全球算力产业近期迎来密集的事件爆发期,海内外市场动向共同揭示着一个深刻的行业变革:由英伟达GPU长期主导的算力市场格局正在发生松动。
海外市场方面,非GPU赛道表现强劲。谷歌TPU获得了千亿级别的巨额订单,在GPU垄断的市场中撕开了一道口子。据博通CEO透露,AI公司Anthropic向博通下达了总值约210亿美元的订单,此外还有Meta等科技巨头的采购意向。与此同时,在GPU层面,出于对中国市场的考量,美国已批准英伟达向中国出售H200 AI芯片。
国内市场同样热度高涨。上海GPU企业沐曦股份成功在科创板上市,总市值突破3000亿元。北京AI芯片企业清微智能则完成了超20亿元的大额融资,其投资方阵容在业内颇为罕见。
这些动态共同指向一个明确的趋势:全球算力市场长期由单一架构垄断的局面已被打破。
当前,谷歌TPU、亚马逊Trainium3等非GPU芯片已在特定场景实现对GPU的规模化替代。国内市场数据也印证了这一点,2025年上半年,非GPU算力卡的市场占比已达到30%。寒武纪的MLU、昆仑芯的ASIC、清微智能的可重构芯片(RPU)等产品正凭借差异化优势快速崛起。
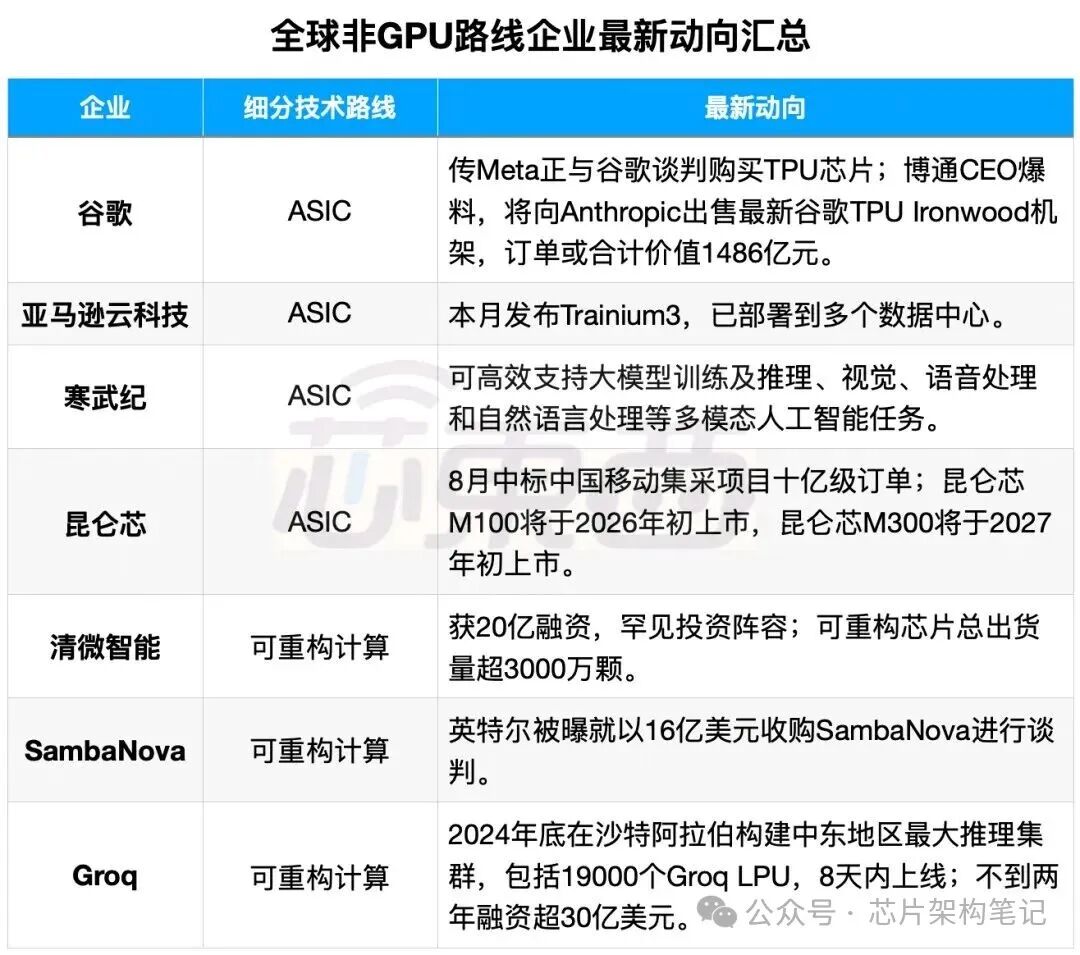
可以说,非GPU芯片势力的崛起已势不可挡,这标志着全球算力产业的下一阶段将面临显著的技术路径分化。
算力格局变革的三大驱动力
从需求、技术和生态三个核心维度分析,这场变革兼具必要性与紧迫性。
- 需求驱动:今年被视为大模型落地元年,推理场景的算力需求激增。单纯堆砌GPU的粗放模式已难以满足大模型规模化、高效落地的需求,倒逼企业寻求更具性价比的算力解决方案。
- 技术突破:传统冯·诺依曼架构的“存算分离”矛盾日益凸显,其设计逻辑在硬件性能上逼近物理边界。非GPU路线则在专用架构(如谷歌TPU)、动态可重构计算等方面实现多点突破,在特定场景下形成了性能和成本的双重优势。
- 生态重构:打破单一架构的生态垄断已成行业共识。国产开源框架正通过积极的兼容适配与自主优化,加速构建本土化的协同生态体系。
近日有报道指出,在AI芯片领域已形成自主可控的“芯片矩阵”,其中昆仑芯、寒武纪、摩尔线程、清微智能等一系列国产产品性能表现突出。这四家企业恰好代表了不同的技术路线:摩尔线程属于GPU阵营;寒武纪和昆仑芯主攻ASIC路线;清微智能则以可重构计算架构为核心。
行业发展的核心趋势
第一,GPU与非GPU两大技术路线并行发展。GPU凭借其成熟的软件生态和强大的通用并行计算能力,在需要兼顾图形渲染、科学计算与AI训练的综合场景中仍将保持核心地位。而非GPU路线,则随着AI应用深入,在推理及专用计算领域展现出巨大的增长潜力。其中,可重构架构因其良好的通用性,已在主流AI场景中占据一席之地。
第二,产业竞争重心从唯硬件性能论,转向涵盖软件、模型、场景适配的全栈能力竞争。通过软硬件协同创新,充分释放算力潜能,并针对不同硬件架构对模型进行压缩、量化与深度适配,正成为关键。
第三,中国厂商的话语权正在提升。在长期由欧美企业主导的算力市场中,中国企业在非GPU赛道上展现出强劲的竞争力,为全球产业格局注入了新的变量。
非GPU市场渗透率持续提升
市场研究数据支持了这一趋势。Gartner预测,到2027年,针对AI推理的算力需求将推动AI加速器(通常指非GPU的专用芯片)出货量超越GPU。IDC报告显示,2025年上半年,中国非GPU服务器在加速计算市场中的占比已达到约30%,并预计到2028年将接近50%。
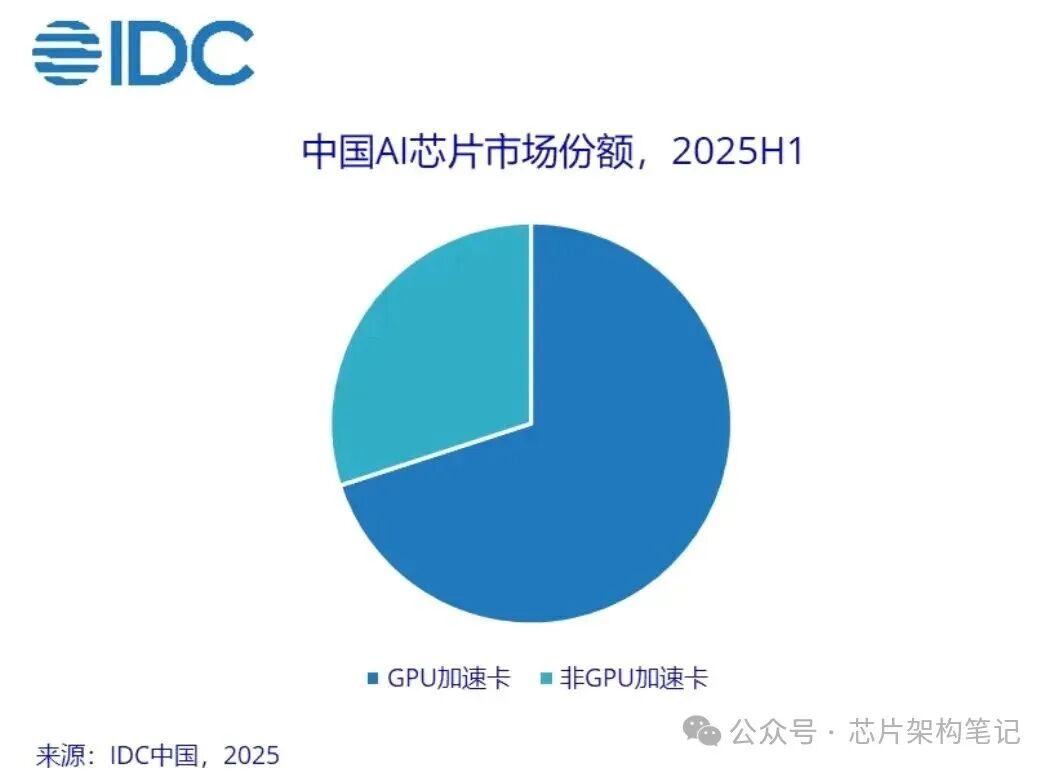
相比于GPU,非GPU技术在成本、能效比以及场景专用适配性上,与当前主流AI应用场景的需求更为契合。对于规模达千亿甚至万亿的AI市场而言,非GPU方案必将占据重要地位。
国产芯片企业的差异化布局
前文提及的四家北京芯片代表企业,是国内AI产业发展的缩影。
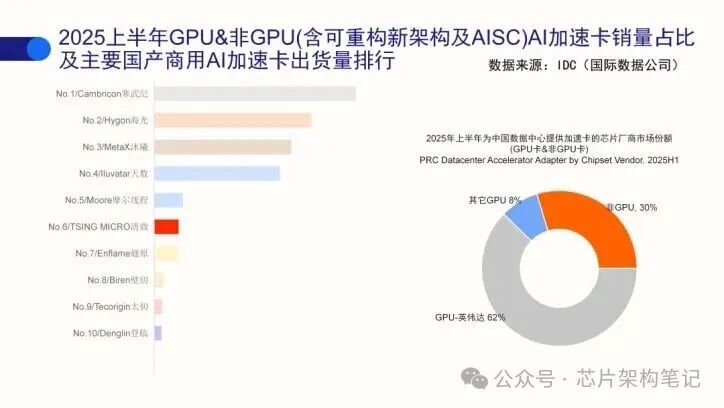
▲北京四家芯片代表企业2025年上半年出货量位居国内前列
其中,摩尔线程代表GPU路线,其余三家均为非GPU阵营:寒武纪与昆仑芯专注于ASIC路线,清微智能则主攻可重构计算架构。
ASIC路线是为特定用途定制的集成电路,谷歌TPU是典型代表。其核心优势在于极致的性能与功耗,以及支持深度定制,在AI浪潮中得以广泛应用。
- 寒武纪采用自研架构,产品覆盖云边端。其首款采用Chiplet技术的思元370芯片,INT8算力高达256TOPS,是前代产品的2倍。
- 昆仑芯基于自研XPU架构,其R200芯片可提供256 TOPS(INT8)算力,性能可达主流GPU的1.5倍。在实际部署中,单机4卡方案能满足千亿参数大模型的实时交互需求。
这些案例证明,非GPU架构对GPU的规模化替代已在特定领域全面展开。
相比之下,可重构计算路线发展势头迅猛。它精准地踩中了AI产业从算力集中走向场景细分的趋势,旨在解决GPU通用但低效、ASIC高效但硬件固化的行业痛点,通过底层架构创新实现了性能与灵活性的平衡。
清微智能以“软件定义硬件”为核心,推出了TX系列智能芯片,业务覆盖智慧安全、工业、办公、能源及机器人等多个领域。
可重构芯片(RPU)能够根据计算需求动态配置计算资源、互连结构和数据通路,具有高能效比、高灵活性和高扩展性的特点。清微智能的技术方案相比同类型产品,可实现整体成本降低50%、能效比提升3倍的效果。截至今年12月,清微智能的可重构芯片累计出货量已超3000万颗,2025年算力卡订单累计超3万张,并在全国十余座千卡规模智算中心实现规模化部署。

▲清微智能AI算力芯片TX81
此外,可重构数据流技术与AI计算需求天然适配。在芯片高效互联这一关键环节,其自研的TSM-LINK算力网格技术支持多芯片点对点直连,能实现高效数据传输,从根源上规避传统交换机架构的带宽瓶颈与延迟问题。而GPU在适配晶圆级集成时,通常依赖外部交换机,难以避免性能损耗。
据悉,清微智能下一代芯片将带来显著的性能跃升,有望在部分前沿AI计算场景实现跨越式发展。

结语:迈向多元共生的算力新时代
当前AI算力格局日渐清晰:GPU凭借成熟的云原生生态与极致并行能力,在通用大模型训练等核心场景地位稳固,但面临功耗与成本挑战;非GPU路线则凭借更高的能效比、更优的全生命周期成本及自主可控优势,在AI推理及专用计算领域快速崛起。
国产非GPU企业的异军突起,正与国内大模型产业形成合力,为本土AI算力生态注入全新活力。尽管非GPU技术路线在生态成熟度上相比GPU仍有距离,但其与AI应用落地高度契合的天然优势,正驱动其迸发出强大的生命力,推动全球算力产业进入一个多元共生、协同创新的新时代。
 发表于 2025-12-20 04:05:22
|
查看: 309|
回复: 0
发表于 2025-12-20 04:05:22
|
查看: 309|
回复: 0
