本文旨在深入解析 LMCache 项目中 CacheBlend 技术的工程实现。基于 EuroSys ‘25 论文 CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion 的理论,我们将结合 LMCache 源码,详细解读如何通过“选择性重算与融合”机制,在检索增强生成(RAG)场景下,突破前缀缓存(Prefix Caching)的限制,实现对任意位置 KV Cache 的高效复用与推理加速。
1. 论文核心思想概述
- 论文标题: CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion (arXiv:2405.16444)
- 会议: EuroSys ‘25
- 代码: GitHub - LMCache
1.1 导论与背景
在现代LLM应用如检索增强生成(RAG)中,为了确保回复的准确性和一致性,模型输入通常由用户查询和多个检索到的文本块拼接而成。这些文本块为模型提供了必要的领域知识。然而,随着上下文长度的增加,这种模式给LLM推理系统带来了严峻的性能挑战。
RAG场景面临的核心矛盾:
- 极高的Prefill开销:LLM的Prefill阶段计算复杂度随序列长度呈超线性增长。处理长上下文需要消耗大量GPU算力,导致极高的首字延迟(TTFT),严重影响交互体验。
- 动态位置的文本复用:在RAG中,相同的文档块经常被不同的查询复用,但它们在Prompt中的位置通常不固定,可能出现在前缀、中间或末尾。
- 现有缓存技术的局限性:现有的 Prefix Caching 技术存在严格限制:它要求被复用的文本必须位于输入的最前端。对于RAG中常见的“非前缀复用”场景,直接复用会因上下文变化导致计算错误,使得系统难以享受KV Cache复用的性能红利。
1.2 核心挑战:Cross-Attention的影响
现有KV Cache复用技术(如Prefix Caching)要求被复用的文本必须严格位于输入的最前端。然而,在RAG中,文档块的位置是任意的。根据Transformer的Self-Attention机制,一个Token的KV值不仅取决于其自身的Embedding,还取决于它与所有前序Token的交互(Cross-Attention)。一旦文本块的位置发生变化,其前序上下文改变,导致预计算的KV Cache失效,直接复用会引发严重的精度损失。
1.3 CacheBlend解决方案
为了应对上述挑战,CacheBlend提出了一种选择性重算与融合机制。其核心思想是:以极小的计算代价(重算少量关键Token),换取对非前缀KV Cache的高精度复用。
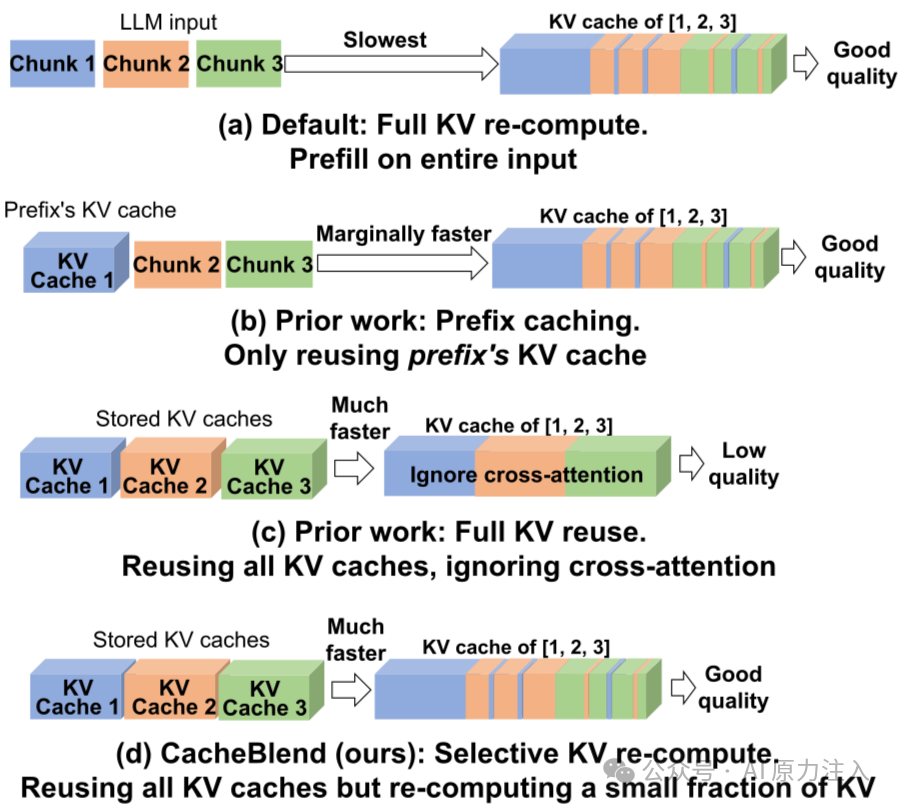
关键洞察:尽管Cross-Attention使得Token的KV值依赖于前文,但这种依赖具有稀疏性。研究表明,绝大多数Token的KV值对上下文变化不敏感,仅有少部分“关键Token”(如注意力机制中的Hub Token或语义转折点)的KV值会发生剧烈漂移。
基于此,CacheBlend设计了三阶段处理流程:
- 全量检索与融合:系统首先假设所有Token的KV Cache都是可用的,直接从存储后端(如磁盘/网络)检索并加载预计算好的KV Cache,无论文本块在Prompt中处于何种位置。
- 动态差异检测:为了识别受上下文影响最大的Token,CacheBlend会在推理的早期层执行一次“全量计算+比对”。计算当前上下文下生成的Key值与检索到的旧Key值之间的L2距离,并根据差异大小,动态选取Top-K个(如15%)偏差最大的Token作为“重算集合”。
- 稀疏重算与原地修补:在后续层中,系统仅对筛选出的关键Token进行KV重算,并将新计算的KV值“打补丁”到检索到的Cache中。最终,Attention层使用的是混合了“大部分旧值”和“少部分新值”的KV Cache。
1.4 性能收益
通过这种机制,CacheBlend在保证生成质量的前提下,显著提升了推理性能:
- TTFT降低:相比全量重算,首字延迟降低 2.2x - 3.3x。
- 吞吐量提升:推理吞吐量提升 2.8x - 5x。
- 存储与计算权衡:允许利用较慢但容量大的存储介质(如CPU内存/磁盘)存储海量KV Cache,通过计算换取I/O带宽的节省。
2. 架构设计与实现原理
LMCache在 lmcache/v1/compute/blend/ 模块中完整实现了CacheBlend的核心算法。其架构设计不仅关注算法本身的正确性,还深度优化了工程实现,特别是与vLLM推理引擎的耦合以及I/O流水线的调度。
2.1 核心组件与架构
LMCache的CacheBlend实现采用高度模块化的设计,将计算逻辑与存储逻辑解耦,并通过元数据进行状态同步,旨在实现计算与I/O的最大化重叠。
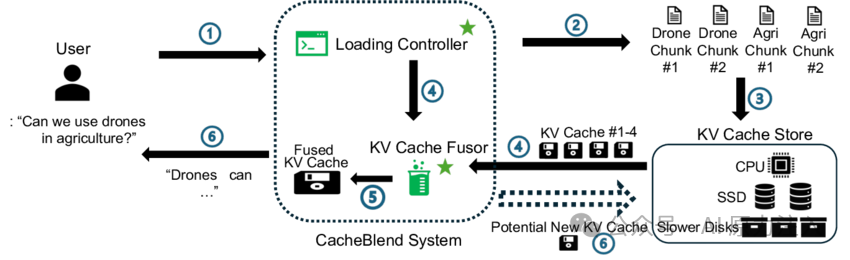
核心组件及其职责:
- LMCBlender (
blender.py):核心控制器。负责协调GPU计算和存储I/O,维护混合状态 (LMCBlendMetadata)。
- LMCBlendCommonMetadata (
metadata.py):静态配置元数据。存储 check_layers, recomp_ratios, thresholds 等全局配置。
- LMCBlendMetadata (
metadata.py):动态运行时元数据。存储当前请求的 imp_indices (关键Token索引)、positions 等信息,并在层与层之间传递状态。
- Layerwise Pipeline:将模型的层级计算抽象为生成器,实现细粒度的I/O与计算重叠。
2.2 关键配置参数
LMCache通过 LMCacheEngineConfig (config.py) 管理CacheBlend相关配置:
enable_blending: 总开关。开启后会强制设置 save_unfull_chunk=True,确保未满的Chunk也能被保存和复用。blend_check_layers: 差异检测层列表(如 [1])。blend_recompute_ratios: 重算比例列表(如 [0.15])。blend_min_tokens: 触发Blending的最小Token数(默认256)。blend_thresholds: (未来特性) 基于阈值的动态重算策略配置。
2.3 初始化与模型推断
LMCBlender 在初始化阶段会根据vLLM的模型结构构建一个“层级化模型执行器”。
# blender.py L24-L50
def __init__(self, cache_engine, gpu_connector, vllm_model, config):
# ...
# 1. 推断模型结构,构建支持逐层执行的 Wrapper
# enable_sparse 支持稀疏注意力 (Sparse Attention)
self.layerwise_model = infer_model_from_vllm(vllm_model, self, enable_sparse)
# 2. 加载静态配置
self.common_metadata = LMCBlendCommonMetadata(
check_layers=config.blend_check_layers,
recomp_ratios=config.blend_recompute_ratios,
thresholds=config.blend_thresholds,
)
# 3. 初始化动态元数据容器
self.metadata = LMCBlendMetadata(...)
2.4 核心逻辑:Process QKV
process_qkv 是CacheBlend算法的执行主体,它被注入到模型的Attention计算层中。
关键步骤解析:
- 位置编码:在计算差异之前,必须先对Q/K进行旋转位置编码(RoPE),因为存储在Cache中的
old_k 通常是经过RoPE处理的。
# blender.py L86
q, k = attn_layer.rotary_emb(self.metadata.positions, q, k)
- 差异检测:在Check Layer(如第1层),计算新旧Key的L2距离(的平方)。
# blender.py L88-L91
if layer_id in self.common_metadata.check_layers:
diff_k = torch.sum(
(k.to(torch.float32) - old_k.to(torch.float32)) ** 2, dim=[1]
)
-
Top-K选择:根据配置的 recomp_ratios 选取误差最大的Token,并确保至少选取1个且索引有序。
# blender.py L97-L101
topk_num = int(total_len * self.common_metadata.recomp_ratios[0])
topk_num = max(topk_num, 1) # 至少重算 1 个 Token
top_indices = torch.topk(diff_k, k=topk_num).indices
top_indices, _ = torch.sort(top_indices) # 保持索引有序
# 更新元数据,供后续层使用
self.metadata.imp_indices = top_indices
注意: 代码中存在 TODO remove [0] hardcode,表明目前仅支持单一比例配置,未来可能支持逐层动态比例。
- 混合:使用In-place Update更新
old_k / old_v。
# blender.py L115-L117
if self.metadata.imp_indices is not None:
old_k[self.metadata.imp_indices] = k
old_v[self.metadata.imp_indices] = v
# 返回混合后的结果
return q, old_k, old_v, ...
2.5 流水线调度:Blend Layer
blend_layer 函数展示了LMCache如何利用Python生成器实现精细的流水线控制,通过I/O与计算的重叠最大化吞吐量。
# blender.py L124-L150
def blend_layer(
self,
tokens: torch.Tensor,
mask: Optional[torch.Tensor] = None,
**kwargs,
):
"""
Perform layerwiese retrieve + blending.
"""
# 1. 创建计算和 I/O 的生成器
layerwise_model_executor = self.layerwise_model.compute_layer(tokens)
layerwise_retriever = self.cache_engine.retrieve_layer(tokens, mask, **kwargs)
# 2. 预取第一层 (Prefetch)
# 启动第 0 层的 KV 检索
next(layerwise_retriever)
yield
# 3. 交替执行 (Interleaving)
for i in range(self.num_layers):
# 触发下一层的 I/O (非阻塞/异步)
# 当计算第 i 层时,预取第 i+1 层的 KV Cache
next(layerwise_retriever)
# 执行当前层的计算 (包含 process_qkv)
next(layerwise_model_executor)
yield
# 4. 尾部清理
# 完成最后一次检索生成器的迭代
next(layerwise_retriever)
# 清理动态元数据(如 imp_indices),为下一次请求做准备
self.metadata.clean()
yield
设计亮点:
- 隐藏 I/O 延迟: 采用流水线并行思想。在GPU计算第
i 层时,并发地从存储后端检索第 i+1 层的数据,理想情况下I/O延迟被计算时间掩盖。
- 状态管理:
self.metadata 在层间共享,确保Check Layer选出的 imp_indices 能正确应用到后续所有层。
- 生成器控制: 通过
yield 暂停和恢复执行,使得外部调度器能够精确控制每一层的执行节奏,并与vLLM的调度循环无缝对接。
3. 如何在 LMCache 中使用 CacheBlend
要使用CacheBlend功能,需要配置LMCache并在构建Prompt时遵循特定的格式(插入分隔符)。
3.1 环境配置
可以通过环境变量或YAML配置文件开启CacheBlend。
方式一:环境变量:
# 启用 Blending 功能
export LMCACHE_ENABLE_BLENDING="True"
# 启用层级传输 (Blending 的基础,必须开启)
export LMCACHE_USE_LAYERWISE="True"
# 指定 Chunk 之间的分隔符 (用于逻辑切分)
export LMCACHE_BLEND_SPECIAL_STR=" # # "
# 指定在第几层进行差异检测 (通常为 1)
export LMCACHE_BLEND_CHECK_LAYERS="1"
# 指定重算 Token 的比例 (如 0.15 表示重算 15% 的 Token)
export LMCACHE_BLEND_RECOMPUTE_RATIOS="0.15"
方式二:YAML配置文件:
创建 lmcache_config.yaml:
chunk_size: 256
local_device: "cpu"
# Enables KV blending
enable_blending: True
# 必须开启 Layerwise 传输以支持 Blending
use_layerwise: True
# Blending 详细配置
blend_check_layers: [1]
blend_recompute_ratios: [0.15]
blend_special_str: " # # "
3.2 代码示例
在使用vLLM进行推理时,需要手动在不同的文档块之间插入配置好的分隔符 (LMCACHE_BLEND_SPECIAL_STR),以便LMCache识别边界。
以下代码片段展示了如何构建支持CacheBlend的Prompt:
# 引用自 examples/blend_kv_v1/blend.py
# 1. 获取分隔符 Token (必须与环境变量 LMCACHE_BLEND_SPECIAL_STR 一致)
# 注意:这里 [1:] 是为了去除 tokenizer 自动添加的 BOS token (如果存在)
blend_special_str_token = tokenizer.encode(" # # ")[1:]
# 2. 构建 Prompt
# 格式: <SysPrompt> <Separator> <Chunk1> <Separator> <Chunk2> ...
prompt_token_ids = (
sys_prompt_tokens
+ blend_special_str_token
+ chunk1_tokens
+ blend_special_str_token
+ chunk2_tokens
+ blend_special_str_token
+ user_query_tokens
)
# 3. 发送给 vLLM
llm.generate(prompts={"prompt_token_ids": prompt_token_ids}, ...)
3.3 运行逻辑验证
参考 examples/blend_kv_v1/blend.py 的逻辑,CacheBlend的生效流程如下:
- 初始化: 启动vLLM引擎,并配置
KVTransferConfig 以启用LMCache。
- 首次请求: 发送包含
Chunk1 + Chunk2 的Prompt。LMCache会计算并缓存这些Chunk的KV。
- 位置变化请求: 发送包含
Chunk2 + Chunk1 (顺序颠倒) 的Prompt。
- 触发Blending: LMCache会自动检测到Chunk内容已缓存但位置发生了变化,触发“选择性重算与融合”逻辑,从而加速推理。
4. 总结
CacheBlend是LMCache为应对RAG场景中复杂多变的KV Cache复用需求而提出的关键技术。通过本次源码分析,我们可以看到它如何将理论创新转化为高效的工程实现:
- 突破Prefix Caching限制:CacheBlend通过“选择性重算与融合”机制,成功解决了非前缀Chunk因Cross-Attention导致的KV失效问题,使得RAG系统可以灵活地复用任意位置的文档块缓存。
- 高效的工程架构:
- LMCBlender控制器:作为核心大脑,协调了差异检测、Token选择和混合更新的全过程。
- In-place Update:采用原地更新策略,最大限度地复用已加载的KV数据,仅对关键Token进行“修补”,极大地节省了计算资源。
- Layerwise Pipeline:将混合逻辑深度嵌入到I/O流水线中,实现了计算与数据加载的完美重叠,掩盖了I/O延迟。
- 易用性与灵活性:
- 提供了环境变量和YAML两种配置方式,方便用户集成。
- 通过特定的分隔符机制,让开发者能够以极低的侵入性改造现有的Prompt构建流程。
- 未来展望:源码中预留的TODO(如基于阈值的动态重算、逐层差异化比例)表明CacheBlend仍有进一步优化的空间,未来可能会引入更智能的自适应策略。
总而言之,CacheBlend在保证生成质量的前提下,通过巧妙的计算与存储权衡,显著降低了首字延迟并提升了系统吞吐量,为构建高性能的RAG服务提供了强有力的支持。对于想深入了解大型语言模型推理优化和缓存机制的同学,这份来自LMCache项目的实战解析值得细细研究。想与更多开发者交流此类前沿技术,可以关注云栈社区的相关讨论。
 发表于 2026-2-7 09:18:54
|
查看: 496|
回复: 0
发表于 2026-2-7 09:18:54
|
查看: 496|
回复: 0
