在基于 Kafka 构建的大型分布式系统中,消费积压是常见的性能瓶颈。当发现消费延迟时,遵循一套清晰的排查思路至关重要:先确认积压现象,再定位性能瓶颈(生产端、消费端、Broker端),最后制定针对性的缓解与优化方案。
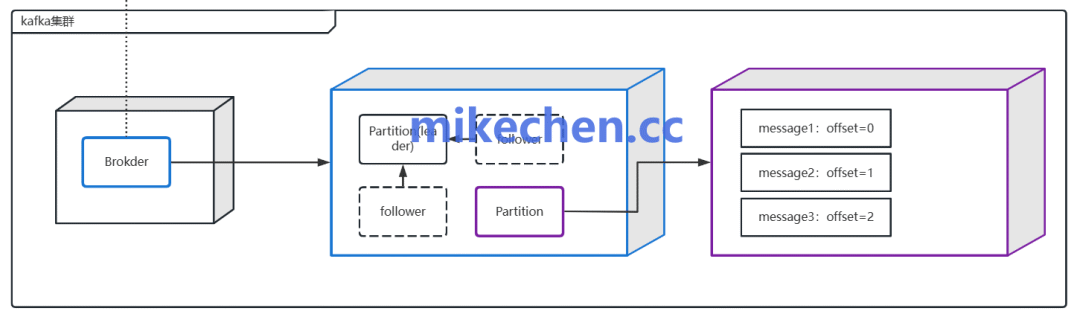
1. 确认积压现象
首先需要确认为真正的持续性积压,而非瞬时抖动。通过 Kafka 内置命令或监控系统,查看消费者组的 Lag(滞后值)。
使用以下命令查看指定消费者组的详情:
kafka-consumer-groups.sh \
--bootstrap-server broker:9092 \
--group your-group \
--describe
关注输出中的 LOG-END-OFFSET(日志末端偏移量)与 CURRENT-OFFSET(消费者当前偏移量),其差值即为 Lag。需要观察 Lag 是否持续增长。
关键判断点:
- 影响范围:积压是集中在少数分区还是所有分区?
- 隔离性:是仅影响某一个消费者组,还是全局性问题?这有助于区分是应用层问题还是底层数据库与中间件(如Kafka集群本身)的网络或故障。
2. 定位性能瓶颈:生产快 vs 消费慢
接下来需明确瓶颈方向。对比生产端的写入TPS(每秒事务数)与消费端的处理TPS。
- 如果生产TPS远大于消费TPS,且消费者实例的CPU、内存等资源利用率不高,那么问题很可能在消费端。
- 检查消费端状态:观察消费者组是否存在频繁的 Rebalance、消费者进程异常退出或重启等现象,这些都会导致消费暂停,加剧积压。
3. 深入排查消费端瓶颈
消费端处理慢是积压最常见的原因。主要瓶颈点通常出现在业务逻辑中。
常见慢处理场景:
- 同步外部调用:如同步RPC或HTTP请求,其耗时不可控,极易阻塞消费线程。
- 同步数据库写入:每条消息都触发一次同步DB写入,尤其是涉及行锁竞争时,性能急剧下降。
- 复杂的序列化/反序列化:处理大型或结构复杂的消息体时,JSON解析等操作可能成为CPU热点。
- 不当的本地锁竞争:消费者内部业务逻辑存在粗粒度锁,导致并行度降低。
排查方法:
- 埋点打印:在消息处理逻辑的首尾记录时间戳,计算单条消息处理耗时。
- 观察消费周期:监控从
poll() 拉取消息到 commit() 提交偏移量之间的平均时间。
4. 集群与架构层面排查
如果消费端单机处理能力已优化至极致,则需从集群和资源配置角度审视。
分区数与消费者数不匹配:
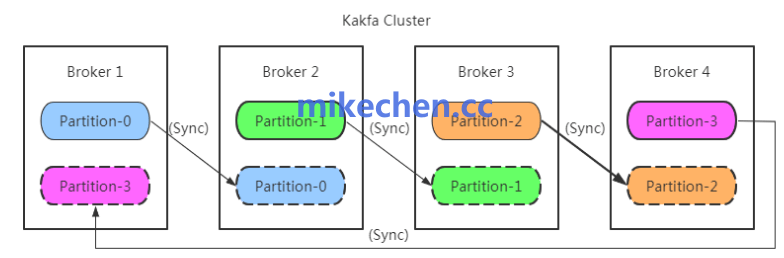
一个分区的数据只能被同一个消费者组内的一个消费者实例消费。如果 Topic 的分区数过少,即使增加消费者实例数量,也无法提升消费并行度,会遇到并发上限。
- 解决方案:考虑对 Topic 进行分区扩容(注意顺序性问题),或创建新的临时 Topic 进行数据分流。
Broker端瓶颈:
检查 Kafka Broker 集群本身是否健康:
- 磁盘I/O:是否达到瓶颈,导致读写变慢。
- 网络吞吐:网络带宽是否成为瓶颈。
- 控制器选举:频繁的控制器选举会影响集群稳定性。
- 配额限制:是否启用了生产或消费配额,限制住了流速。
Broker端的问题常表现为:消费者即使处于空闲状态,每次 poll() 拉取到的数据量也远小于配置的 max.poll.records。
总结与优化思路
处理 Kafka 消费积压是一个系统工程。核心思路是“监控定位 -> 逐层剖析 -> 对症下药”。从最上层的业务逻辑代码审查开始,逐步深入到消费者客户端配置、中间件集群状态与资源规划。建立完善的监控与运维体系,才能在高并发场景下做到快速响应与根治优化。 |  发表于 2025-12-23 22:59:56
|
查看: 244|
回复: 0
发表于 2025-12-23 22:59:56
|
查看: 244|
回复: 0
