你是否在寻找一种无需编写代码,就能将业务系统的告警或事件从Kafka实时推送到飞书群聊的方法?本文将手把手带你完成整个流程的搭建,涵盖从创建飞书机器人、配置Kafka到编写SeaTunnel流水线的完整步骤,并附上关键的避坑指南。
一、飞书端:创建消息接收机器人
1. 创建群组
首先,使用飞书PC客户端,点击主界面的“+”号,选择“创建群组”。建议创建一个“专有对话”模式的群聊,这样便于后续的测试和管理。
2. 添加并获取Webhook机器人
进入刚创建的群聊,点击群图标进入设置。
- 选择“群机器人”页签,点击“添加机器人”。
- 找到“自定义机器人”,为其设置一个名称、头像和描述,然后确认添加。
关键一步:机器人添加成功后,系统会立即生成一个唯一的Webhook URL。请务必妥善保管此URL,因为任何人获得它都可以向该群发送消息,存在泄露风险。
3. 使用工具测试Webhook
我们可以先用API调试工具(如Postman)测试一下这个地址是否可用,确保后续步骤的基础是稳固的。
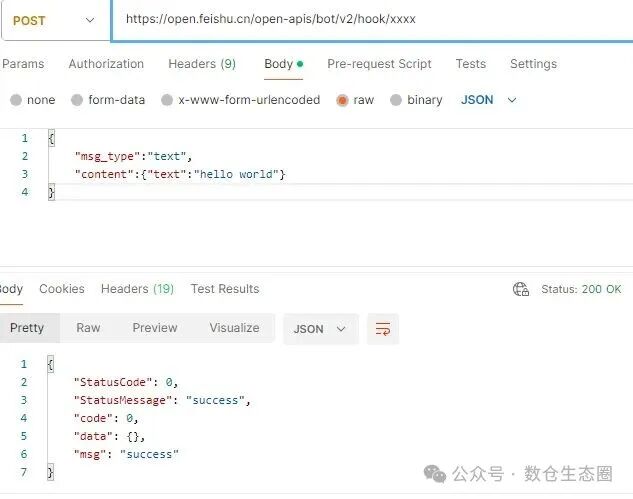
如图所示,向该URL发送一个简单的JSON请求体 {"msg_type":"text","content":{"text":"hello world"}},若返回状态码为200,则表示机器人配置成功。
二、数据源端:Kafka环境配置
1. Kafka服务器配置
确保你的Kafka服务器(例如,一个单节点或集群)配置正确。核心在于 server.properties 文件中的 advertised.listeners 参数,必须设置为能让外部客户端(即稍后要使用的SeaTunnel)访问到的地址。
listeners=PLAINTEXT://10.0.20.205:9092,CONTROLLER://:9093
advertised.listeners=PLAINTEXT://10.0.20.205:9092,CONTROLLER://localhost:9093
2. 准备测试主题与数据
创建一个主题,用于后续的流程测试。
# 创建一个名为 feishutest 的主题
bin/kafka-topics.sh --create --topic feishutest --bootstrap-server 10.0.20.205:9092 --partitions 1 --replication-factor 1
三、连接器:SeaTunnel环境准备
核心步骤是安装连接Kafka和飞书所需的插件。
1. 编辑插件配置文件
编辑 SeaTunnel 安装目录下的 config/plugin_config 文件,在文件末尾添加以下两行:
connector-kafka
connector-http-feishu
2. 运行安装脚本
执行安装脚本,自动下载并安装上述插件。
sh bin/install-plugin.sh
备选方案(网络不佳时):如果在线安装失败,可以访问 Maven 中央仓库(如 https://repo.maven.apache.org/maven2/org/apache/seatunnel/),手动下载对应版本的 connector-kafka 和 connector-http-feishu 的 JAR 包,然后放入 SeaTunnel 的 connectors 目录下。
四、任务配置:编写数据传输流水线
现在我们来定义数据从Kafka流向飞书的具体规则。在 SeaTunnel 的 job 目录下创建一个名为 kafka_feishu.conf 的配置文件,内容如下:
env {
parallelism = 1
job.mode = "STREAMING"
checkpoint.interval = 10000
}
source {
Kafka {
schema = {
fields {
msg_type = string
content = {
text = string
}
}
}
topic = "feishutest"
bootstrap.servers = "10.0.20.205:9092"
kafka.config = {
client.id = "client_1"
max.poll.records = 500
auto.offset.reset = "earliest"
enable.auto.commit = "true"
}
}
}
sink {
Feishu {
url = "https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxx" # 替换成你的真实Webhook地址
}
}
配置精读:请注意schema部分的定义,它必须与你将要写入Kafka的消息JSON结构完全匹配,这是整个链路能否成功连接的关键。此方案利用了 SeaTunnel 强大的连接器生态,实现了从消息队列到应用的无缝集成。
五、启动与验证:开启实时数据流
1. 启动SeaTunnel任务
在命令行中,执行以下命令启动实时同步任务。
bin/seatunnel.sh --config job/kafka_feishu.conf -m local
2. 向Kafka发送测试消息
打开另一个终端,使用Kafka生产者发送一条符合飞书消息格式的JSON数据。
bin/kafka-console-producer.sh --bootstrap-server 10.0.20.205:9092 --topic feishutest
>{"msg_type":"text","content":{"text":"hello world"}}
发送成功后,几秒钟内,你之前创建的飞书群聊中就会弹出一条来自机器人的消息。
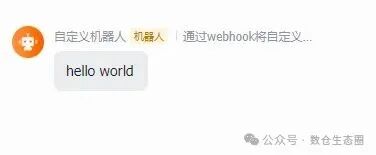
六、核心避坑与拓展思考
第一,格式必须严格对应!
这是最容易出错的地方。Kafka中存储的消息体结构,必须和配置文件中的schema定义保持完全一致。例如,如果你的消息是 {"msg_type":"text","content":{"text":"消息内容"}},那么schema就必须按如下方式定义:
schema = {
fields {
msg_type = string
content = {
text = string
}
}
}
第二,Webhook URL必须保密!
再次强调,你的飞书Webhook URL等同于向群聊发送消息的“万能钥匙”,务必将其视为敏感信息进行管理,避免泄露。
第三,方案的本质与拓展
这个方案的核心原理,是SeaTunnel作为流处理引擎消费Kafka中的JSON数据,然后将其作为HTTP POST请求体,原封不动地转发给飞书机器人的Webhook地址。这意味着,任何能够将数据写入Kafka的系统或应用程序(例如业务后台、监控系统、日志采集器等),现在都能轻松地将关键信息实时推送到指定的飞书群聊中,实现高效的协同与告警。
至此,一条从数据源(Kafka)到通知端(飞书群聊)的、零代码、低延迟的自动化消息管道就成功搭建起来了。如果你在实践过程中遇到了其他问题,或者有更巧妙的用法,欢迎到云栈社区与更多的开发者交流探讨。
 发表于 2026-2-9 10:29:03
|
查看: 235|
回复: 0
发表于 2026-2-9 10:29:03
|
查看: 235|
回复: 0
