卷积神经网络(CNN)是处理图像等网格化数据的核心架构。上一篇我们介绍了CNN的基本概念,本文将从计算层面深入解析卷积、池化的具体机制,并厘清初学者易混淆的输入/输出通道概念。
一、CNN的核心思想:全连接网络的优化
为何全连接网络(FNN)不适用于图像处理?核心在于参数量爆炸与空间结构信息丢失。CNN在FNN结构基础上进行了两大关键优化:
- 局部连接:在FNN中,每个输出神经元需连接所有输入像素。而在CNN中,输出神经元仅连接输入图像的一个局部区域(即感受野)。这相当于将FNN中大量无关连接的权重置零,实现了稀疏连接,极大减少了参数量。
- 参数共享:在FNN中,不同空间位置的连接权重不同。而在CNN中,同一个卷积核(一组固定的权重)会在整个输入图像上滑动,无论特征出现在何处,都使用相同的权重进行计算。这进一步大幅降低了模型需要学习的参数数量。
下面,我们通过具体的计算过程来理解这些抽象概念。
二、核心操作:卷积与池化详解
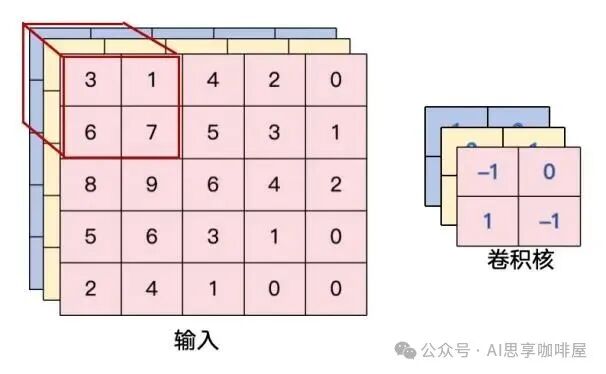
卷积的本质,是利用一个可学习的小窗口(卷积核)在输入数据上滑动,对窗口覆盖的局部区域进行加权求和,最终生成一张新的输出特征图。
以一个2×2卷积核处理5×5输入为例(假设步长=1,无填充):
卷积核每次覆盖一个2×2区域,区域内4个像素值分别与卷积核的4个权重相乘后求和,结果作为输出特征图中的一个像素值。
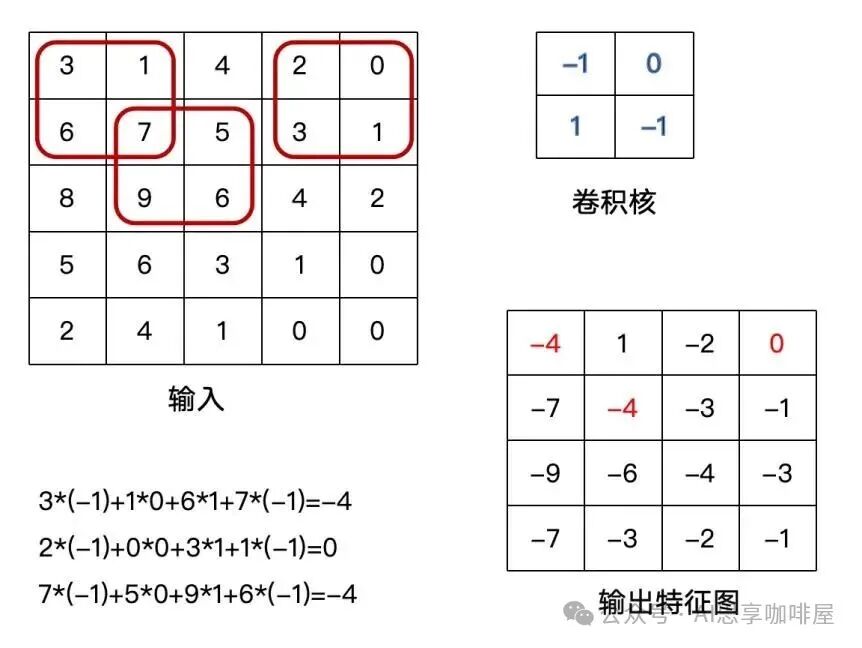
(注:此示例假设输入为单通道,如灰度图)
上例中输入为5×5,卷积核为2×2,输出的特征图尺寸为4×4。图中左下角展示了红色框区域的卷积计算过程,其计算结果对应右下角输出特征图中的红色数字。
关键概念解析:
-
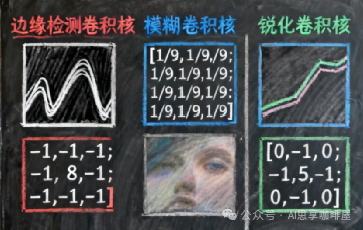
卷积核:CNN的基本计算单元,是一个可学习的权重矩阵(如3×3)。它在输入上滑动,通过计算局部区域的加权和来提取特定特征(如边缘、纹理)。不同的卷积核即是不同的特征检测器。
-
感受野:指网络中某一层特征图上的一个像素点,其计算所依赖的原始输入图像的区域大小。单层卷积的感受野有限(如3×3),但随着网络层数加深,通过多层叠加,高层特征能“看到”原始输入中越来越大的区域,从而整合从局部到全局的信息。
-
步长:卷积核每次滑动的像素距离。步长=1为逐像素滑动;步长=2则每次移动2个像素,通常用于对特征图进行下采样(降低空间尺寸)。
-
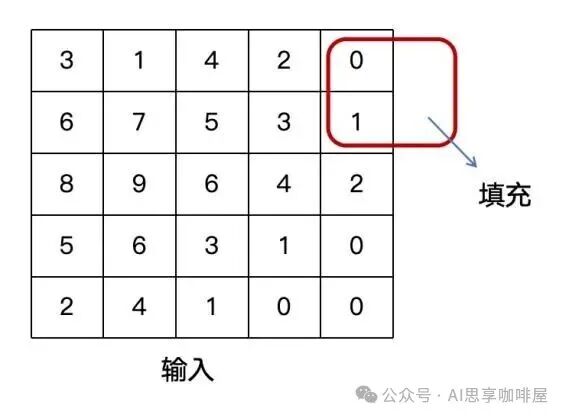
填充:在输入特征图的边界周围填充(通常为0)像素,以控制输出特征图的尺寸。例如,当步长=1时,设置 padding=(kernel_size-1)/2 可保持输入输出尺寸不变。
-
输出特征图:卷积操作后得到的二维网格,每个位置的值表示该处与卷积核所检测特征的匹配程度。例如,用边缘检测卷积核处理猫的图片,得到的特征图会突出猫的轮廓。
-
池化:一种降采样操作,用于压缩特征图、减少计算量并增强特征鲁棒性。最常用的是最大池化,即在指定窗口(如2×2)内取最大值作为输出。
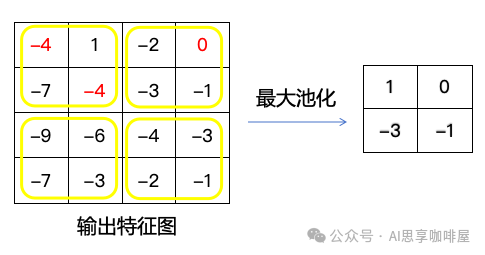
(注:通常在卷积后先经过ReLU等激活函数,再进行池化,上图简化了该步骤)
现代CNN架构中,常使用步长大于1的卷积层直接替代池化层来实现下采样,好处是参数可学习,功能上融合了特征提取与降维。
三、理解输入与输出通道:从2D到3D思维
这是理解CNN三维计算的关键,需要跳出二维图像的思维定式。
-
输入通道:输入数据的深度维,记为 C_in。
- 灰度图:
C_in = 1
- RGB彩色图:
C_in = 3 (红、绿、蓝)
-
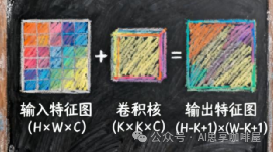
卷积核的真实形状:一个常见误解是将卷积核视为二维矩阵。实际上,单个卷积核的形状是 [C_in × kernel_height × kernel_width]。它在所有 C_in 个输入通道上同时进行滑动卷积,并将各通道的计算结果相加,最终生成一个二维的输出特征图。
- 例如,对于3通道的RGB输入,一个3×3卷积核的真实形状是 3×3×3。
-
输出通道:等于该卷积层所使用的卷积核的数量。每个卷积核独立扫描输入,生成一张特征图。
N 个卷积核 → N 个输出通道。- 网络中间层的输入通道数,即是上一层的输出通道数。
-
1×1卷积的神奇作用:其核心不在于空间特征提取,而在于通道维度的变换。
- 通道降维/升维:低成本地减少或增加通道数,控制模型复杂度与计算量。
- 增强非线性:在跨通道加权组合后接入激活函数,增加网络的非线性表达能力。
四、PyTorch代码实践
以下代码展示了如何使用 PyTorch 这一主流框架构建卷积、激活与池化层。
import torch
import torch.nn as nn
# 模拟一个批次大小为1的3通道32x32图像
input_img = torch.randn(1, 3, 32, 32) # [batch, channels, height, width]
# 定义卷积层:输入3通道,输出16通道,3x3卷积核,步长1,填充1(保持尺寸)
conv = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)
feature_map = conv(input_img) # 输出: [1, 16, 32, 32]
print("输入尺寸:", input_img.shape) # torch.Size([1, 3, 32, 32])
print("卷积后尺寸:", feature_map.shape) # torch.Size([1, 16, 32, 32])

# 接ReLU激活函数
relu = nn.ReLU()
activated = relu(feature_map)
# 接2x2最大池化层,步长2
pool = nn.MaxPool2d(kernel_size=2, stride=2)
pooled_output = pool(activated) # 输出: [1, 16, 16, 16]
print("池化后尺寸:", pooled_output.shape) # torch.Size([1, 16, 16, 16])

代码分析:
out_channels=16 意味着该层使用了16个不同的3×3卷积核,生成了16个输出特征图。padding=1 确保了在步长为1时,32×32的输入经过3×3卷积后空间尺寸不变。- 随后的2×2最大池化将空间尺寸减半至16×16,但通道数保持不变。
 发表于 2025-12-19 03:32:35
|
查看: 319|
回复: 0
发表于 2025-12-19 03:32:35
|
查看: 319|
回复: 0
