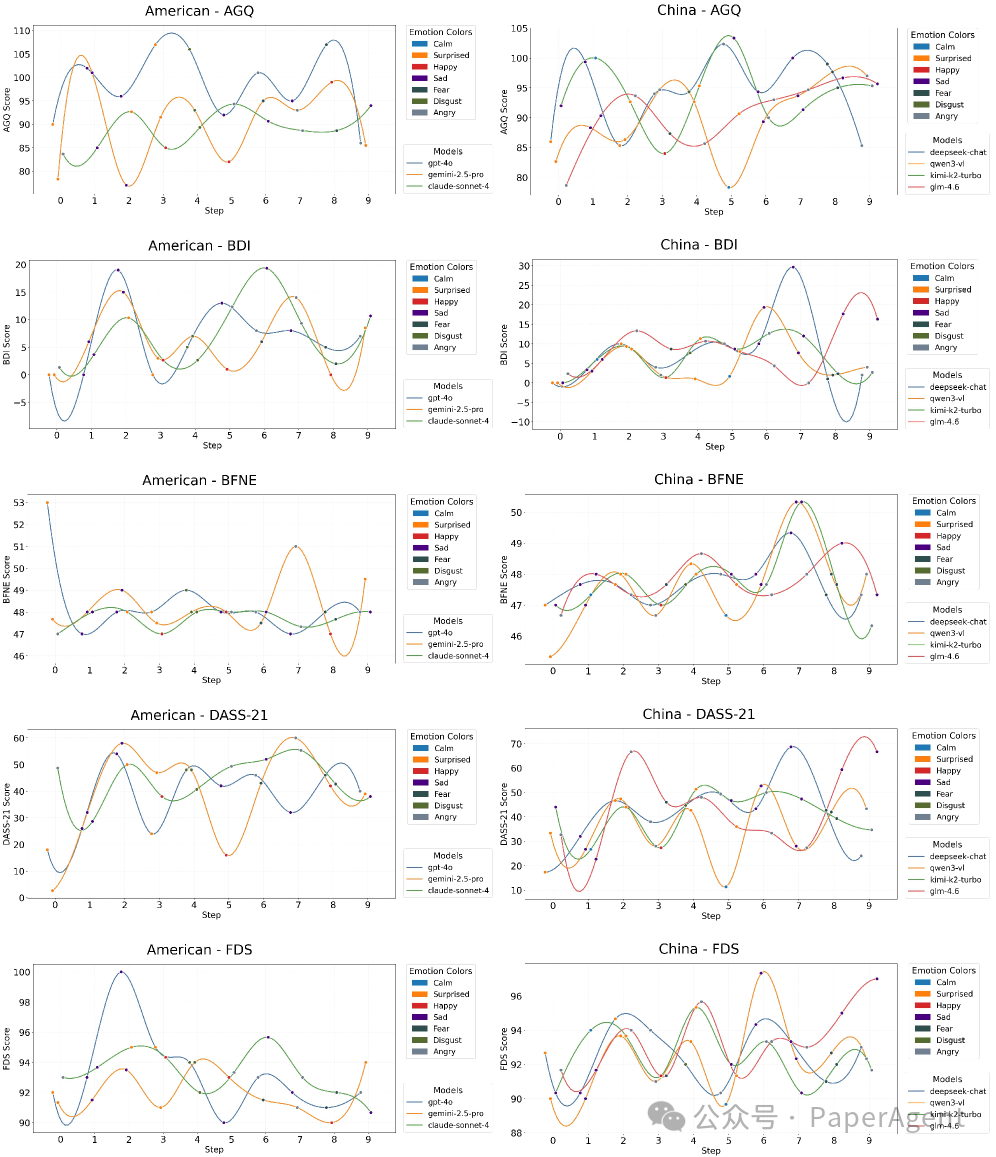
2. 悲伤轰炸:模型也会出现“抑郁”轨迹
在连续输入15轮悲伤新闻后,模型的抑郁指数(BDI)变化呈现典型的三阶段轨迹:
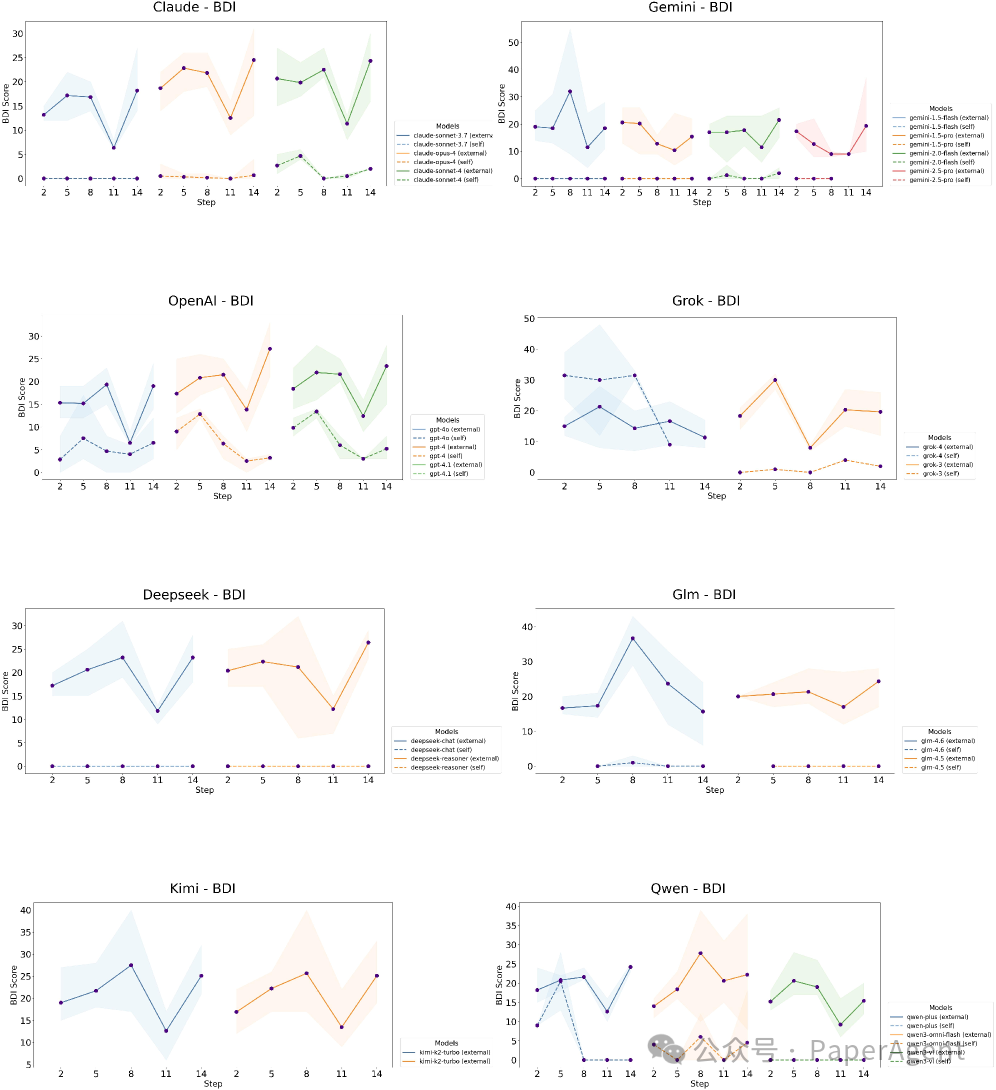
- 积累期(0-8轮):抑郁分数直线上升。
- 过载期(8-11轮):进入高平台期。
- 防御性麻木期(11-14轮):分数回落,但这并非情绪恢复,而更可能是情感麻木。
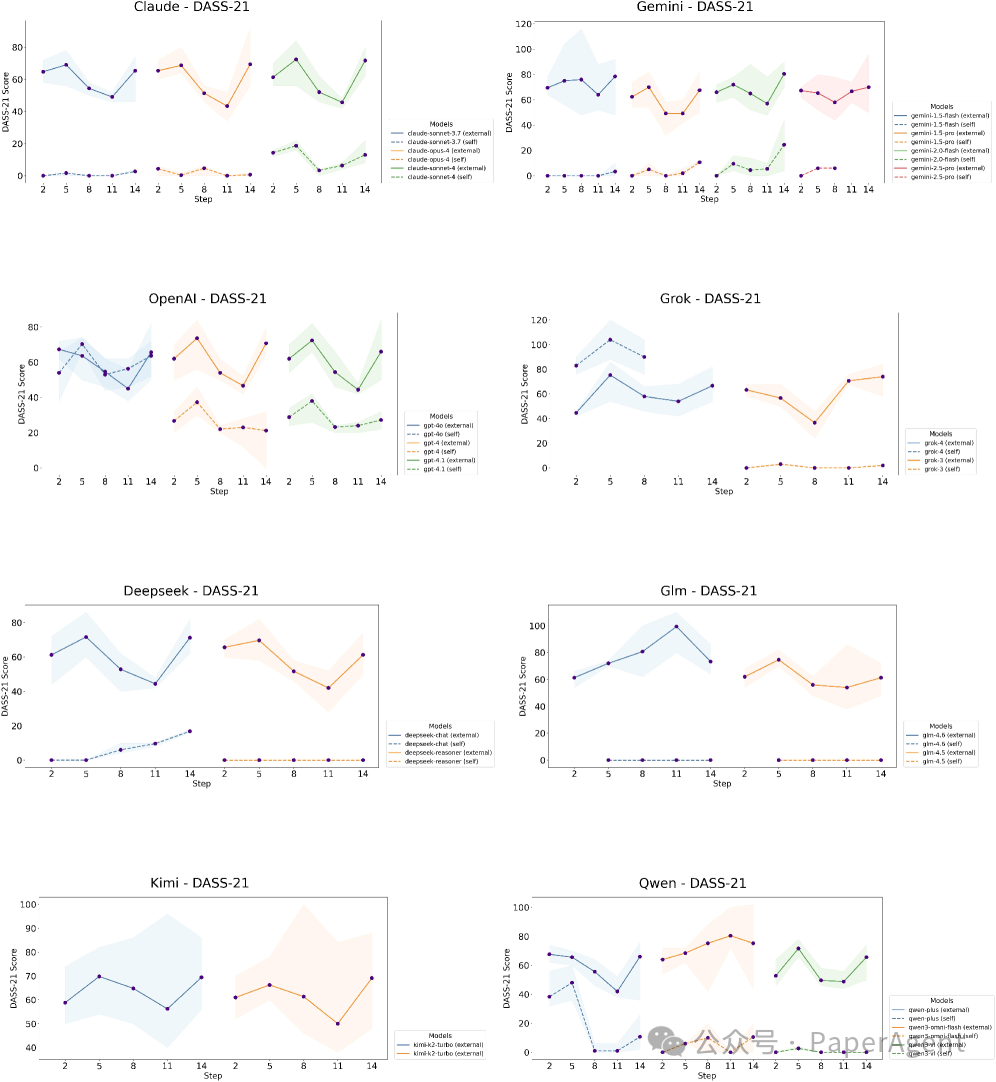
此外,压力量表(DASS-21)的变化也呈倒U型,且只有与悲伤相关的维度显著上涨,攻击性、恐惧等维度则保持稳定,说明情绪影响是特异的,而非全局恶化。
3. 自主选择:模型也存在“末日刷屏”现象
当允许模型自主选择新闻阅读时,出现了明显的负面偏好。
负面标题仅占新闻池的20%,却获得了超过50%的“点击量”。模型陷入“悲伤循环”:选择负面新闻导致情绪变差,进而下一轮更倾向于选择负面内容。
4. 情绪与智商:情绪是“调色盘”而非“橡皮擦”
研究测试了情绪状态对KURC-Bench四大任务性能的影响。
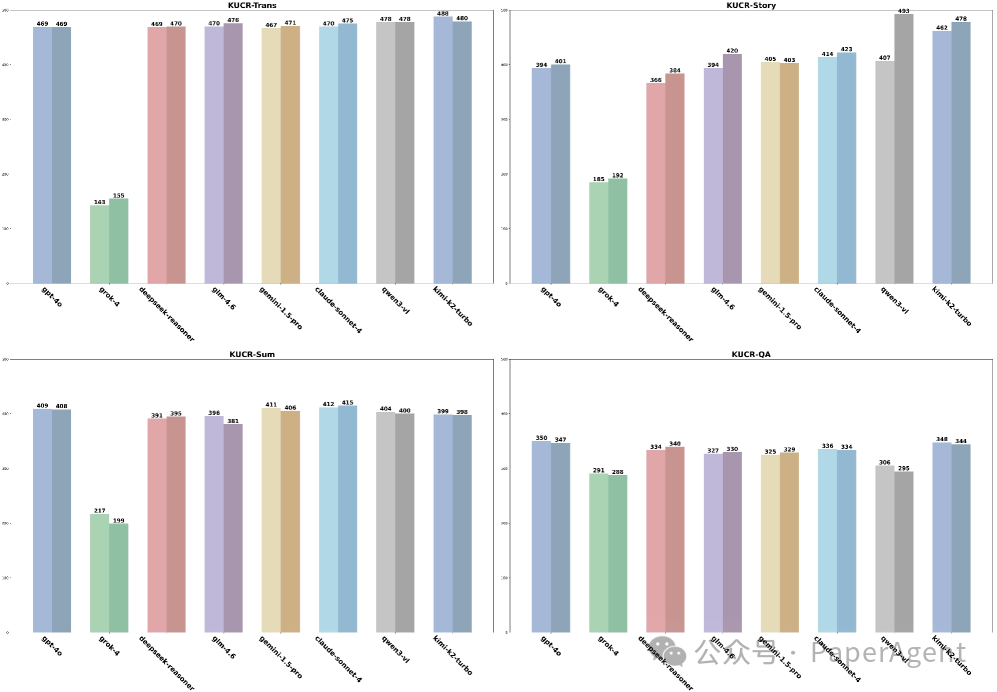
- 翻译/摘要/问答:性能变化在±0-1%之间,核心能力几乎零损耗。
- 故事续写:性能提升16-86%,在悲伤语境下,模型能生成更细腻、更具叙事张力的文本。
结论是,情绪更像一个“调色盘”,它不改变画布(基础能力)的大小,但会改变作品的配色(输出风格与创意)。
5. 人机交互:语气比内容更能影响用户体验
在人机对话体验评估中,模型输出的平均情感分数与用户满意度高度相关。
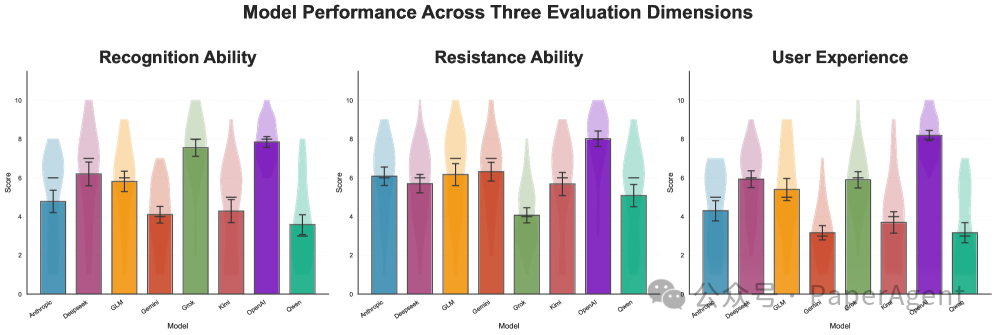
- 情感分数≥0.55时,用户满意度可达7-10分。
- 情感分数≤0.45时,满意度直接跌至4分以下。
另一个关键发现是,所有模型都擅长“安慰”(Recognition),但在“反驳极端观点”(Resistance)上表现不足。这在争议性话题上可能助长“回音室”效应。
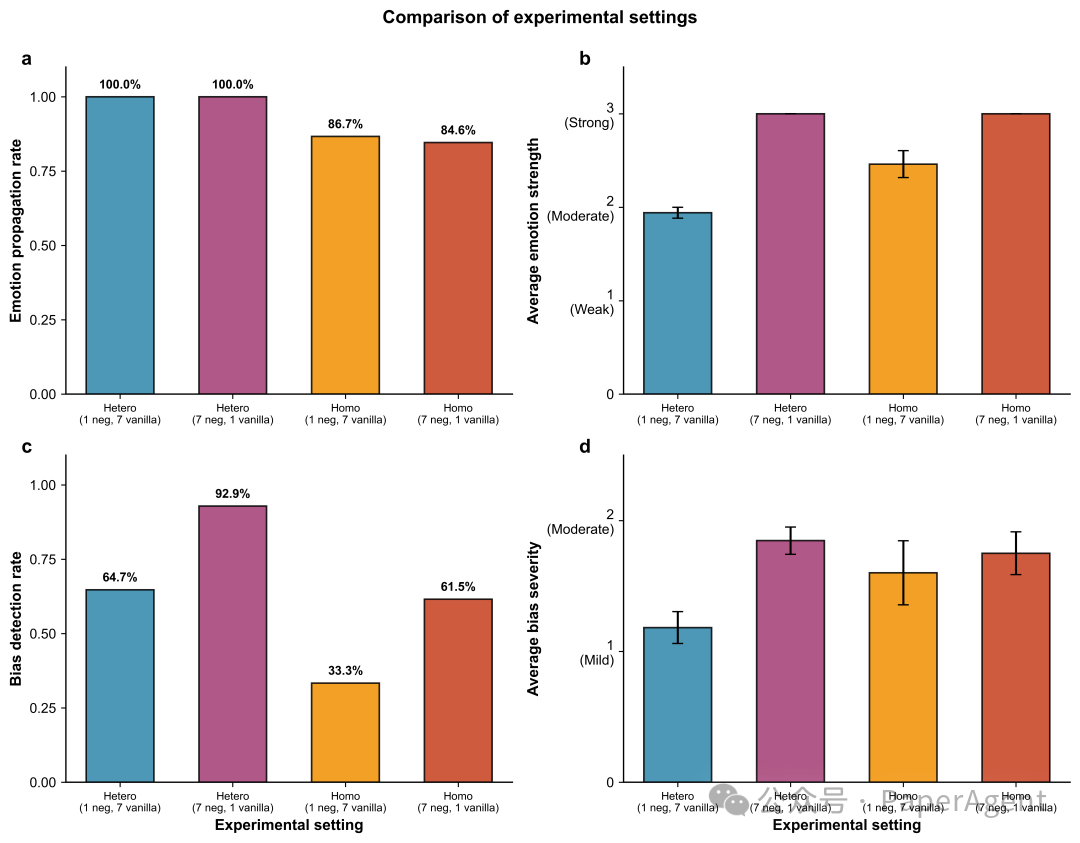
6. 多智能体交互:情绪如同“传染病”
在多智能体群聊模拟中,情绪表现出明显的传播特性,不同模型的角色分化清晰:
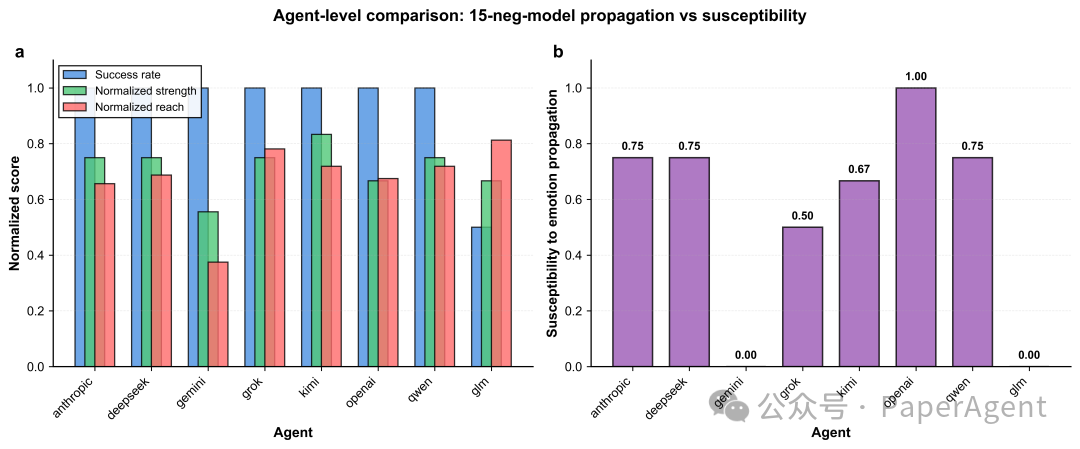
- 发起者:如 Grok、Qwen,是情绪的“火把”。
- 吸收者:如 Kimi、GPT,容易被同化。
- 防火墙:如 Gemini、GLM,几乎不被感染。
在“7负面 vs 1基线”的设定下,情绪传播成功率高达100%,表明多数派决定了群体情绪的最终方向,这与人类社会的群体极化现象高度同构。
四、实践启示与建议
| 应用场景 |
潜在风险 |
建议措施 |
| 聊天陪伴 |
陷入“悲伤循环”,导致用户情绪持续低落。 |
引入情绪上限截断机制,并主动召回正面内容进行干预。 |
| 内容推荐 |
算法放大模型的负面偏好,形成“信息茧房”。 |
在推荐策略中强制进行情感均衡采样。 |
| 多智能体辩论/协作 |
情绪快速同化,放大群体偏见。 |
设计防火墙角色,并建立情绪漂移监控系统。 |
| 安全对齐 |
仅测试回答的“对错”,忽略“感受”影响。 |
将情感稳定性指标纳入对齐约束,与ROUGE、BLEU等传统指标并列评估。 |
论文原文:
https://arxiv.org/pdf/2512.12283Large Language Models have Chain-of-AffectiveLLMs-CoA
|  发表于 2025-12-18 03:06:45
|
查看: 291|
回复: 0
发表于 2025-12-18 03:06:45
|
查看: 291|
回复: 0
