
商汤科技 ModelTC 团队近日开源了 LightX2V,这是一个专门针对视频生成推理阶段进行加速的轻量级框架。其核心目标并非训练新模型,而是通过系统级与模型级的深度优化,显著提升现有视频生成大模型的推理效率与资源利用率。
LightX2V 支持文本到视频(T2V)、图像到视频(I2V)等主流生成任务,并能在有限的硬件资源下实现接近实时的视频生成能力,在当前的开源视频生成生态中具有很高的实用价值。
一、LightX2V 是什么?
LightX2V(Light Video Generation Inference Framework) 是一个面向视频生成模型的统一推理加速框架。它综合运用了知识蒸馏、模型量化、特征缓存、注意力算子优化等多种技术,旨在大幅降低视频生成的推理开销。
其核心特点可归纳为以下三点:
- 专注推理优化:框架定位清晰,专注于提升已有模型的推理性能,而非训练。
- 追求极致能效比:在保证生成质量的前提下,最大化性能与资源消耗的比率。
- 面向实际部署:设计充分考虑了边缘设备、开发机及轻量级服务器等真实部署场景。
该框架本身不绑定特定模型,而是作为一个通用的“加速器”,为多种主流视频生成模型提供服务。
二、支持的核心功能
1️⃣ 多模态视频生成任务
LightX2V 覆盖了主流的视频生成输入形式:
- 文本到视频:根据文本描述生成连贯视频。
- 图像到视频:基于输入的静态图像生成动态视频序列。
框架通过统一的接口管理不同输入模态,有效降低了视频生成应用的工程复杂度。
2️⃣ 极致推理性能优化
这是 LightX2V 最具价值的核心能力:
- 大幅减少采样步数:将传统扩散模型需要的 40–50 步采样过程,压缩至仅需约 4 步。
- 无需CFG引导:能够在无需使用分类器自由引导(CFG)的情况下完成高质量推理。
- 显著缩短生成时间:官方测试数据显示,其推理速度相比原方案可提升数倍至一个数量级。
3️⃣ 低资源环境可运行
通过一系列系统级优化,LightX2V 使得大模型能够在资源受限的硬件上运行:
- 低显存需求:参数量达 14B 的视频模型可在仅 8GB 显存的 GPU 上运行。
- 动态卸载机制:支持模型权重、激活值等在 GPU、CPU 和磁盘间的智能调度与卸载。
- 广泛适配性:非常适合在边缘计算设备、个人开发机或轻量级服务器上进行部署。
4️⃣ 灵活部署与前端支持
LightX2V 提供了多种使用方式,以满足不同用户的需求:
- Gradio Web UI:提供快速体验与交互式调试的Web界面。
- ComfyUI 节点集成:方便习惯于可视化工作流(如 Stable Diffusion ComfyUI)的用户集成使用。
- Docker / 本地部署:提供标准化的容器镜像和清晰的本地安装指南,便于工程化落地。
- 硬件兼容性:不仅支持主流 NVIDIA GPU,也对国产硬件(如 Hygon DCU)进行了适配。
三、核心技术原理拆解
1️⃣ 步数蒸馏(Step Distillation)
通过知识蒸馏技术,框架将原本需要多步迭代的扩散采样过程压缩为极少的步数:
- 步数对比:从 40–50 步降至约 4 步。
- 核心收益:极大减少了单次推理所需的计算量,是实现“接近实时生成”的关键。
2️⃣ 多种模型量化策略
为降低显存占用,LightX2V 支持多种低精度推理方案:
- w8a8-int8 / w8a8-fp8:权重和激活使用8位整数或浮点数。
- w4a4-nvfp4:更为极致的4位量化。
量化能在尽可能保持生成质量的同时,显著降低模型对硬件的要求,使大模型在消费级硬件上成为可能。
3️⃣ 高效注意力算子集成
针对视频生成中 Transformer 模块的计算瓶颈,框架集成了多种经过优化的注意力实现:
- Flash Attention
- Sage Attention
- Radial Attention
- 定制高效 Kernel(如 q8-kernel)
这些优化算子对于处理视频生成任务特有的“长序列”和“高分辨率”数据至关重要。
4️⃣ 系统级缓存与存储调度
LightX2V 在系统层面进行了深入优化以应对显存压力:
- 特征缓存机制:避免在不同生成步骤中重复计算相同的特征。
- 三级存储结构:智能利用 GPU 显存、CPU 内存和磁盘,构建分层存储体系。
- 动态卸载:根据当前资源情况,按需将模型参数和中间结果卸载到下级存储。
这类设计是保证大模型在有限资源下“能够运行”而非“仅仅加载”的决定性因素。
5️⃣ 动态分辨率与帧插值
- 动态分辨率推理:在生成过程的不同阶段,动态调整计算分辨率以平衡速度与质量。
- RIFE 帧插值:利用帧插值技术提升生成视频的时间连续性与视觉流畅度。
四、已支持的模型生态
LightX2V 采取开放适配策略,目前已支持多个主流视频生成模型,包括:
- Wan2 系列(Wan2.1 / Wan2.2)
- HunyuanVideo-1.5
- 其他主流的 Diffusion / Transformer 架构视频模型
项目提供了对应的蒸馏权重、量化权重以及轻量化的 VAE(变分自编码器)模型,相关资源可在 GitHub 与 HuggingFace 获取。
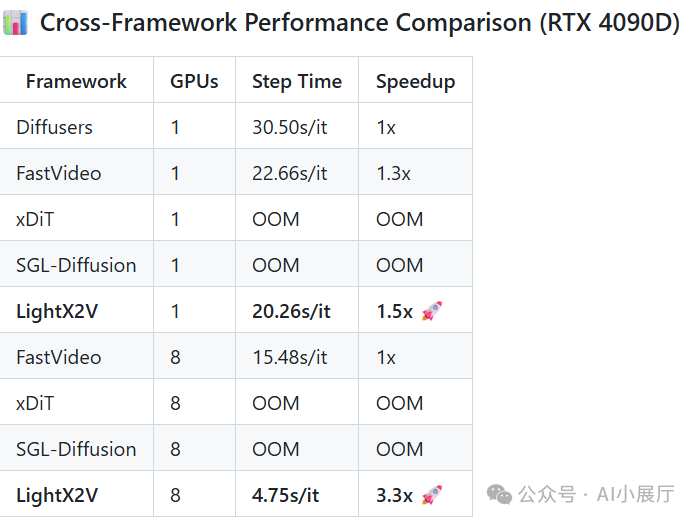
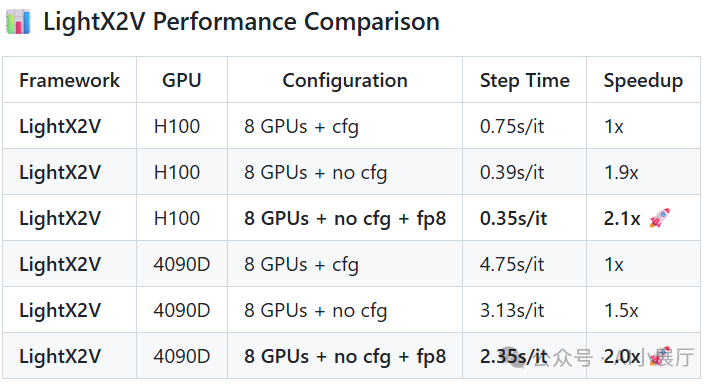
五、实际性能表现(官方数据)
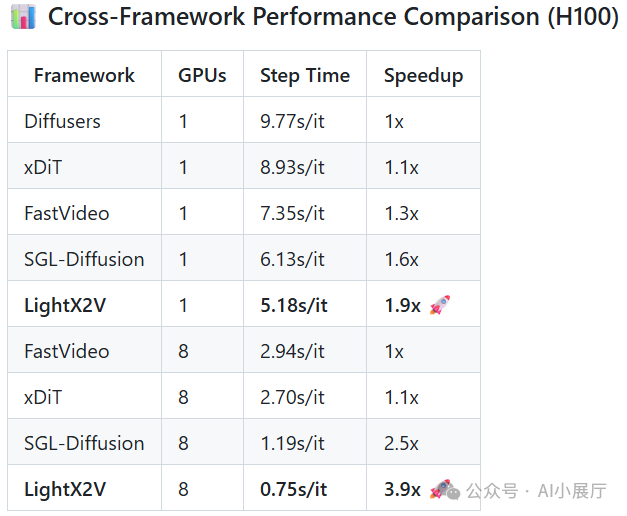
以 Wan2.1 14B 模型生成 480P 视频为例的性能对比:
| 推理方案 |
硬件环境 |
单步耗时 |
| Diffusers (基线) |
单 GPU |
~9.77s |
| LightX2V |
单 GPU |
~5.18s |
| LightX2V |
8 GPU |
~0.75s |
数据表明,在相同模型下,LightX2V 能带来显著的推理效率提升。对于希望快速搭建和优化AI视频生成服务的开发者而言,掌握高效的Python工程化实践和云原生部署技能同样关键。
六、项目地址
|  发表于 2025-12-18 03:59:16
|
查看: 241|
回复: 0
发表于 2025-12-18 03:59:16
|
查看: 241|
回复: 0
